数据迁移是将 MySQL 数据库从本地环境转换到 Azure Database for MySQL 的一个极其重要的方面。 本文旨在深入探讨数据迁移的复杂情况,提供了有关各种技术和最佳做法的全面指南,确保无缝实现数据传输。 了解不同的数据迁移方法(例如逻辑迁移和物理迁移),解决数据完整性和停机等潜在挑战,才能有效地规划和执行迁移策略。 本指南旨在提供处理大型数据集、尽力减少中断以及使用 Azure 可靠的功能来优化数据库性能和可靠性所需的知识。 无论是为了实现基础结构现代化还是增强数据管理功能,本文都会提供成功实现数据迁移所需的见解。
先决条件
将本地 MySQL 迁移到 Azure Database for MySQL:性能基线
备份数据库
作为升级或迁移数据之前的谨慎步骤,请在升级前使用 MySQL Workbench 或通过 mysqldump 命令手动导出数据库。
脱机与联机
在选择迁移工具之前,应确定迁移是联机还是脱机。
脱机迁移会导致系统在迁移发生时关闭。 此选项可确保不会发生任何事务,并且数据的状态将与在 Azure 中还原时的预期完全一致。
联机迁移会准实时迁移数据。 当使用数据工作负荷的用户或应用程序的故障时间很短时,此选项非常合适。 此过程涉及使用复制方法(例如
binlog或类似方法)复制数据。
对于 WWI,其环境有一些复杂的网络和安全要求,不允许在目标迁移期限内对入站和出站连接应用适当的更改。 由于这些复杂性和要求,导致基本上不用考虑联机方法。
注意
有关脱机和联机迁移的更多详细信息,请查看“规划”和“评估”部分。
数据偏移
脱机迁移策略可能会产生数据偏移。 当新修改的源数据与迁移的数据不同步时,会发生数据偏移。 发生这种情况时,需要完全导出或增量导出。 可以通过停止所有到数据库的流量,然后执行导出来缓解此问题。 如果无法停止所有数据修改流量,则需要考虑偏移。
如果数据库表在每个需要迁移的表中没有基于数字的主键之类的列或某种类型的修改日期和创建日期,则确定更改可能会变得复杂。
例如,如果存在基于数字的主键并且迁移按排序顺序导入,则确定导入停止位置并从该位置重启导入会相对简单。 如果没有基于数字的键,则可以使用修改和创建日期,并再次按排序方式导入,以便能够从目标中显示的最后一个日期重启迁移。
性能建议
导出
使用可以在多线程模式中运行的导出工具(如 mydumper)
使用 MySQL 8.0 时,请在适当的时候使用已分区表以提高导出速度。
导入
加载数据后创建聚集索引和主键。 按主键顺序加载数据,如果主键是某个日期列(例如修改日期或创建日期),则按排序顺序加载。
延迟创建辅助索引,直到数据加载完毕之后。 加载后创建所有辅助索引。
加载前禁用外键约束。 禁用外键检查可以显著提高性能。 启用约束并在加载后验证数据,确保引用完整性。
并行加载数据。 避免太多的并行性,否则可能会导致资源争用,并且使用 Azure 门户中提供的指标来监视资源。
执行迁移
备份数据库
创建和验证 Azure 登陆区域
配置源服务器参数
配置目标服务器参数
导出数据库对象(架构、用户等)
导出数据
导入数据库对象
导入数据
验证
重置目标服务器参数
迁移一个或多个应用程序
一般步骤
不管采用哪种路径,都必须执行一些常见步骤:
升级到受支持的 Azure MySQL 版本
库存数据库对象
导出用户和权限
迁移到最新 MySQL 版本
由于 WWI 会议数据库正在运行 5.5,因此需要执行升级。 CIO 要求升级到最新版本的 MySQL(当前为 8.0)。
可以通过两种方法升级到 8.0:
就地
导出/导入
决定进行升级时,务必要运行升级检查器工具来确定是否存在任何冲突。 例如,在升级到 MySQL Server 8.0 时,该工具将检查是否存在以下冲突:
与 MySQL 8.0 中的保留字冲突的数据库对象名称
utf8mb3 字符集的使用
ZEROFILL/显示长度类型属性的使用
与 8.0 中的表冲突的表名
时态类型的使用
外键约束名称长度超过 64 个字符
如果升级检查器报告没有问题,则可以通过替换 MySQL 二进制文件来安全地执行就地升级。 需要导出有问题的数据库并解决问题。
WWI 方案
成功将 MySQL 实例迁移到 8.0 后,WWI 迁移团队意识到原来的将本地 MySQL 迁移到 Azure Database for MySQL 迁移路径无法再使用,因为 DMS 工具当前仅支持 5.6 和 5.7。 DMS 需要网络访问。 WWI 迁移团队尚未准备好处理复杂的网络问题。 这些环境问题将其迁移工具选择范围缩小到 MySQL Workbench。
数据库对象
如“测试计划”部分中所述,在迁移之前和之后应完成数据库对象盘存,以确保迁移所有内容。
若要执行存储过程以生成此信息,可以使用类似于下面的内容:
DELIMITER //
CREATE PROCEDURE `Migration_PerformInventory`(IN schemaName CHAR(64))
BEGIN
DECLARE finished INTEGER DEFAULT 0;
DECLARE tableName varchar(100) DEFAULT "";
#get all tables
DECLARE curTableNames
CURSOR FOR
SELECT TABLE_NAME FROM information_schema.tables where TABL
E_SCHEMA = schemaName;
-- declare NOT FOUND handler
DECLARE CONTINUE HANDLER
FOR NOT FOUND SET finished = 1;
DROP TABLE IF EXISTS MIG_INVENTORY;
CREATE TABLE MIG_INVENTORY
(
REPORT_TYPE VARCHAR(1000),
OBJECT_NAME VARCHAR(1000),
PARENT_OBJECT_NAME VARCHAR (1000),
OBJECT_TYPE VARCHAR(1000),
COUNT INT
)
ROW_FORMAT=DYNAMIC,
ENGINE='InnoDB';
INSERT INTO MIG_INVENTORY (REPORT_TYPE,OBJECT_NAME, OBJECT_TYPE, COUNT)
SELECT
'OBJECTCOUNT', 'TABLES', 'TABLES', COUNT(*)
FROM
information_schema.tables
where
TABLE_SCHEMA = schemaName;
#### Constraints
INSERT INTO MIG_INVENTORY (REPORT_TYPE,OBJECT_NAME, OBJECT_TYPE, COUNT)
SELECT
'OBJECTCOUNT', 'STATISTICS', 'STATISTICS', COUNT(*)
FROM
information_schema.STATISTICS
WHERE
TABLE_SCHEMA = schemaName;
INSERT INTO MIG_INVENTORY (REPORT_TYPE,OBJECT_NAME, OBJECT_TYPE, COUNT)
SELECT
'OBJECTCOUNT', 'VIEWS', 'VIEWS', COUNT(*)
FROM
information_schema.VIEWS
WHERE
ROUTINE_TYPE = 'FUNCTION' and
ROUTINE_SCHEMA = schemaName;
INSERT INTO MIG_INVENTORY (REPORT_TYPE,OBJECT_NAME, OBJECT_TYPE, COUNT)
SELECT
'OBJECTCOUNT', 'PROCEDURES', 'PROCEDURES', COUNT(*)
FROM
information_schema.ROUTINES
WHERE
ROUTINE_TYPE = 'PROCEDURE' and
ROUTINE_SCHEMA = schemaName;
INSERT INTO MIG_INVENTORY (REPORT_TYPE,OBJECT_NAME, OBJECT_TYPE, COUNT)
SELECT
'OBJECTCOUNT', 'EVENTS', 'EVENTS', COUNT(*)
FROM
information_schema.EVENTS
WHERE
EVENT_SCHEMA = schemaName;
INSERT INTO MIG_INVENTORY (REPORT_TYPE,OBJECT_NAME, OBJECT_TYPE, COUNT)
SELECT
'OBJECTCOUNT', 'USER DEFINED FUNCTIONS', 'USER DEFINED FUNCTIONS'
, COUNT(*)
FROM
mysql.func;
INSERT INTO MIG_INVENTORY (REPORT_TYPE,OBJECT_NAME, OBJECT_TYPE, COUNT)
SELECT
'OBJECTCOUNT', 'USERS', 'USERS', COUNT(*)
FROM
mysql.user
WHERE
user <> '' order by user;
OPEN curTableNames;
getTableName: LOOP
FETCH curTableNames INTO tableName;
IF finished = 1 THEN
LEAVE getTableName;
END IF;
SET @s = CONCAT('SELECT COUNT(*) into @TableCount FROM ', schemaName,
'.', tableName);
#SELECT @s;
PREPARE stmt FROM @s;
EXECUTE stmt;
INSERT INTO MIG_INVENTORY (REPORT_TYPE,OBJECT_NAME, OBJECT_TYPE, COUNT)
SELECT
'TABLECOUNT', tableName, 'TABLECOUNT', @TableCount;
DEALLOCATE PREPARE stmt;
END LOOP getTableName;
CLOSE curTableNames;
SELECT * FROM MIG_INVENTORY;
END //
DELIMITER ;
CALL Migration_PerformInventory('reg_app');
- 在源 DB 上调用此过程将显示以下内容(截断输出):
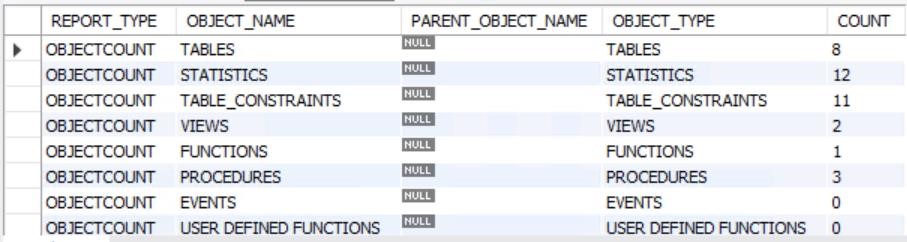
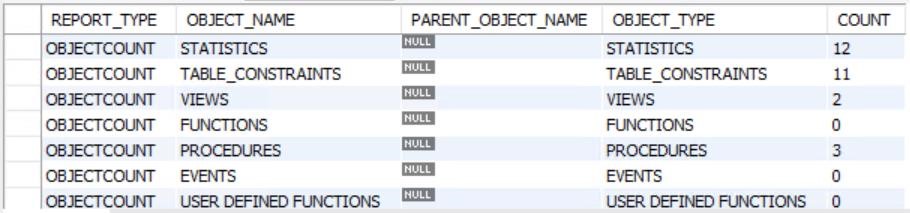
- 完成迁移后,目标数据库过程结果应类似于下图。 请注意,DB 中没有函数。在迁移之前已消除函数。
用户和权限
成功的迁移需要将关联的用户和权限迁移到目标环境。
使用以下 PowerShell 脚本导出所有用户及其授权:
$username = "yourusername";
$password = "yourpassword";
mysql -u$username -p$password --skip-column-names -A -e"SELECT CONCAT('SHOW G
RANTS FOR ''',user,'''@''',host,''';') FROM mysql.user WHERE user<>''" > Show
Grants.sql;
$lines = get-content "ShowGrants.sql"
foreach ($line in $lines)
{
mysql -u$username -p$password --skip-column-names -A -e"$line" >> AllGrants.sql
}
使用 PowerShell ISE 创建新的 PowerShell 脚本(请参阅安装文档)
将“yourusername”设置为根,并将“yourpassword”设置为根用户的密码
然后可以运行面向新 Azure Database for MySQL 的 AllGrants.sql 脚本:
$username = "yourusername";
$password = "yourpassword";
$server = "serverDNSname";
$lines = get-content "AllGrants.sql"
foreach ($line in $lines)
{
mysql -u$username -p$password -h$server --ssl-ca=c:\temp\BaltimoreCyberTrus
tRoot.crt.cer --skip-column-names -A -e"$line"
}
还可以使用 PowerShell 在 Azure Database for MySQL 中创建用户:https://docs.azure.cn/mysql/howto-create-users
执行迁移
在部署了基本的迁移组件后,现在可以继续进行数据迁移。 前面介绍了几种工具和方法。 于是,WWI 决定先利用 MySQL Workbench 路径导出数据,再将数据导入 Azure Database for MySQL。
数据迁移核对清单
了解环境的复杂性,以及联机方法是否可行。
考虑数据偏移。 停止数据库服务可以消除潜在的数据偏移。
配置源参数以快速导出。
配置目标参数以快速导入。
测试任何具有不同源版本与目标版本的迁移。
迁移任何不基于数据的对象,例如用户名和特权。
确保在执行迁移时记录并检查所有任务。