Azure 流分析 支持通过自定义字段或属性和自定义 DateTime 路径模式实现自定义 blob 输出分区。
自定义字段或属性
自定义字段或输入属性通过允许进一步控制输出,改进下游数据处理和报告工作流。
分区键选项
用于对输入数据进行分区的分区键或列名可能包含 Blob 名称所允许的任何字符。 除非将嵌套字段与别名一起使用,否则不能将嵌套字段用作分区键。 不过,可以使用某些字符来创建文件的层次结构。 例如,可以使用以下查询创建一个列,该列将来自其他两个列的数据组合在一起以构成唯一的分区键:
SELECT name, id, CONCAT(name, "/", id) AS nameid
分区键必须为 NVARCHAR(MAX)、BIGINT、FLOAT 或 BIT(1.2 兼容性级别或更高级别)。 不支持 DateTime、Array 和 Records 类型,但如果将它们转换为 String,则可用作分区键。 有关详细信息,请参阅 Azure 流分析 数据类型。
按自定义字段对 Blob 输出进行分区
假设一个作业从连接到外部视频游戏服务的实时用户会话中获取输入数据,其中采集的数据包含一个用于识别会话的列 client_id。 若要按 client_id 对数据进行分区,请在创建作业时将 blob“路径模式”字段设置为在 blob 输出属性中添加分区标记 {client_id}。 当包含各种 client_id 值的数据流经流分析作业时,输出数据根据每个文件夹的单一 client_id 值保存到单独的文件夹中。

同样,如果作业输入是来自数百万个传感器的传感器数据(其中每个传感器有一个 sensor_id),那么路径模式为 {sensor_id},用于将每个传感器数据分区到不同的文件夹中。
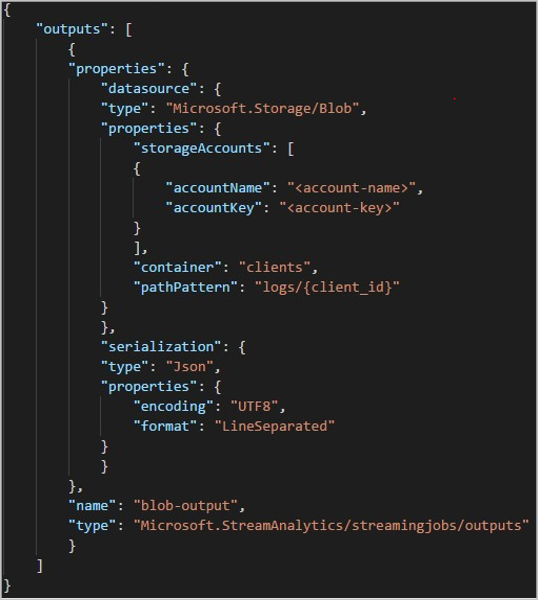
使用 REST API 时,用于该请求的 JSON 文件的输出节可能如下图所示:
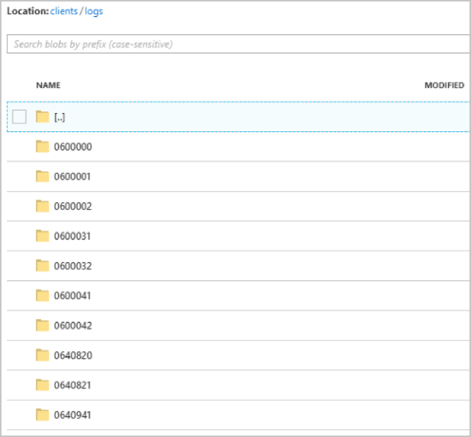
作业开始运行后,clients 容器可能如下图所示:
每个文件夹都可能包含多个 blob,其中每个 blob 包含一个或多个记录。 在前面的示例中,标记为 "06000000" 的文件夹中有一个 blob,其中包含以下内容:
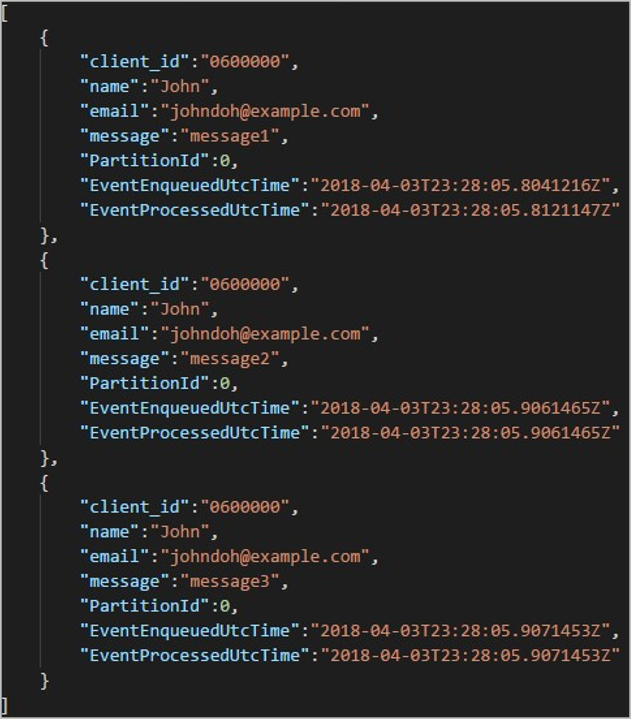
请注意,blob 中的每个记录都有一个与文件夹名称匹配的 client_id 列,这是因为用于在输出路径中对输出进行分区的列是 client_id。
自定义分区键限制
“路径模式”blob 输出属性中只允许有一个自定义分区键。 以下所有路径模式都有效:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
如果要使用多个输入字段,可以通过使用
CONCAT在查询中为 Blob 输出中的自定义路径分区创建复合键。 示例为select concat (col1, col2) as compositeColumn into blobOutput from input。 然后,可以在Azure Blob 存储中指定compositeColumn为自定义路径。分区键不区分大小写,因此
John和john等分区键等效。 此外,不能将表达式用作分区键。 例如,{columnA + columnB}无效。当输入流由分区键基数低于 8,000 的记录组成时,流分析会将记录追加到现有 Blob,并且仅在必要时创建新的 Blob。 如果基数超过 8,000,则无法保证 Stream Analytics 会写入现有 Blob 对象。 流分析不会为具有相同分区键的任意数量的记录创建新的 Blob。
如果 blob 输出 配置为不可变,则每次发送数据时,流分析都会新建 blob。
自定义 DateTime 路径模式
使用自定义 DateTime 路径模式可以指定与 Hive 流式处理约定一致的输出格式,使流分析能够将数据发送到Azure HDInsight和Azure Databricks进行下游处理。 自定义 DateTime 路径模式可以轻松地实现,只需在 blob 输出的“路径前缀”字段中使用 datetime 关键字并使用格式说明符即可。 示例为 {datetime:yyyy}。
支持的令牌
以下格式说明符令牌可以单独使用,也可以组合使用,以便实现自定义 DateTime 格式。
| 格式说明符 | 说明 | 示例时间 2018-01-02T10:06:08 的结果 |
|---|---|---|
| {datetime:yyyy} | 年份为四位数 | 2018 |
| {datetime:MM} | 月份为 01 到 12 | 01 |
| {datetime:M} | 月份范围为从1到12月份 | 1 |
| {datetime:dd} | 01到31日 | 02 |
| {datetime:d} | 日期为 1 到 31 | 2 |
| {datetime:HH} | 小时为 00 到 23,采用 24 小时格式 | 10 |
| {datetime:mm} | 分钟从 00 到 60 | 06 |
| {datetime:m} | 分钟范围从 0 到 60 | 6 |
| {datetime:ss} | 从 00 到 60 秒 | 08 |
如果不希望使用自定义 DateTime 模式,可以将 {date} 和/或 {time} 令牌添加到“路径前缀”字段,从而使用内置的 格式生成下拉列表DateTime。
DateTime 令牌扩展性和限制
可以在路径模式中使用尽量多的令牌 ({datetime:<specifier>}),直到达到路径前缀字符限制。 在单个令牌中,格式说明符的组合不能超出日期和时间下拉列表已经列出的组合。
对于 logs/MM/dd 路径分区:
| 有效表达式 | 无效表达式 |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
可以在路径前缀中多次使用同一格式说明符。 每次都必须重新输入令牌。
Hive 流媒体技术规范约定
您可以为 Blob 存储 使用自定义路径模式,并采用 Hive Streaming 约定;该约定要求在文件夹名称中使用 column= 作为标记。
示例为 year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}。
有了自定义输出,省去了更改表格和手动添加分区以传输 Stream Analytics 和 Hive 之间数据的麻烦。 许多文件夹可以使用以下方式自动添加:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
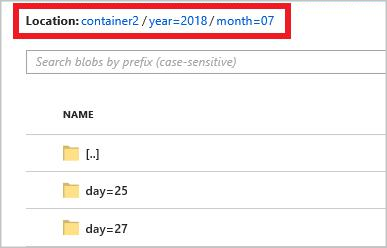
创建与 Hive 兼容的 DateTime 文件夹结构
根据 Stream Analytics Azure 门户 快速入门,创建存储帐户、资源组、流分析作业和输入源。 使用在快速入门中使用的相同示例数据。 示例数据也可在 GitHub 中使用。
使用以下配置创建 Blob 输出汇聚点:
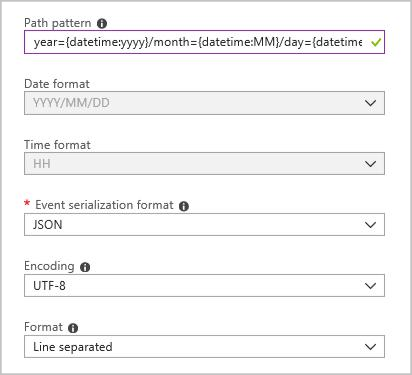
完整路径模式为:
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
启动作业时,会在 Blob 容器中创建基于路径模式的文件夹结构。 您可以细化分析到每日级别。