
本文介绍如何启用 MLflow 跟踪以连接用作 MLflow 试验后端的 Azure 机器学习。
MLflow 是一个开放源代码库,用于管理机器学习试验的生命周期。 MLFlow 跟踪是 MLflow 的一个组件,可以记录和跟踪训练运行指标和模型项目,而不管试验环境是位于本地计算机、远程计算目标、虚拟机还是 Azure Databricks 群集上。
有关所有受支持的 MLflow 和 Azure 机器学习功能,包括 MLflow 项目支持(预览版)和模型部署,请参阅 MLflow 和 Azure 机器学习。
提示
若要跟踪在 Azure Databricks 或 Azure Synapse Analytics 上运行的试验,请参阅专门的文章:使用 MLflow 和 Azure 机器学习跟踪 Azure Databricks ML 试验。
备注
本文档中的信息主要面向需要监视模型训练过程的数据科学家与开发人员。 如果你是一名管理员,希望监视 Azure 机器学习的资源使用情况和事件,例如配额、已完成的训练作业或已完成的模型部署,请参阅监视 Azure 机器学习。
先决条件
安装
mlflow包。- 可以使用 MLflow Skinny,它是一个不带 SQL 存储、服务器、UI 或数据科学依赖项的轻型 MLflow 包。 对于主要需要用到跟踪和日志记录功能,但不需要导入整个 MLflow 功能套件(包括部署)的用户,建议使用此客户端。
安装
azureml-mlflow包。安装并设置 Azure 机器学习 CLI (v1),并确保安装 ml 扩展。
重要
本文中的一些 Azure CLI 命令使用适用于 Azure 机器学习的
azure-cli-ml或 v1 扩展。 对 v1 扩展的支持将于 2025 年 9 月 30 日结束。 在该日期之前,你将能够安装和使用 v1 扩展。建议在 2025 年 9 月 30 日之前转换为
ml或 v2 扩展。 有关 v2 扩展的详细信息,请参阅 Azure ML CLI 扩展和 Python SDK v2。
从本地计算机或远程计算跟踪运行
通过在 Azure 机器学习中使用 MLflow 进行跟踪,可将在本地计算机上执行的记录的指标和项目运行存储到 Azure 机器学习工作区中。
设置跟踪环境
若要跟踪不是在 Azure 机器学习计算(从现在起称为“本地计算”)上执行的运行,需要将本地计算指向 Azure 机器学习 MLflow 跟踪 URI。
注意
在 Azure 计算(Azure 计算实例或计算群集上托管的 Azure Notebooks、Jupyter Notebook)上运行时,无需配置跟踪 URI。 它将自动进行配置。
可以使用适用于 Python 的 Azure 机器学习 SDK v1 获取 Azure 机器学习 MLflow 跟踪 URI。 确保在使用的群集中安装了库 azureml-sdk。 以下示例获取与工作区关联的唯一 MLFLow 跟踪 URI。 然后,set_tracking_uri() 方法将 MLflow 跟踪 URI 指向该 URI。
使用工作区配置文件:
from azureml.core import Workspace import mlflow ws = Workspace.from_config() mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())使用订阅 ID、资源组名称和工作区名称:
from azureml.core import Workspace import mlflow #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace_name = '<AZUREML_WORKSPACE_NAME>' ws = Workspace.get(name=workspace_name, subscription_id=subscription_id, resource_group=resource_group) mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
设置试验名称
所有 MLflow 运行都会记录到活动试验中。 默认情况下,运行将记录到系统自动创建的名为 Default 的试验中。 若要配置你想要处理的试验,请使用 MLflow 命令 mlflow.set_experiment()。
experiment_name = 'experiment_with_mlflow'
mlflow.set_experiment(experiment_name)
提示
使用 Azure 机器学习 SDK 提交作业时,可以使用属性 experiment_name 设置试验名称。 不必在训练脚本上进行配置。
启动训练运行
设置 MLflow 试验名称后,可以使用 start_run() 启动训练运行。 然后使用 log_metric() 激活 MLflow 记录 API 并开始记录训练运行指标。
import os
from random import random
with mlflow.start_run() as mlflow_run:
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
有关如何使用 MLflow 记录运行中的指标、参数和项目的详细信息,请查看如何记录和查看指标。
跟踪 Azure 机器学习中运行的作业
使用远程运行(作业)能够以重复方式更可靠地训练模型。 远程运行还可利用更强大的计算,例如机器学习计算群集。 请参阅使用计算目标进行模型训练,了解不同的计算选项。
提交作业时,Azure 机器学习会自动配置 MLflow 以使用运行作业的工作区。 这意味着无需配置 MLflow 跟踪 URI。 除此之外,试验将根据试验提交的详细信息自动命名。
重要
将训练作业提交到 Azure 机器学习时,无需在训练逻辑中配置 MLflow 跟踪 URI,因为它已由系统配置。 你也不需要在训练例程中配置试验名称。
创建训练例程
首先,你应创建一个 src 子目录,并在 src 子目录的 train.py 文件中创建一个包含训练代码的文件。 所有训练代码(包括 train.py)都将进入 src 子目录。
训练代码取自 Azure 机器学习示例存储库中的这个 MLflow 示例。
将以下代码复制到文件中:
# imports
import os
import mlflow
from random import random
# define functions
def main():
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
# run functions
if __name__ == "__main__":
# run main function
main()
配置试验
你将需要使用 Python 将试验提交到 Azure 机器学习。 在笔记本或 Python 文件中,使用 Environment 类配置计算和训练运行环境。
from azureml.core import Environment
from azureml.core.conda_dependencies import CondaDependencies
env = Environment(name="mlflow-env")
# Specify conda dependencies with scikit-learn and temporary pointers to mlflow extensions
cd = CondaDependencies.create(
conda_packages=["scikit-learn", "matplotlib"],
pip_packages=["azureml-mlflow", "pandas", "numpy"]
)
env.python.conda_dependencies = cd
然后,将远程计算作为计算目标构造 ScriptRunConfig。
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(source_directory="src",
script=training_script,
compute_target="<COMPUTE_NAME>",
environment=env)
在具有此计算和训练运行配置的情况下,使用 Experiment.submit() 方法提交运行。 此方法会自动设置 MLflow 跟踪 URI 并将记录从 MLflow 定向到工作区。
from azureml.core import Experiment
from azureml.core import Workspace
ws = Workspace.from_config()
experiment_name = "experiment_with_mlflow"
exp = Experiment(workspace=ws, name=experiment_name)
run = exp.submit(src)
查看工作区中的指标和项目
在工作区中跟踪 MLflow 日志记录中的指标和项目。 若要随时查看它们,请在 Azure 机器学习工作室中导航到你的工作区,并在该工作区中按名称找到试验。 或运行以下代码。
使用 MLflow get_run() 检索运行指标。
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
run_id = mlflow_run.info.run_id
finished_mlflow_run = MlflowClient().get_run(run_id)
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
print(metrics,tags,params)
若要查看运行的项目,可以使用 MlFlowClient.list_artifacts()
client.list_artifacts(run_id)
要将项目下载到当前目录,可以使用 MLFlowClient.download_artifacts()
client.download_artifacts(run_id, "helloworld.txt", ".")
若要详细了解如何使用 MLflow 在 Azure 机器学习中检索试验和运行的信息,请查看使用 MLflow 管理试验和运行。
比较和查询
使用以下代码比较和查询 Azure 机器学习工作区中的所有 MLflow 运行。 详细了解如何使用 MLflow 查询运行。
from mlflow.entities import ViewType
all_experiments = [exp.experiment_id for exp in MlflowClient().list_experiments()]
query = "metrics.hello_metric > 0"
runs = mlflow.search_runs(experiment_ids=all_experiments, filter_string=query, run_view_type=ViewType.ALL)
runs.head(10)
自动日志记录
使用 Azure 机器学习和 MLFlow,用户可以在训练模型时自动记录指标、模型参数和模型项目。 支持多种常见的机器学习库。
若要启用自动日志记录,请在训练代码之前插入以下代码:
mlflow.autolog()
管理模型
使用支持 MLflow 模型注册表的 Azure 机器学习模型注册表注册和跟踪模型。 Azure 机器学习模型与 MLflow 模型架构一致,从而可以轻松地在不同的工作流之间导出和导入这些模型。 与 MLflow 相关的元数据(如运行 ID)还使用注册的模型进行跟踪,以实现可追溯性。 用户可以提交训练运行、注册和部署 MLflow 运行生成的模型。
如果要一步部署和注册生产就绪模型,请参阅部署和注册 MLflow 模型。
若要注册并查看运行中的模型,请执行以下步骤:
运行完成后,调用
register_model()方法。# the model folder produced from a run is registered. This includes the MLmodel file, model.pkl and the conda.yaml. model_path = "model" model_uri = 'runs:/{}/{}'.format(run_id, model_path) mlflow.register_model(model_uri,"registered_model_name")使用 Azure 机器学习工作室查看工作区中的已注册模型。
在以下示例中,已注册的模型
my-model标记了 MLflow 跟踪元数据。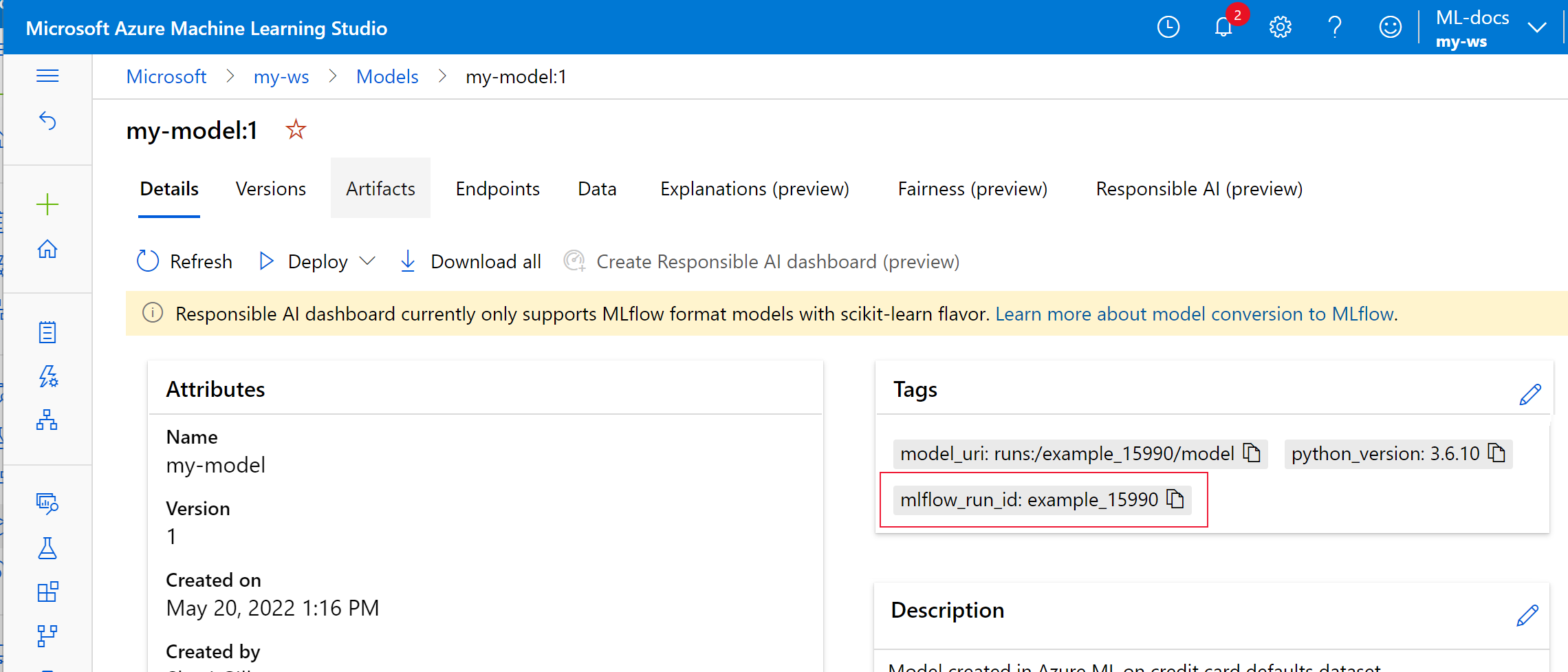
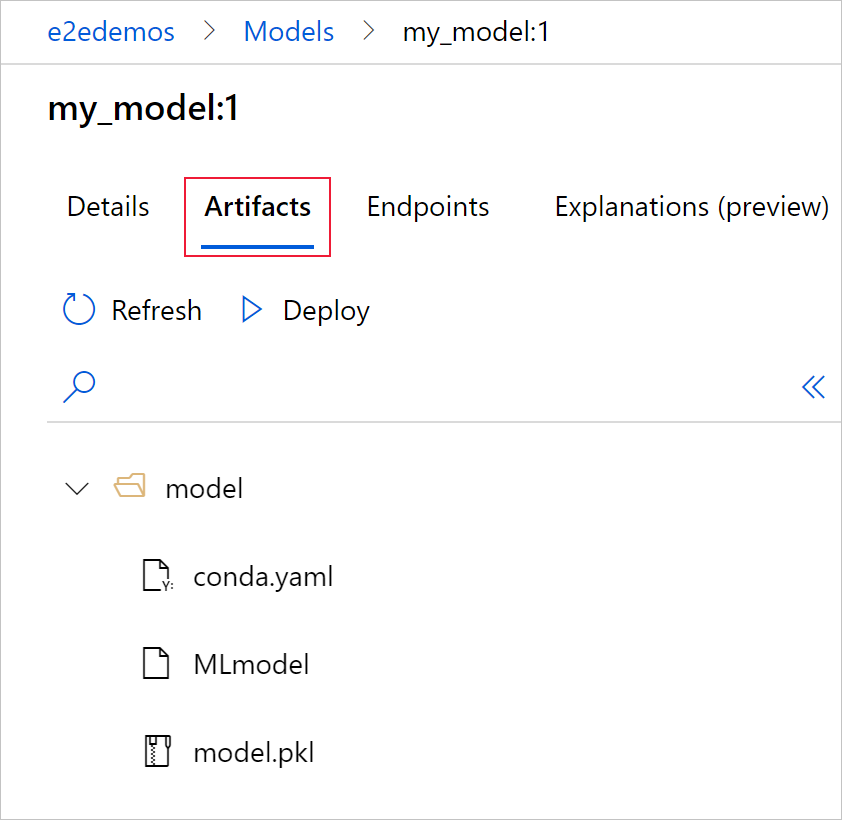
选择“项目”选项卡以查看与 MLflow 模型架构(conda.yaml、MLmodel 和 model.pkl)一致的所有模型文件。
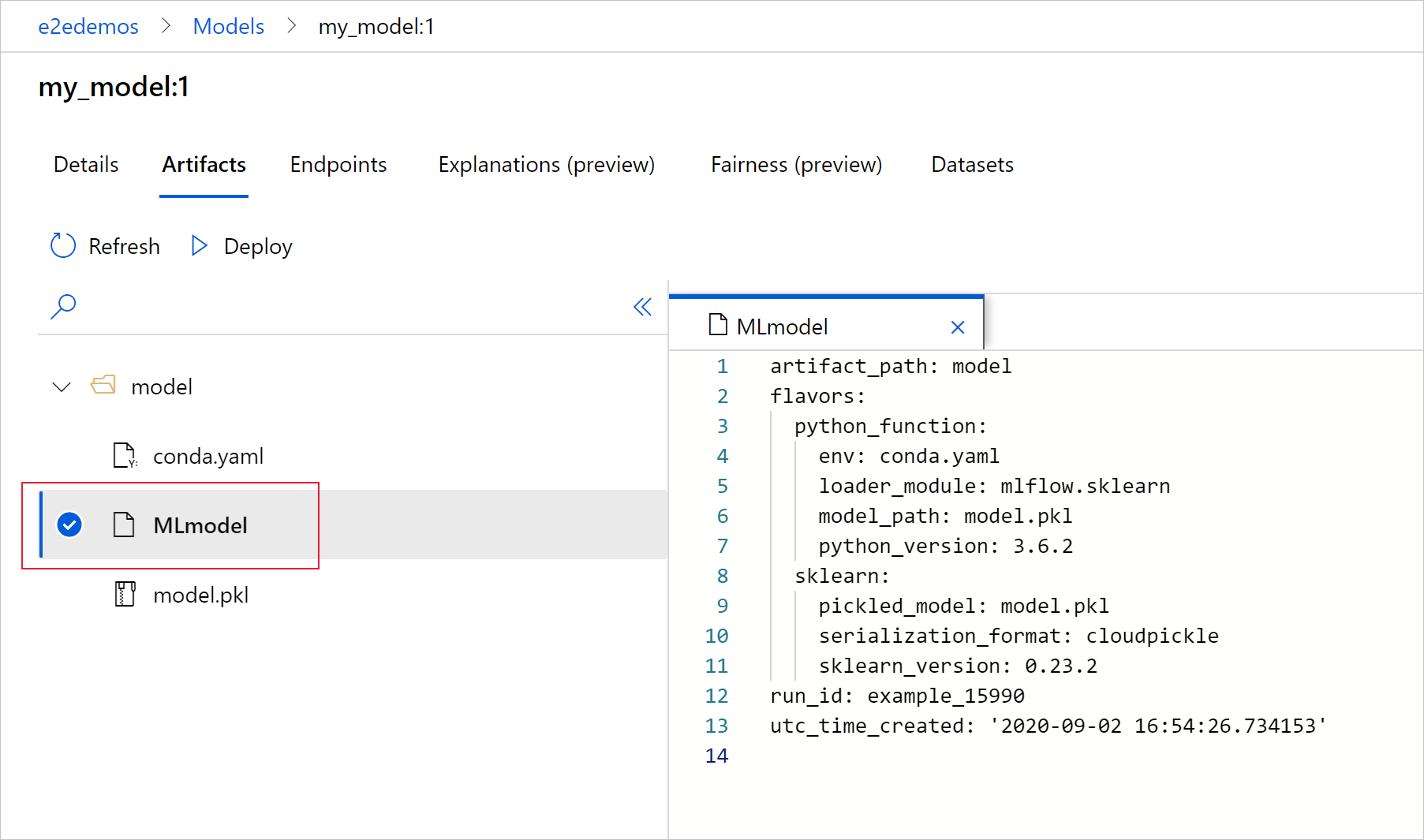
选择 MLmodel 以查看运行生成的 MLmodel 文件。
清理资源
如果不打算使用工作区中记录的指标和项目,目前尚未提供单独删除它们的功能。 可以改为删除包含存储帐户和工作区的资源组,这样就不会产生任何费用:
在 Azure 门户中,选择最左侧的“资源组”。

从列表中选择已创建的资源组。
选择“删除资源组”。
输入资源组名称。 然后选择“删除”。
示例笔记本
将 MLflow 与 Azure 机器学习笔记本配合使用演示了本文中所述的概念,并在这些概念的基础上有所延伸。 另请参阅由社区主导的存储库 AzureML - 示例。
后续步骤
- 使用 MLflow 部署模型。
- 监视生产模型中的数据偏移。
- 使用 MLflow 跟踪 Azure Databricks 运行。
- 管理模型。