借助 Azure Synapse Analytics,可以使用 Apache Spark 在工作区中的 Apache Spark 池上运行笔记本、作业和其他类型的应用程序。
本文介绍如何监视 Apache Spark 应用程序,以便关注最新状态、问题和进度。
查看 Apache Spark 应用程序
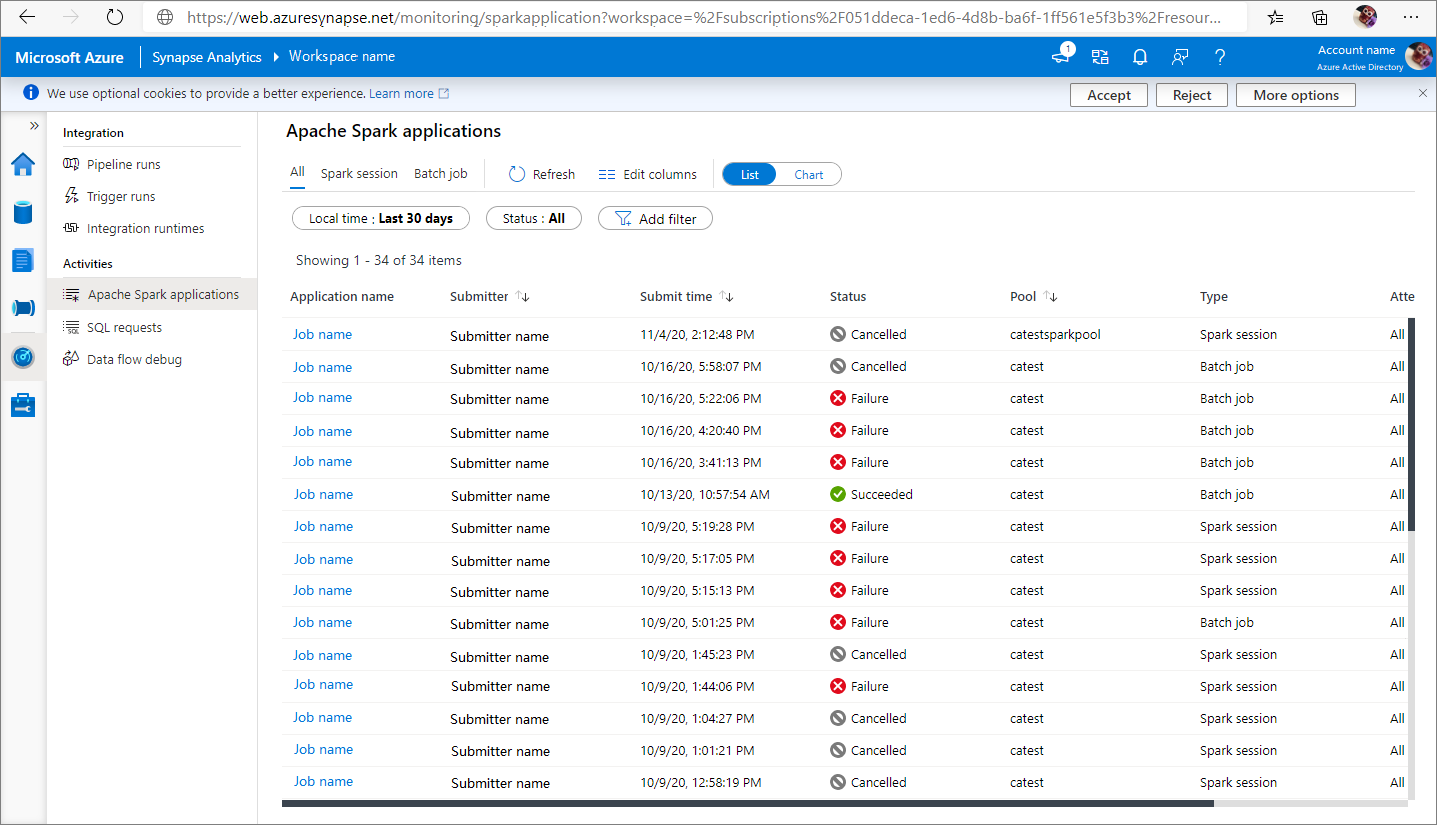
从 Monitor ->Apache Spark 应用程序 中查看所有 Apache Spark 应用程序。
查看已完成的 Apache Spark 应用程序
打开 Monitor,然后选择 Apache Spark 应用程序。 若要查看已完成的 Apache Spark 应用程序的详细信息,请选择 Apache Spark 应用程序。

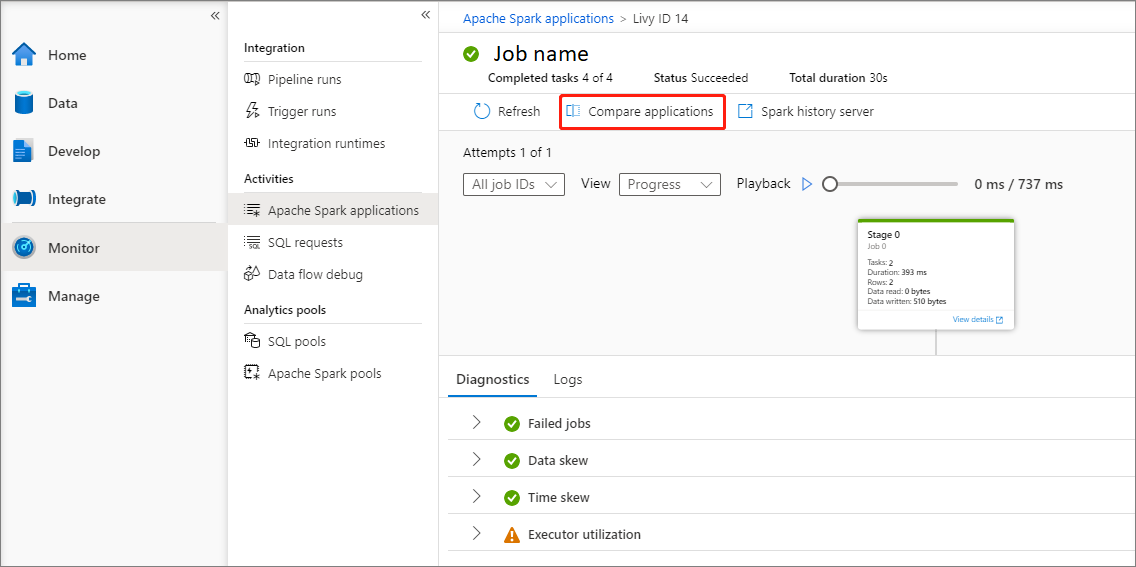
检查 已完成的任务、 状态和 总持续时间。
刷新作业。
单击“ 比较应用程序 ”以使用比较功能,有关此功能的详细信息,请参阅 “比较 Apache Spark 应用程序”。
单击 Spark 历史记录服务器 以打开“历史记录服务器”页。
检查 摘要 信息。
在 “诊断 ”选项卡中检查诊断。
检查 日志。 可以通过在下拉列表中选择不同的选项来查看 Livy、 Prelaunch 和 驱动程序 日志的完整日志。 可以通过搜索关键字直接检索所需的日志信息。 单击“ 下载日志 ”将日志信息下载到本地,然后选择“ 筛选错误和警告 ”复选框以筛选所需的错误和警告。
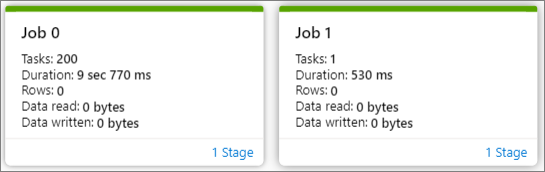
你可以在生成的作业图中查看作业概况。 默认情况下,该图将显示所有作业。 可按作业 ID 筛选此视图。
默认情况下,“进度”显示处于选中状态。 可以通过在“视图”下拉列表中选择///持续时间”来检查数据流。
若要播放该作业,请单击“播放”按钮。 可以随时单击“ 停止 ”按钮以停止。
使用滚动条放大和缩小作业图,还可以选择“ 缩放以适应” ,使其适合屏幕。

作业图节点显示每个阶段的以下信息:
作业 ID
任务编号
持续时间
行计数
数据读取:输入大小和随机读取大小之和
写入的数据:输出大小和随机写入大小之和
阶段编号
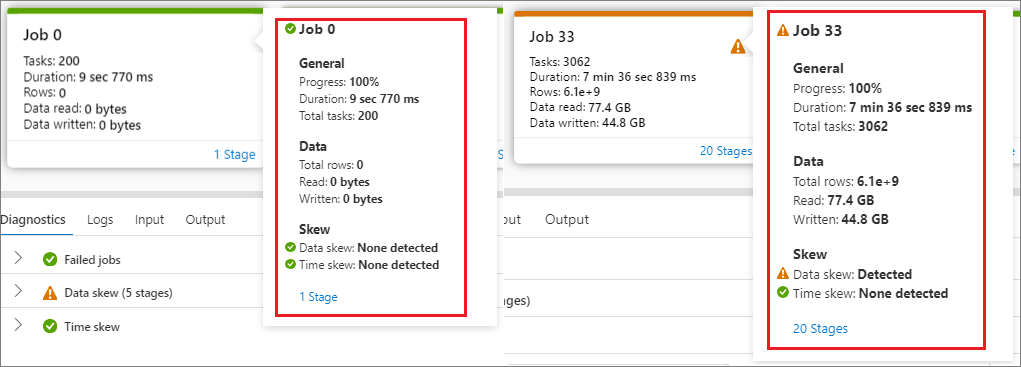
将鼠标悬停在作业上,作业详细信息将显示在工具提示中:
作业状态图标:如果作业状态成功,它将显示为绿色“√”;如果作业检测到问题,它将显示黄色“!”
作业 ID
常规部分:
- 进展
- 持续时间
- 总任务数
数据部分:
- 总行数
- 读取大小
- 写入大小
倾斜部分:
- 数据倾斜
- 时间倾斜
阶段编号
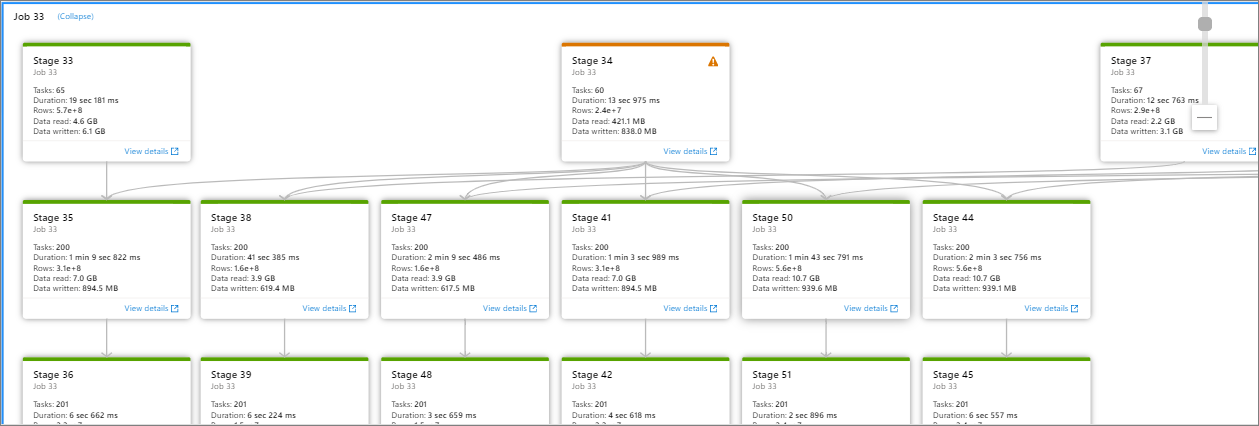
单击 “阶段编号 ”以展开作业中包含的所有阶段。 单击“作业 ID”旁边的“折叠”以折叠作业中的所有阶段。
单击阶段图中的 “查看详细信息 ”,此时会显示阶段的详细信息。

监视 Apache Spark 应用程序进度
打开 Monitor,然后选择 Apache Spark 应用程序。 若要查看有关正在运行的 Apache Spark 应用程序的详细信息,请选择提交的 Apache Spark 应用程序。 如果 Apache Spark 应用程序仍在运行,则可以监视进度。

检查 已完成的任务、 状态和 总持续时间。
取消 Apache Spark 应用程序。
刷新该作业。
单击 “Spark UI ”按钮转到“Spark 作业”页。
对于 作业图、 摘要、 诊断、 日志。 你可以在生成的作业图中查看作业概况。 请参阅 查看已完成的 Apache Spark 应用程序的步骤 5 - 15。

查看已取消的 Apache Spark 应用程序
打开 Monitor,然后选择 Apache Spark 应用程序。 若要查看有关已取消的 Apache Spark 应用程序的详细信息,请选择 Apache Spark 应用程序。

检查 已完成的任务、 状态和 总持续时间。
刷新该作业。
单击“ 比较应用程序 ”以使用比较功能,有关此功能的详细信息,请参阅 “比较 Apache Spark 应用程序”。
单击“Spark history server”,打开 Apache History Server 链接。
查看图形。 你可以在生成的作业图中查看作业概况。 请参阅 查看已完成的 Apache Spark 应用程序的步骤 5 - 15。

调试失败的 Apache Spark 应用程序
打开 Monitor,然后选择 Apache Spark 应用程序。 若要查看有关失败的 Apache Spark 应用程序的详细信息,请选择 Apache Spark 应用程序。

检查 已完成的任务、 状态和 总持续时间。
刷新该作业。
单击“ 比较应用程序 ”以使用比较功能,有关此功能的详细信息,请参阅 “比较 Apache Spark 应用程序”。
单击“Spark history server”,打开 Apache History Server 链接。
查看图形。 你可以在生成的作业图中查看作业概况。 请参阅 查看已完成的 Apache Spark 应用程序的步骤 5 - 15。

查看输入数据/输出数据
选择 Apache Spark 应用程序,然后单击“ 输入数据/输出数据”选项卡 以查看 Apache Spark 应用程序的输入和输出日期。 此函数可帮助你调试 Spark 作业。 数据源支持两种存储方法:gen2 和 blob。
“输入数据”选项卡
单击 “复制输入 ”按钮,将输入文件粘贴到本地。
单击“ 导出到 CSV ”按钮以 CSV 格式导出输入文件。
可以在 “搜索”框中 通过输入关键字(关键字包括文件名、读取格式和路径)来搜索文件。
可以通过单击 “名称”、“ 读取格式”和 “路径”对输入文件进行排序。
使用鼠标将鼠标悬停在输入文件上,将显示 “下载/复制路径/更多 ”按钮的图标。
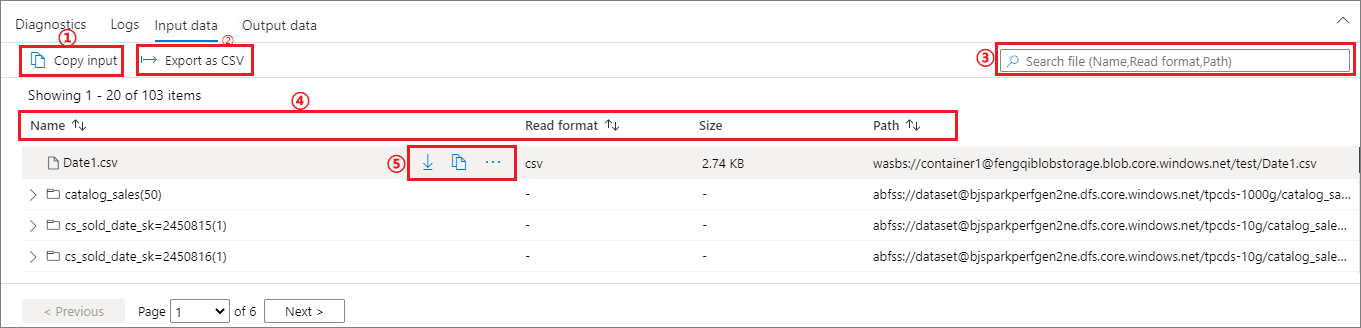
单击“ 更多 ”按钮。 上下文菜单中将显示“复制路径/在资源管理器中显示/属性”。
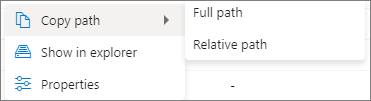
复制路径:可以复制 完整路径 和 相对路径。
在资源管理器中显示:可跳转到链接的存储帐户(“数据”->“已链接”)。
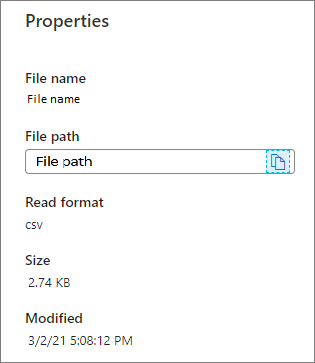
属性:显示文件的基本属性(文件名/文件路径/读取格式/大小/修改)。
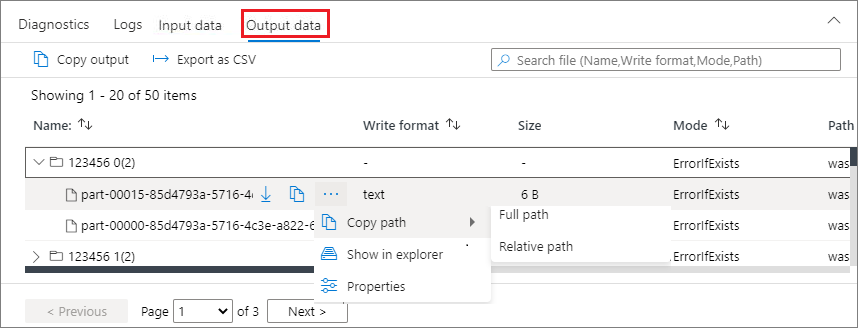
“输出数据”选项卡
显示与输入选项卡相同的功能。
比较 Apache Spark 应用程序
可通过两种方法比较应用程序。 可以通过选择 “比较应用程序”进行比较,或单击 “笔记本中的比较 ”按钮在笔记本中查看它。
按应用程序比较
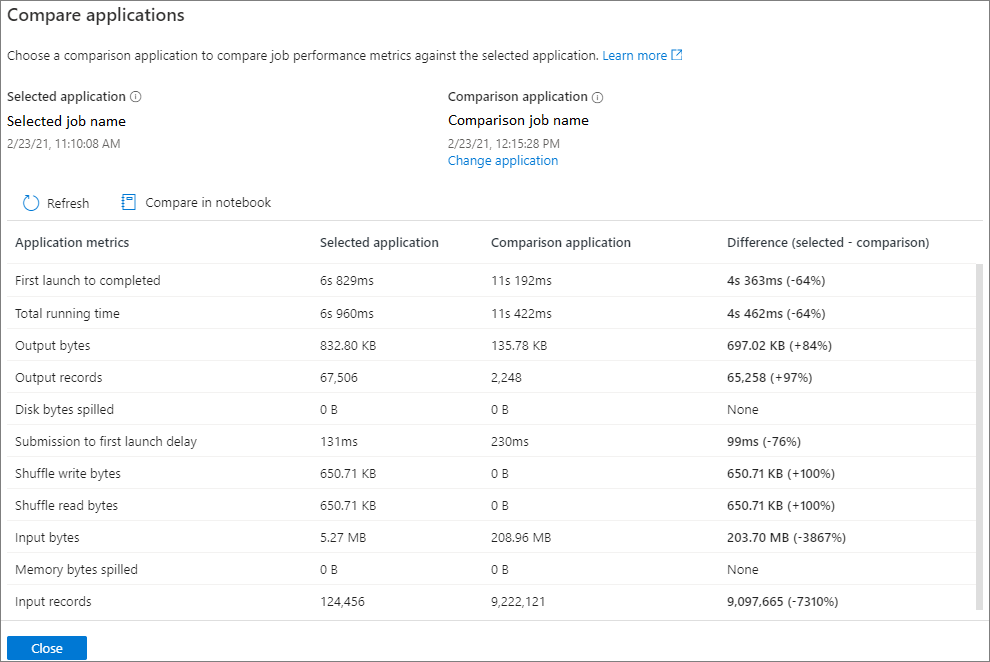
单击“ 比较应用程序 ”按钮,然后选择一个应用程序来比较性能。 可以看到这两个应用程序之间的差异。

使用鼠标将鼠标悬停在应用程序上,然后显示 “比较应用程序 ”图标。
单击“ 比较应用程序 ”图标,此时将弹出“比较应用程序”页。
单击“ 选择应用程序 ”按钮打开 “选择比较应用程序 ”页。
选择比较应用程序时,需要输入应用程序 URL,或从定期列表中选择。 然后单击“ 确定 ”按钮。
比较结果将显示在比较应用程序页上。
在笔记本中比较
单击“比较应用程序”页上的“在笔记本中比较”按钮打开笔记本。 .ipynb 文件的默认名称是定期应用程序分析。
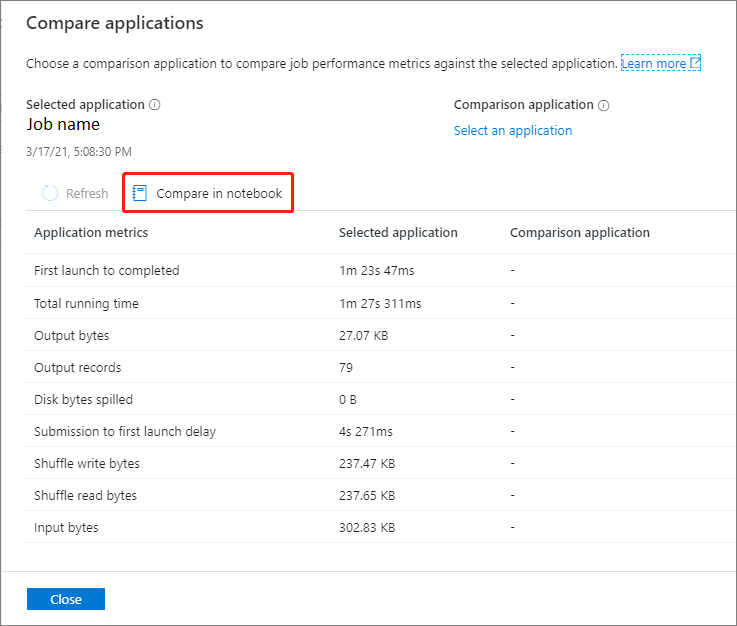
在 Notebook:定期应用程序分析文件中,可以在设置 Spark 池和语言后直接运行它。
后续步骤
有关监视管道运行的详细信息,请参阅 使用 Synapse Studio 的“监视管道运行 ”一文。