Azure 流分析不提供自动异地故障转移功能,但你可以通过在多个 Azure 区域中部署相同的流分析作业来实现异地冗余。 每个作业都会连接到本地输入和本地输出源。 应用程序负责将输入数据发送到两个区域输入并在两个区域输出之间进行协调。 流分析作业是两个独立的实体。
下图描绘了具有事件中心输入和 Azure 数据库输出的异地冗余流分析作业部署示例。
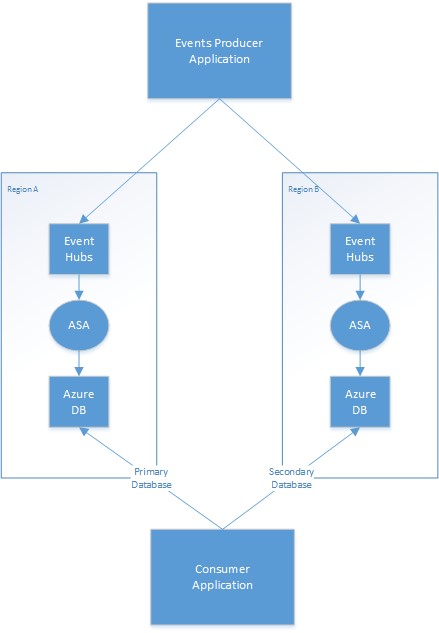
主要/辅助策略
应用程序需要对以下情况进行管理:将哪个区域的输出数据库视为主数据库,将哪个区域的输出数据库视为辅助数据库。 在主要区域发生故障时,应用程序将切换到辅助数据库,并开始从该数据库读取更新。 允许最大限度减少重复读取的实际机制取决于应用程序。 可以通过将其他信息写入输出来简化此过程。 例如,可以向每个输出添加时间戳或序列 ID,这样就可以轻松跳过重复行。 主要区域在恢复后会使用类似的机制跟上辅助数据库的进度。
尽管不同的输入和输出类型允许使用不同的异地复制选项,但是我们建议使用本文所述的模式来实现异地冗余,因为它为事件生产者和事件使用者都提供了灵活性和控制权。