重要
Azure 逻辑应用已替换于 2022 年 1 月 31 日完全停用的 Azure 计划程序。 请按照本文中的步骤,在 Azure 逻辑应用中以工作流的形式重新创建 Azure 计划程序作业,从而对其进行迁移。 Azure 计划程序在 Azure 门户中不再可用。 Azure 计划程序 REST API 和 Azure 计划程序 PowerShell cmdlet 不再工作。
本指南介绍如何通过使用 Azure 逻辑应用而非 Azure 计划程序来创建自动化工作流,从而安排一次性作业和定期作业。 在使用 Azure 逻辑应用创建计划作业时,将获得以下好处:
使用可视化设计器构建作业,并从 Azure Blob 存储、Azure 服务总线、Office 365 Outlook 和 SAP 等 1000 多个现成连接器中进行选择。
将计划的每个工作流作为一级 Azure 资源进行管理。 不必担心作业集合的概念,因为每个逻辑应用都是一个单独的 Azure 资源。
使用单个逻辑应用工作流运行多个一次性作业。
设置支持时区并自动调整为夏令时 (DST) 的计划。
有关详细信息,请参阅什么是 Azure 逻辑应用?或尝试按照以下任一步骤创建第一个逻辑应用工作流:
先决条件
- Azure 帐户和订阅。 如果没有 Azure 订阅,请注册一个 Azure 试用帐户。
安装或使用可发送 HTTP 请求以测试解决方案的工具,例如:
- Visual Studio Code,具有来自 Visual Studio Marketplace 的扩展
- PowerShell Invoke-RestMethod
- Microsoft Edge - 网络控制台工具
- 布鲁诺
- cURL
注意
对于具有敏感数据(例如凭据、机密、访问令牌、API 密钥和其他类似信息)的情况,请务必使用具有必要安全功能可保护数据的工具,该工具可脱机或本地工作,不会将数据同步到云,并且不需要登录联机帐户。 这样可以降低敏感数据被公开的风险。
使用脚本进行迁移
每种计划程序作业具有其独特性,因此不存在通用的工具可以将所有 Azure 计划程序作业迁移到 Azure 逻辑应用。 不过,可以编辑此脚本以满足自己的需求。
安排一次性作业
只需创建一个逻辑应用工作流即可运行多个一次性作业。
在 Azure 门户中,创建逻辑应用资源和空白工作流。
在请求触发器中,可以选择提供 JSON 架构,这有助于工作流设计器了解包含在请求触发器入站调用中的输入的结构,使你稍后在工作流中更易选择输出。
在“请求正文 JSON 架构”框中输入架构,例如:
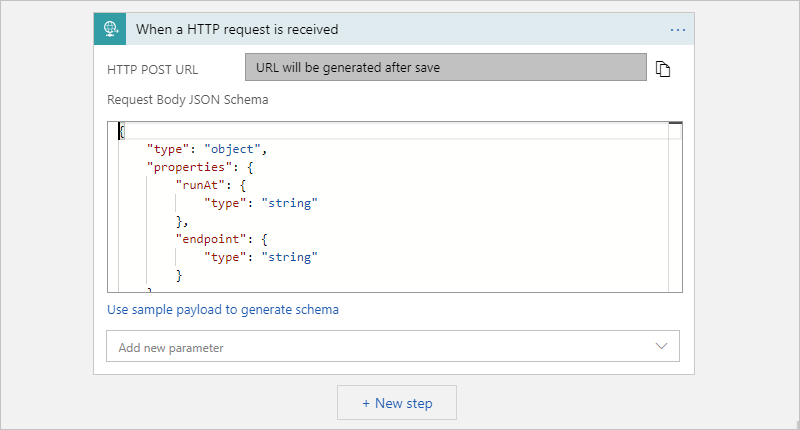
如果你没有架构,但有一个 JSON 格式的示例有效负载,则可以基于该有效负载生成一个架构。
在“请求”触发器中,选择“使用示例有效负载生成架构”。
在“输入或粘贴示例 JSON 有效负载”下,提供示例有效负载并选择“完成”,例如 :
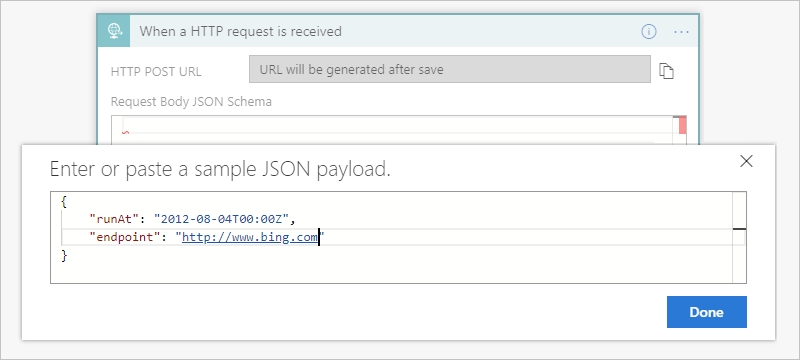
{ "runat": "2012-08-04T00:00Z", "endpoint": "https://www.bing.com" }
-
此操作会将工作流执行暂停到指定的日期和时间,例如:
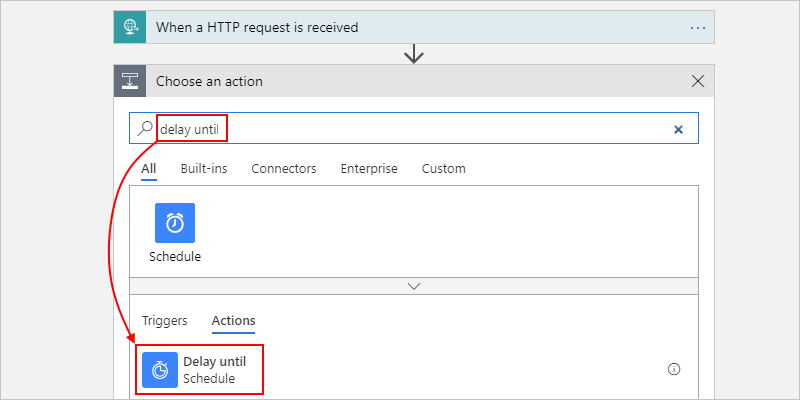
输入要启动工作流的时间戳。
- 在“时间戳”框中选择,然后选择动态内容列表选项(闪电图标),这样就可以选择上一操作中的输出,也就是此示例中的请求触发器。
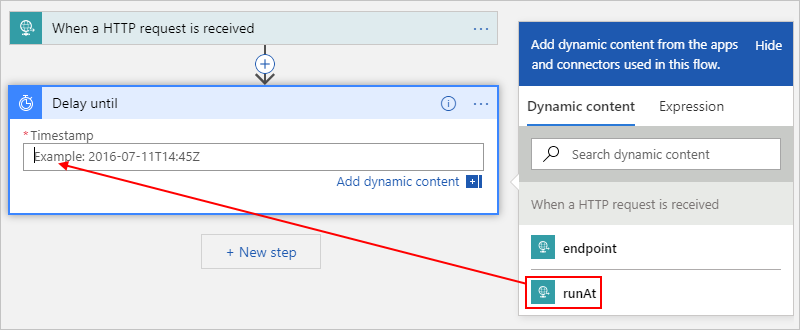
从 1000 多个现成的连接器中进行选择,以添加要运行的任何其他操作。
例如,可以包含向 URL 发送请求的 HTTP 操作,或与存储队列、服务总线队列或服务总线主题一起使用的操作:
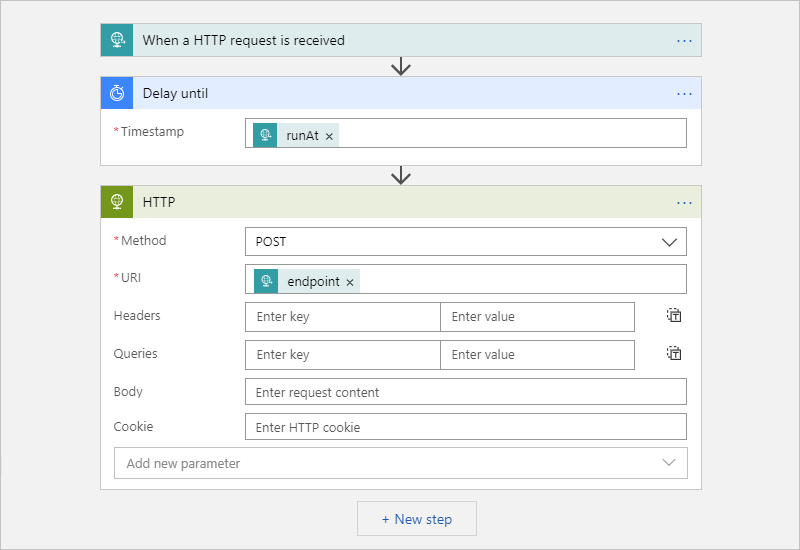
完成后,请在设计器工具栏上选择“保存”。
首次保存工作流时,系统会生成工作流请求触发器的终结点 URL,并将其显示在“HTTP POST URL”框中,例如:
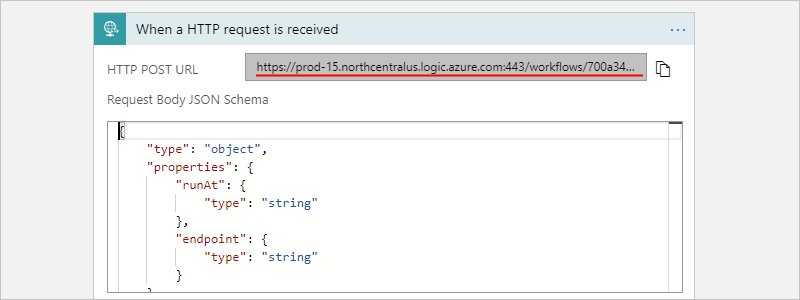
若要使用希望工作流处理的输入手动触发工作流,可以将 HTTP 请求发送到终结点 URL。
复制并保存终结点 URL,以便可以测试工作流。
测试工作流
若要手动触发工作流,请将 HTTP 请求发送到工作流的请求触发器中的终结点 URL。 在此请求中,请添加要发送的输入或有效负载,你可能之前已通过指定架构对其进行了描述。 可以使用 HTTP 请求工具并根据其说明发送此请求。
例如,可以创建并发送使用请求触发器预期方法的 HTTP 请求,例如:
| 请求方法 | 代码 | 身体 | 头文件 |
|---|---|---|---|
| 发布 | <endpoint-URL |
生
JSON(application/json) |
键:Content-Type 值:application/json |
取消一次性作业
在 Azure 逻辑应用中,每个一次性作业均作为单个工作流运行实例执行。 若要手动取消一次性作业,可以找到并复制工作流响应中返回的 x-ms-workflow-run-id 标头值,并根据逻辑应用的情况,使用以下 REST API 将具有此工作流运行 ID 的另一个 HTTP 请求发送到工作流的终结点 URL:
消耗型工作流:工作流运行 - 取消
标准工作流:工作流运行 - 取消
安排重复作业
在 Azure 门户中,创建逻辑应用资源和空白工作流。
如果需要,请设置更高级的计划。
有关高级计划选项的详细信息,请参阅使用 Azure 逻辑应用创建和运行重复任务和工作流。
从 1000 多个现成的连接器中进行选择,以添加要运行的任何其他操作。
例如,可以包含向 URL 发送请求的 HTTP 操作,或与存储队列、服务总线队列或服务总线主题一起使用的操作:
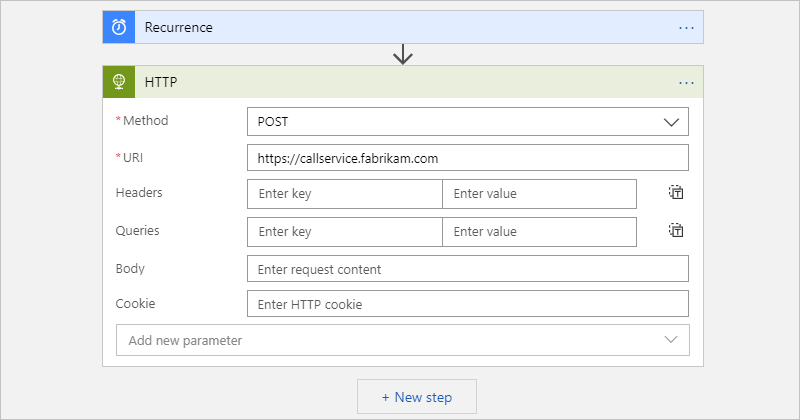
完成后,请在设计器工具栏上选择“保存”。
高级设置
以下各部分介绍了可自定义作业的其他方法。
重试策略
若要控制在出现间歇性失败时操作尝试在工作流中重新运行的方式,可以在每个操作的设置中设置重试策略。
处理异常和错误
在 Azure 计划程序中,如果默认作无法运行,则可以运行解决错误条件的替代作。 在 Azure 逻辑应用中,也可以执行相同的任务。 有关 Azure 逻辑应用中异常处理的详细信息,请参阅处理错误和异常 - RunAfter 属性。
在设计器中,在要处理的操作上方添加并行分支。
查找并选择要作为替代操作运行的操作。
在替代操作中,找到并选择“配置随后运行”选项。
清除“成功”属性的相应框。 选择名为“失败”、“已跳过”和“已超时”的属性。
完成后,选择“完成”。
常见问题解答
问:Azure 计划程序何时停用?
答:Azure 计划程序已在 2022 年 1 月 31 日完全停用。
问:Azure 计划程序停用后,对我的作业集合和作业有何影响?
答:所有 Azure 计划程序作业集合和作业都停止运行,并从系统中删除。
问:在将我的 Azure 计划程序作业迁移到 Azure 逻辑应用之前,是否必须备份或执行任何其他任务?
答:最佳做法是始终备份你的工作。 在删除或禁用 Azure 计划程序作业之前,请检查你创建的工作流是否按预期运行。
问:从 Azure 计划程序计划 Azure Web 作业会发生什么情况?
答:使用这种计划 Web 作业方式的 Web 作业不在内部使用 Azure 计划程序:“要使计划正常运行,需要将网站配置为‘始终可用’,并且不是 Azure 计划程序,而是计划程序的内部实现。”唯一会受到影响的 Web 作业是那些专门使用 Azure 计划程序通过 Web 作业 API 运行 Web 作业的作业。 可以使用 HTTP 操作从逻辑应用工作流触发这些 Web 作业。
问:是否有可以帮助我将作业从 Azure 计划程序迁移到 Azure 逻辑应用的工具?
答:每个 Azure 计划程序作业都是唯一的,因此不存在一个通用的工具。 但是,可以根据需要编辑此脚本,将 Azure 计划程序作业迁移到 Azure 逻辑应用。
问:迁移 Azure 计划程序作业时,可从何处获得支持?
答:以下是获得支持的一些方法:
Azure 门户
如果 Azure 订阅具有付费支持计划,则可以在 Azure 门户中创建技术支持请求。 如果没有,则可以选择其他支持选项。
在 Azure 门户主菜单中,选择“帮助和支持”。
在“支持”菜单中,选择“新建支持请求” 。 提供有关请求的以下信息:
属性 价值 问题类型 技术 订阅 < your-Azure-subscription> 服务 选择“计划程序”。 选择所需的支持选项。 如果有付费支持计划,请选择“下一步”。