必须监视 Azure 流分析作业,以确保作业持续正常运行。 本文介绍如何针对要监视的常见方案设置警报。
可以通过门户或以编程方式基于操作日志数据定义指标的规则。
在 Azure 门户中设置警报
作业意外停止时将收到警报
以下示例演示如何针对作业进入失败状态设置警报。 建议对所有作业设置此警报。
在 Azure 门户中,打开要为其创建警报的流分析作业。
在“作业”页上,导航到“监视”部分。
选择“指标”,然后选择“新建警报规则”。
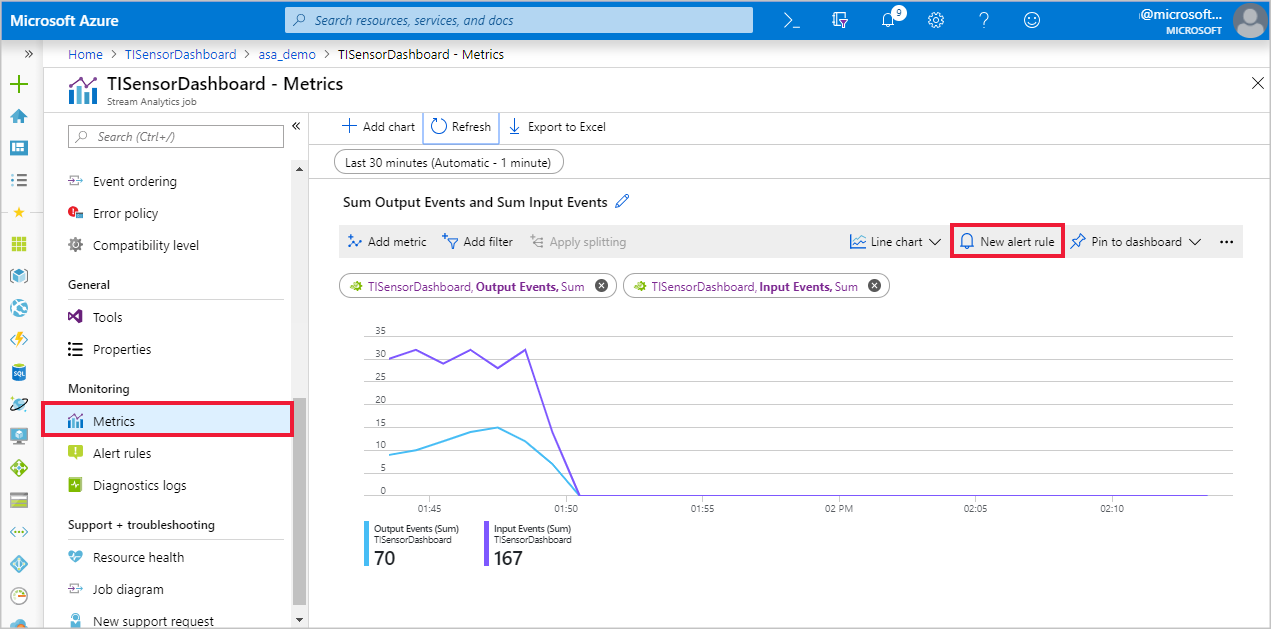
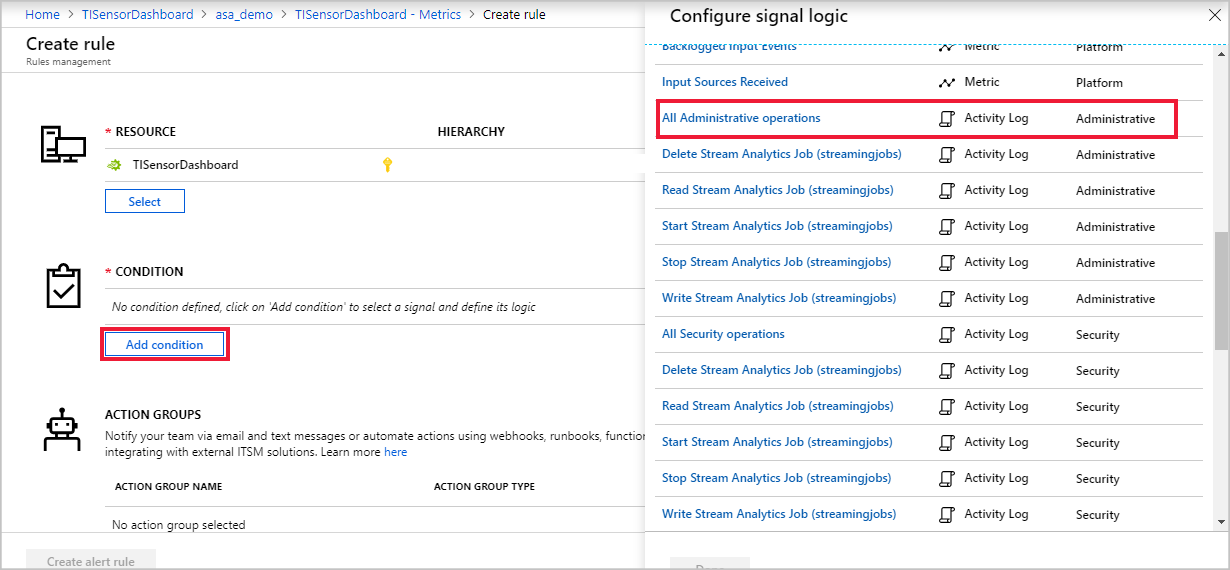
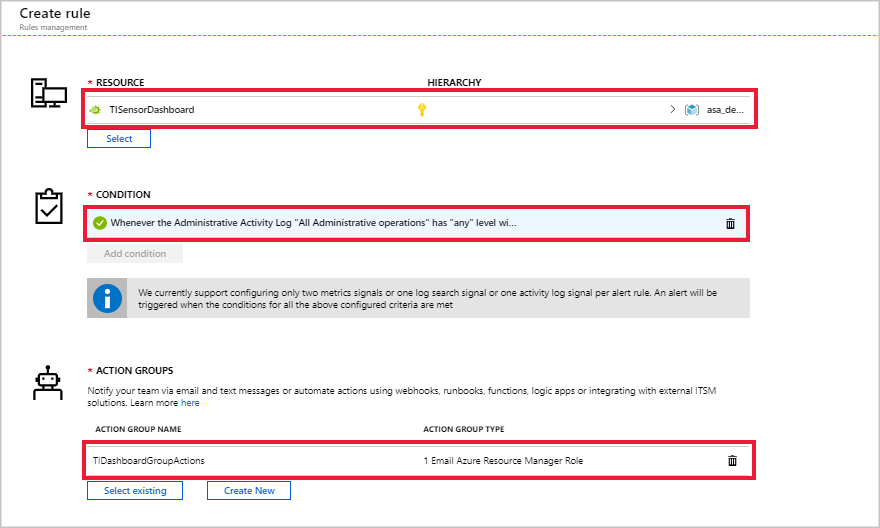
流分析作业名称应会自动显示在“资源”下。 单击“添加条件”,然后选择“配置信号逻辑”下的“所有管理操作”。
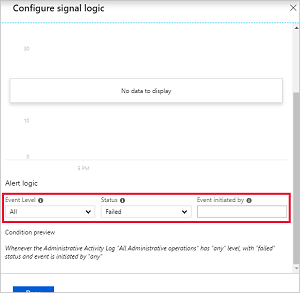
在“配置信号逻辑”下,将“事件级别”更改为“所有”,将“状态”更改为“失败”。 将“事件发起者”保留空白,然后选择“完成”。
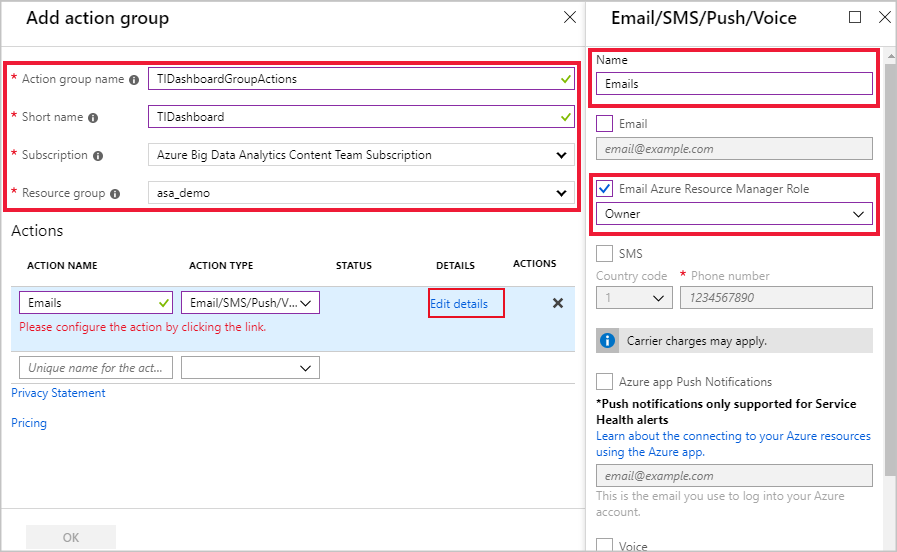
选择现有的操作组或创建新组。 本示例创建了名为 TIDashboardGroupActions 的新操作组,其中包含一个“电子邮件”操作,该操作可将电子邮件发送到具有“所有者”Azure 资源管理器角色的用户。
“资源”、“条件”和“操作组”都应该有对应的条目。 请注意,为了触发警报,需要满足所定义的条件。 例如,可以每 5 分钟检测一次某个指标在过去 15 分钟的平均值。
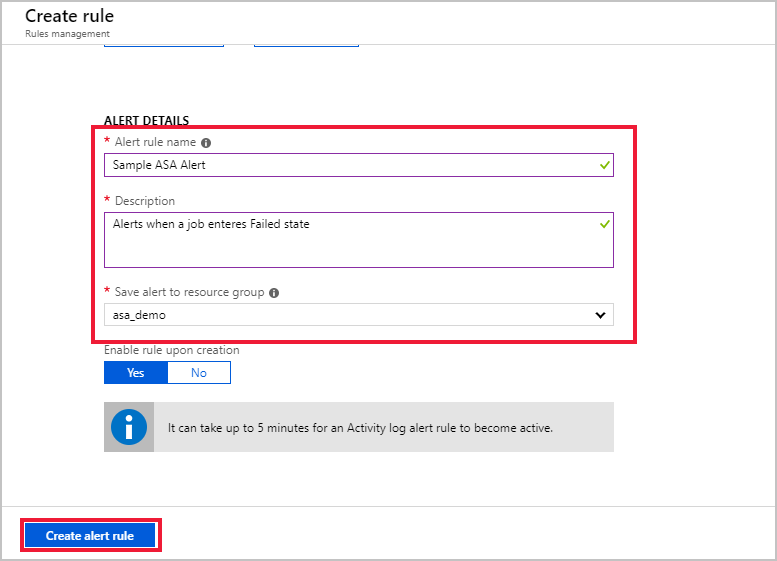
在“警报详细信息”中添加警报规则名称、说明和资源组,然后单击“创建警报规则”创建流分析作业的规则。