本教程介绍如何使用 Text Analytics 分析 Azure Synapse Analytics 上的非结构化文本。 文本分析 是一种 Microsoft Foundry 工具 ,可用于使用自然语言处理(NLP)功能执行文本挖掘和文本分析。
本教程演示如何将 text analytics 与 SynapseML 配合使用:
- 在句子或文档级别检测情感标签
- 标识给定文本输入的语言
- 从文本中识别实体,并使用链接指向已知的知识库。
- 从文本中提取关键短语
- 标识文本中的不同实体并将它们归类到预定义的类或类型中
- 标识并屏蔽给定文本中的敏感实体
如果没有Azure订阅,开始前创建试用帐户。
先决条件
- Azure Synapse Analytics 工作区,配置为默认存储的一个 Azure Data Lake Storage Gen2 存储帐户。 你需要成为你所使用的 Data Lake Storage Gen2 文件系统的 Storage Blob 数据参与者。
- Azure Synapse Analytics 工作区中的 Spark 池。 有关详细信息,请参阅
在 Azure Synapse 。 - Azure Synapse 中配置 Foundry 工具的教程中所述的预配置步骤。
开始
打开Synapse Studio并创建新笔记本。 要开始,请导入 SynapseML。
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
配置文本分析
使用在 预配置步骤中配置的链接文本分析。
linked_service_name = "<Your linked service for text analytics>"
文本情绪
文本情绪分析提供了一种在句子和文档级别检测情绪标签(如“消极”、“中性”和“积极”)和置信度分数的方法。 有关支持的语言列表,请参阅 Text Analytics API 的支持语言。
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Foundry Tools on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
预期结果
| 文本消息 | 情绪 |
|---|---|
| 今天天气晴朗,我真高兴! | 积极 |
| 我被这高峰时段的交通弄得心烦意乱 | 消极 |
| Spark上的Foundry工具还不错。 | 中立 |
语言检测程序
语言检测程序评估每个文档的文本输入,并返回带有指示分析强度分数的语言标识符。 此功能对于用于收集语言未知的任意文本的内容存储非常有用。 有关支持的语言列表,请参阅 Text Analytics API 的支持语言。
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
预期结果
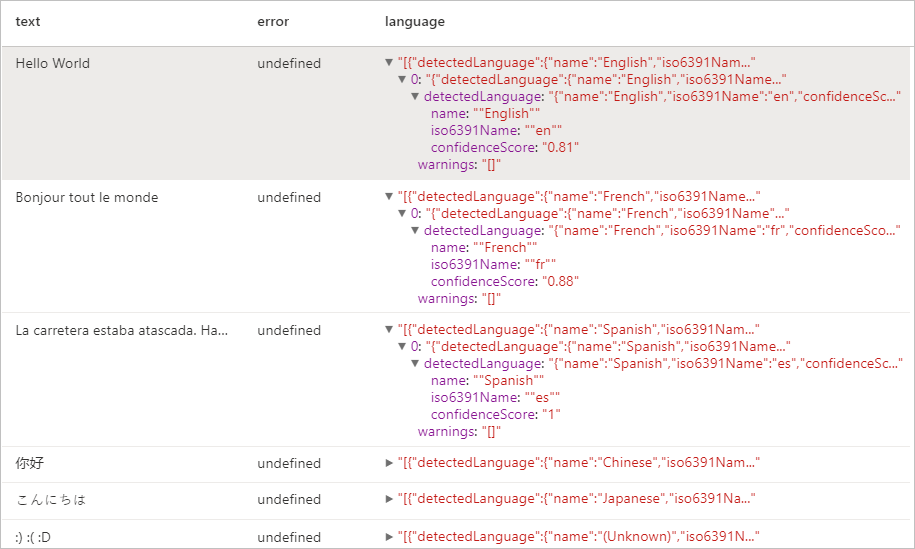
实体检测器
实体检测器返回一个已识别实体的列表,并附有指向一个知名知识库的链接。 有关支持的语言列表,请参阅 Text Analytics API 的支持语言。
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
预期结果
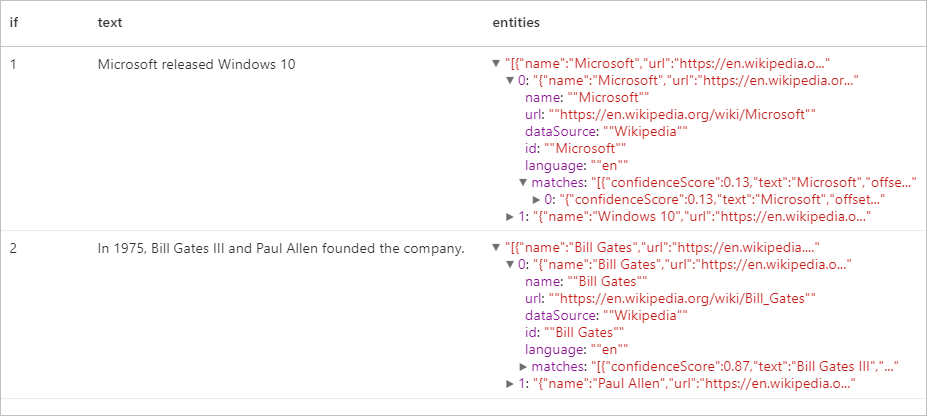
关键短语提取程序
“关键短语提取”可以计算非结构化的文本,并返回关键短语列表。 如果需要快速确定文档集中的要点,此功能十分有用。 有关支持的语言列表,请参阅 Text Analytics API 的支持语言。
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
预期结果
| 文本消息 | 关键短语 |
|---|---|
| Hello world。 我很喜欢这些输入文本。 | “[”Hello world“,”输入文本“]” |
| Bonjour tout le monde | "["你好", "世界"]" |
| 道路被堵住了。 Había mucho tráfico el día de ayer. | “[”交通繁忙“,”日“,”公路“,”昨天“]” |
命名实体识别 (NER)
命名实体识别 (NER) 是指识别文本中不同实体,并将它们分入预定义类或类型(例如:人员、位置、事件、产品和组织)的能力。 有关支持的语言列表,请参阅 Text Analytics API 的支持语言。
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
预期结果
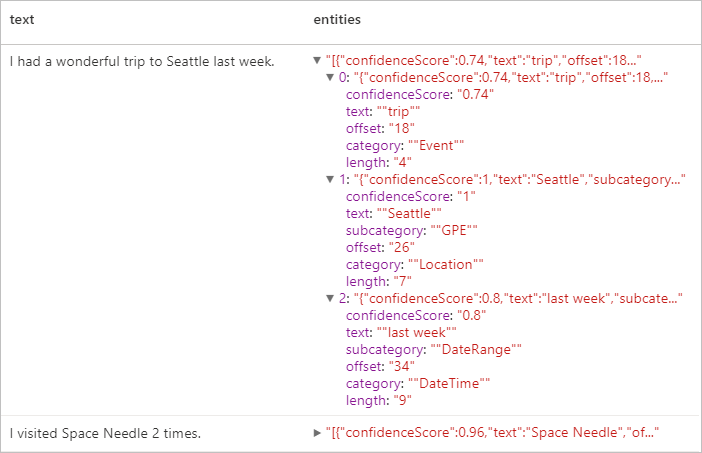
个人身份信息 (PII) V3.1
PII 功能是 NER 的一部分,可以识别和标记文本中与个人相关的敏感实体,例如:电话号码、电子邮件地址、邮寄地址、护照号码。 有关支持的语言列表,请参阅 Text Analytics API 的支持语言。
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
预期结果
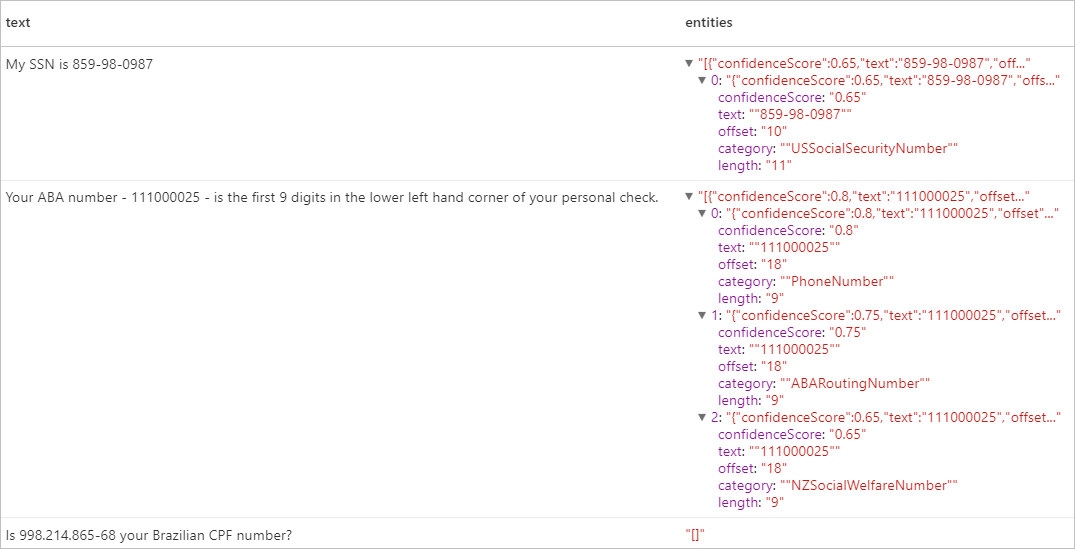
清理资源
为了确保关闭 Spark 实例,请结束任何已连接的会话(笔记本)。 达到 Apache Spark 池中指定的空闲时间时,池将会关闭。 也可以从笔记本右上角的状态栏中选择“停止会话”。
