重要
注意:根据 世纪互联发布的公告,所有 Microsoft Sentinel 功能将于 2026 年 8 月 18 日 在 Azure 中国区正式停用。
为确保 Microsoft Sentinel 服务中完整且不间断的数据引入,应跟踪数据连接器的运行状况、连接性和性能。
以下功能可用于从 Microsoft Sentinel 中执行此监视:
数据收集运行状况监视工作簿:该工作簿提供额外的监视项,可检测异常,并帮助深入了解工作区的数据引入情况。 可以使用该工作簿的逻辑来监视引入数据的一般运行状况,并生成自定义视图和基于规则的警报。
SentinelHealth 数据表:查询此表可帮助深入了解健康状态漂移,例如每个连接器的最新故障事件,或状态从成功变为失败的连接器,您可以利用这些信息创建警报和其他自动化操作。 SentinelHealth 数据表目前仅支持用于选定的数据连接器。
查看已连接 SAP 系统的运行状况和状态:在 SAP 数据连接器下查看 SAP 系统的运行状况信息,并使用警报规则模板获取有关 SAP 代理数据收集运行状况的信息。
本文介绍如何使用数据收集运行状况监视工作簿和 SentinelHealth 数据表来监视数据连接器运行状况、运行诊断查询以及配置运行状况偏移的自动警报。
使用“运行状况监视”工作簿
若要开始使用,请从内容中心安装“数据收集运行状况监视”工作簿,然后从 Microsoft Sentinel 的“工作簿”部分查看或创建模板的副本。
在 Azure 门户 中,在“内容管理”下,选择“内容中心”。
在内容中心中,在搜索栏中输入“运行状况”,然后从结果中选择“数据收集运行状况监视”。
从详细信息窗格中选择“安装”。 如果看到工作簿已安装的通知消息,或者看到的不是安装,而是配置,请继续执行下一步。
在“Microsoft Sentinel”的“威胁管理”下,选择“工作簿”。
在工作簿页面上,选择模板选项卡,在搜索栏中输入health,然后从结果中选择Data collection health monitoring。
选择“查看模板”以按原样使用工作簿,或选择“保存”以创建工作簿的可编辑副本。 创建复制时,选择“查看保存的工作簿”。
进入工作簿后,首先选择要查看的“订阅”和“工作区”,然后定义 TimeRange 以根据需要筛选数据。 使用 显示帮助 开关可显示工作簿中的内嵌说明。
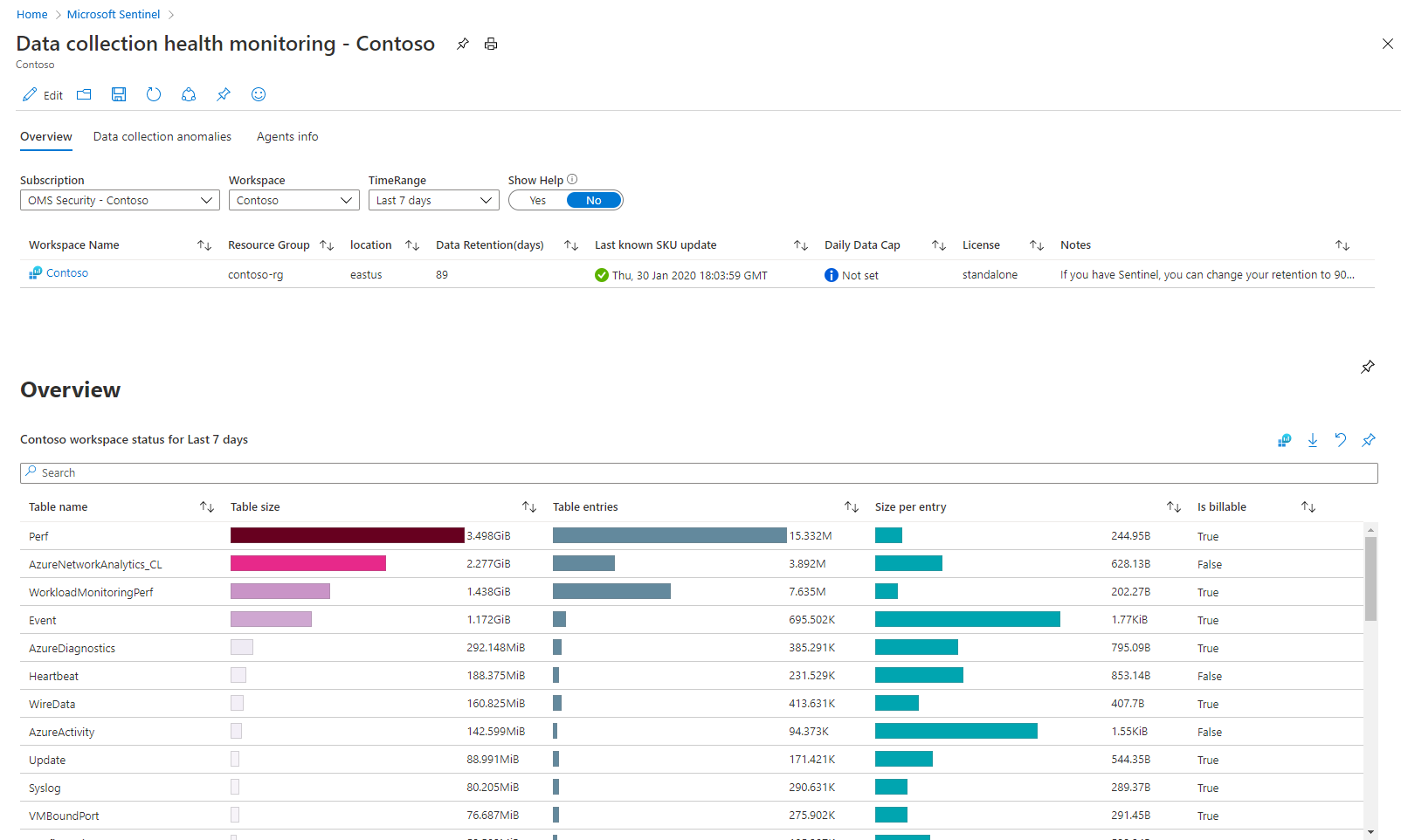

此工作簿中有三个选项卡式部分:
概览选项卡显示所选工作区中数据引入的总体状态:数据量指标、EPS 速率以及上次接收日志的时间。
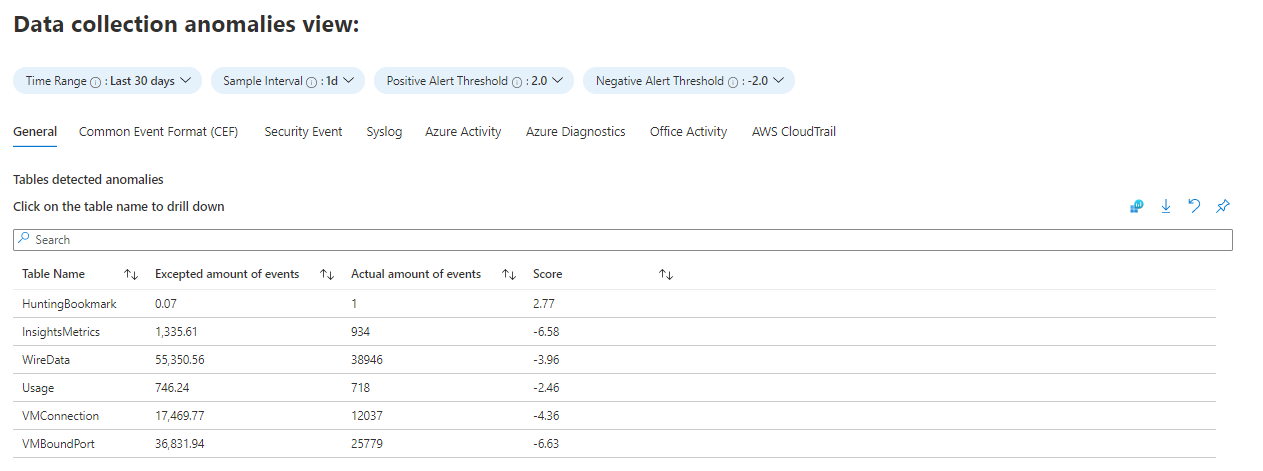
“数据收集异常”选项卡将帮助你按表和数据源检测数据收集过程中的异常。 每个选项卡都显示特定表的异常情况(“常规”选项卡包含表的集合)。 使用 series_decompose_anomalies() 函数计算异常,该函数会返回异常分数。 详细了解 series_decompose_anomalies() 函数。 为要计算的函数设置以下参数:
AnomaliesTimeRange:此时间选取器仅适用于数据收集异常视图。
SampleInterval:给定时间范围内的数据采样时间间隔。 仅对最后一个时段内的数据计算异常分数。
PositiveAlertThreshold:此值定义为正的异常分数阈值。 它接受小数。
NegativeAlertThreshold:此值定义为负的异常分数阈值。 它支持十进制值。
“代理信息”选项卡显示有关安装在各种计算机(无论是 Azure VM、其他云 VM、本地 VM,还是物理计算机)上的代理的运行状况信息。 监控系统所在位置、心跳状态和延迟、可用内存和磁盘空间以及代理运行情况。
在本部分中,必须选择描述计算机环境的选项卡:如果只想查看 Azure Arc 托管的计算机,请选择“Azure 托管的计算机”选项卡;选择“所有计算机”选项卡可查看安装了 Azure Monitor 代理的托管计算机和非 Azure 计算机。



使用 SentinelHealth 数据表
若要从 SentinelHealth 数据表中获取数据连接器运行状况数据,必须先为工作区启用 Microsoft Sentinel 运行状况功能。 有关详细信息,请参阅为 Microsoft Sentinel 启用运行状况监视。
启用运行状况功能后,会在为数据连接器生成的第一个成功或失败事件时创建 SentinelHealth 数据表。
支持的数据连接器
目前仅以下数据连接器支持 SentinelHealth 数据表:
- Office 365
- 威胁情报 - TAXII
了解 SentinelHealth 表事件
以下类型的运行状况事件会记录在 SentinelHealth 表中:
数据获取状态变更。 为了防止重复审计并减小表大小,当数据连接器的状态保持稳定且持续出现成功事件或失败事件时,Microsoft Sentinel 每小时仅记录一次此事件。 如果数据连接器的状态为连续的失败,则有关失败的其他详细信息将包含在 ExtendedProperties 列中。
如果数据连接器的状态从成功变为失败、从失败变为成功,或因故障原因发生更改,则将立即记录该事件,以便贵团队立即采取主动措施。
潜在的暂时性错误(例如源服务节流)仅在持续超过 60 分钟后才会被记录。 Microsoft Sentinel 可利用这 60 分钟解决后端的瞬时性问题并获取数据,无需任何用户操作。 对于非瞬时性错误,将会立即记录。
故障摘要。 每个连接器,每个工作区,每小时记录一次,并生成汇总的失败摘要。 只有当连接器在给定小时内出现轮询错误时,才会创建失败摘要事件。 它们包含 ExtendedProperties 列中提供的其他任何详细信息,例如查询连接器源平台的时间段,以及在该时间段内遇到的故障的完整列表。
有关详细信息,请参阅 SentinelHealth 表列架构。
运行查询,检测运行状况偏移
针对 SentinelHealth 表创建查询,以帮助检测数据连接器中的运行状况偏差。 例如: 。
检测每个连接器的最新失败事件:
SentinelHealth
| where TimeGenerated > ago(3d)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId
| where Status == 'Failure'
检测从失败状态变为成功状态的连接器:
let latestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextTolatestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (latestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
latestStatus
| join kind=inner (nextTolatestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Failure' and LastStatus == 'Success'
检测从成功状态变为失败状态的连接器:
let latestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextTolatestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (latestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
latestStatus
| join kind=inner (nextTolatestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Success' and LastStatus == 'Failure'
请参阅 Kusto 文档中有关 SentinelHealth 运行状况偏移查询中使用的以下 Kusto 运算符和函数的详细信息:
有关 KQL 的更多信息,请参阅 Kusto 查询语言 (KQL) 概述。
其他资源:
针对运行状况问题配置警报和自动操作
尽管你可以使用 Microsoft Sentinel 分析规则在 Microsoft Sentinel 日志中配置自动化,但如果你希望接收关于数据连接器中的运行状况偏移的通知并立即对其采取措施,建议你使用 Azure Monitor 警报规则。
以下步骤演示如何创建使用 SentinelHealth 查询检测数据连接器运行状况偏移的Azure Monitor警报规则:
在 Azure Monitor 警报规则中,选择 Microsoft Sentinel 工作区作为规则范围,选择“自定义日志搜索”作为第一个条件。
根据需要自定义警报逻辑,例如频率或回溯持续时间,然后使用 运行状况偏移检测查询 搜索运行状况偏移。
对于规则操作,选择现有操作组或根据需要新建操作组,以配置推送通知或其他自动化操作,例如触发系统中的逻辑应用、Webhook 或 Azure 函数。
有关详细信息,请参阅 Azure Monitor 警报概述和 Azure Monitor 警报日志。
后续步骤
- 了解 Microsoft Sentinel 中的审核和运行状况监控。
- 在 Microsoft Sentinel 中启用审核和运行状况监控。
- 监控自动化规则和操作手册的健康状况。
- 监视分析规则的运行状况和完整性。
- 请参阅有关 SentinelHealth 和 SentinelAudit 表架构的更多信息。