Azure Synapse Analytics 中的笔记本(Synapse 笔记本)是一种 Web 界面,用于创建包含实时代码、可视化效果和叙述性文本的文件。 笔记本是验证想法并使用快速试验从数据中获取见解的好地方。 笔记本还广泛用于数据准备、数据可视化、机器学习和其他大数据方案。
使用 Synapse 笔记本,可以:
- 无需设置即可开始工作。
- 利用内置企业安全功能帮助确保数据安全。
- 针对 Spark 和 SQL,分析跨原始格式(如 CSV、TXT 和 JSON)、已处理的文件格式(如 Parquet、Delta Lake 和 ORC)以及 SQL 表格数据文件的数据。
- 利用增强的创作功能和内置的数据可视化功能提高工作效率。
本文介绍如何在 Synapse Studio 中使用笔记本。
创建笔记本
可以从“对象资源管理器”创建新笔记本或将现有笔记本导入到 Synapse 工作区。 选择“开发”,右键单击“笔记本”,然后选择“新笔记本”或“导入”。 Synapse 笔记本可识别标准 Jupyter Notebook IPYNB 文件。
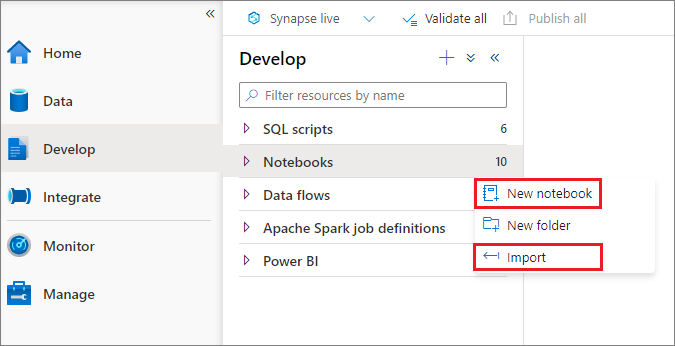
开发笔记本
笔记本由单元格组成,单元格是单独的代码块或可单独运行或作为组运行的文本块。
以下部分介绍了开发笔记本的操作:
- 添加单元格
- 设置主要语言
- 使用多种语言
- 使用临时表跨语言引用数据
- 使用 IDE 样式 IntelliSense
- 使用代码片段
- 使用工具栏按钮设置文本单元格的格式
- 撤消或恢复单元格操作
- 注释代码单元格
- 移动单元格
- 删除单元格
- 折叠单元格输入
- 折叠单元格输出
- 使用笔记本大纲
注意
在笔记本中,会自动创建一个 SparkSession 实例,存储在名为 spark 的变量中。 还有一个名为 sc 的 SparkContext 变量。 用户可以直接访问这些变量,但不应更改这些变量的值。
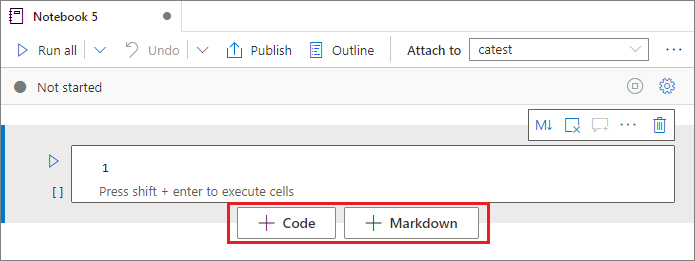
添加单元格
有多种方法可向笔记本添加新单元格:
将鼠标悬停在两个单元格之间的空白地方,然后选择“代码”或“Markdown” 。
使用命令模式下的快捷键。 选择 A 键在当前单元格上方插入单元格。 选择 B 键在当前单元格下方插入单元格。
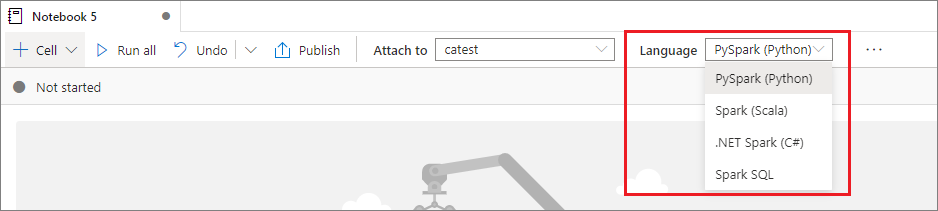
设置主要语言
Synapse 笔记本支持四种 Apache Spark 语言:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
可以从顶部命令栏中的“语言”下拉列表为新添加的单元格设置主要语言。
使用多种语言
通过在单元格开始位置指定正确的语言 magic 命令,可以在一个笔记本中使用多种语言。 下表列出了用于切换单元格语言的 magic 命令。
| magic 命令 | 语言 | 说明 |
|---|---|---|
%%pyspark |
Python | 针对 SparkContext 运行 Python 查询。 |
%%spark |
Scala | 针对 SparkContext 运行 Scala 查询。 |
%%sql |
Spark SQL | 针对 SparkContext 运行 Spark SQL 查询。 |
%%csharp |
.NET for Spark C# | 针对 SparkContext 运行 .NET for Spark C# 查询。 |
%%sparkr |
R | 针对 SparkContext 运行 R 查询。 |
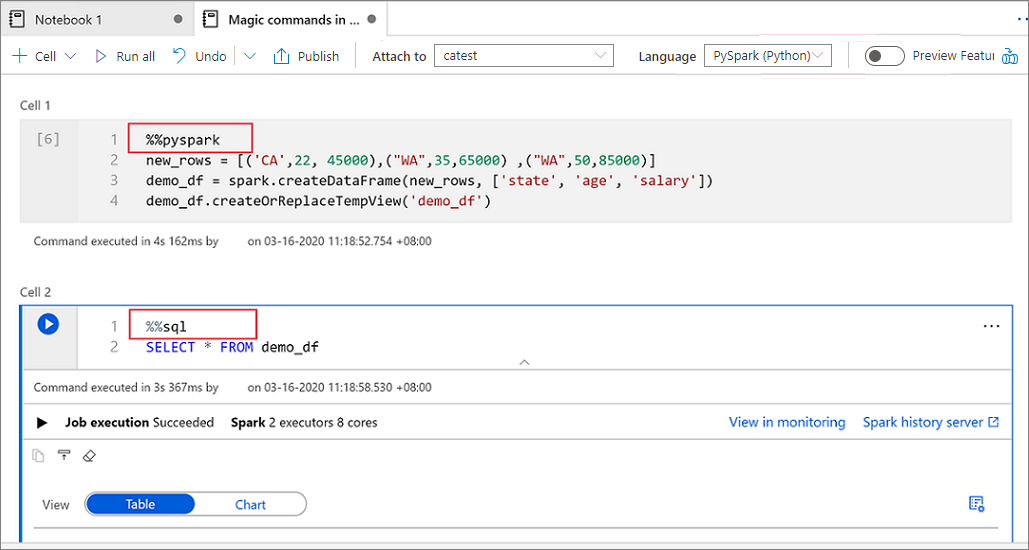
下图是一个示例,说明如何在 Spark (Scala) 笔记本中使用 %%pyspark magic 命令编写 PySpark 查询,或使用 %%sql magic 命令编写 Spark SQL 查询。 笔记本的主要语言设置为 PySpark。
使用临时表跨语言引用数据
不能直接在 Synapse 笔记本中跨不同语言引用数据或变量。 在 Spark 中,可以跨语言引用临时表。 下面是一个示例,说明如何使用 Spark 临时表作为解决方法来读取 PySpark 和 Spark SQL 中的 Scala 数据帧:
在单元格 1 中,使用 Scala 从 SQL 池连接器读取数据帧,并创建一个临时表:
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )在单元格 2 中,使用 Spark SQL 查询数据:
%%sql SELECT * FROM mydataframetable在单元格 3 中,使用 PySpark 中的数据:
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
使用 IDE 样式 IntelliSense
Synapse 笔记本集成了 Monaco 编辑器,将 IDE 样式的 IntelliSense 引入到了单元格编辑器中。 语法突出显示、错误标记和自动代码补全功能有助于你编写代码并更快地找出问题。
对于不同的语言,IntelliSense 功能处于不同的成熟度级别。 请参阅下表了解支持的功能。
| Languages | 语法突出显示 | 语法错误标记 | 语法代码补全 | 变量代码补全 | 系统函数代码补全 | 用户函数代码补全 | 智能缩进 | 代码折叠 |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 |
| Spark (Scala) | 是 | 是 | 是 | 是 | 是 | 是 | No | 是 |
| Spark SQL | 是 | 是 | 是 | 是 | 是 | 否 | No | 否 |
| .NET for Spark (C#) | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 |
需要建立活动 Spark 会话,才能在 .NET for Spark (C#) 中享受变量代码完成、系统函数代码完成和用户函数代码完成所带来的好处。
使用代码片段
Synapse 笔记本提供代码片段,以帮助你更轻松地输入常用代码模式。 这些模式包括配置 Spark 会话、将数据读取为 Spark 数据帧,以及使用 Matplotlib 绘制图表。
代码片段与其他建议混合在一起显示在 IDE 样式 IntelliSense 的快捷键中。 代码片段内容与代码单元格语言一致。 可通过在代码单元格编辑器中输入 snippet 或代码片段标题中出现的任何关键字来查看可用的代码片段。 例如,通过输入 read,可查看用于从各种数据源读取数据的代码片段列表。

使用工具栏按钮设置文本单元格的格式
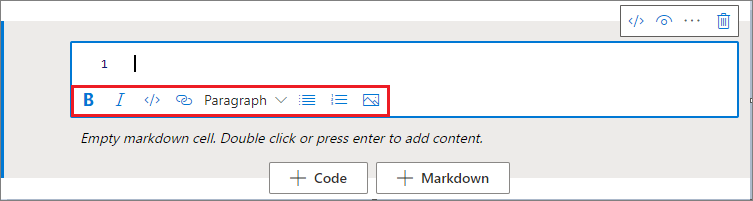
可以使用文本单元格工具栏中的格式按钮执行常见的 Markdown 操作。 这些操作包括使文本加粗、使文本倾斜、通过下拉菜单创建段落和标题、插入代码、插入无序列表、插入有序列表、插入超链接以及从 URL 插入图像。
撤消或恢复单元格操作
要撤消最近执行的单元格操作,请选择“撤消”或“恢复”按钮,或者选择 Z 键或 Shift+Z。 现在可以撤消或恢复 10 个历史单元格操作。

支持的单元格操作包括:
- 插入或删除行。 可以通过选择“撤消”来撤销删除操作。 此操作将文本内容与单元格一起保留。
- 重新排序单元格。
- 打开或关闭参数单元格。
- 在代码单元格和 Markdown 单元格之间转换。
注意
不能撤消单元格中的文本操作或注释操作。
注释代码单元格
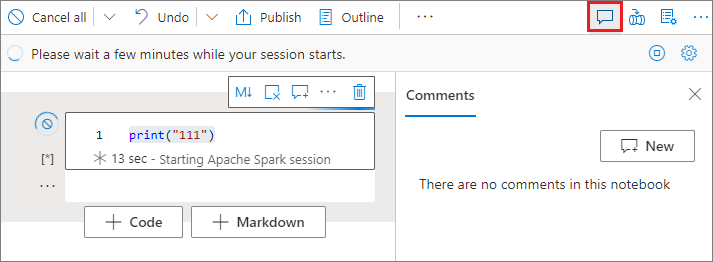
选择笔记本工具栏上的“注释”按钮以打开“注释”窗格。
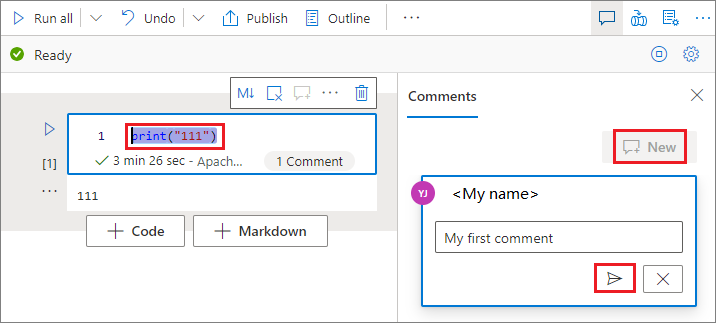
在代码单元格中选择代码,选择“注释”窗格中的“新建”,添加注释,然后选择“发布注释”按钮。
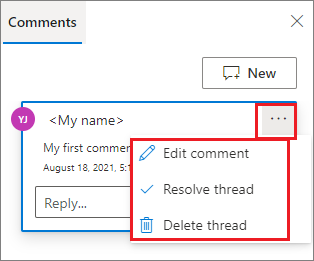
如有必要,可以通过选择注释旁的“更多”省略号 (...) 来执行“编辑注释”、“解析线程”和“删除线程”操作。
移动单元格
若要移动单元格,请选择单元格左侧,并将单元格拖动到所需位置。
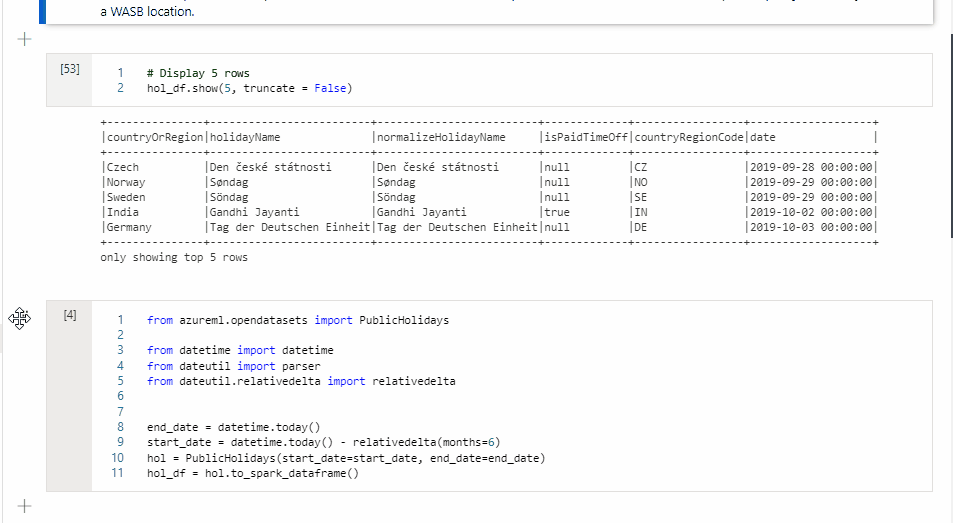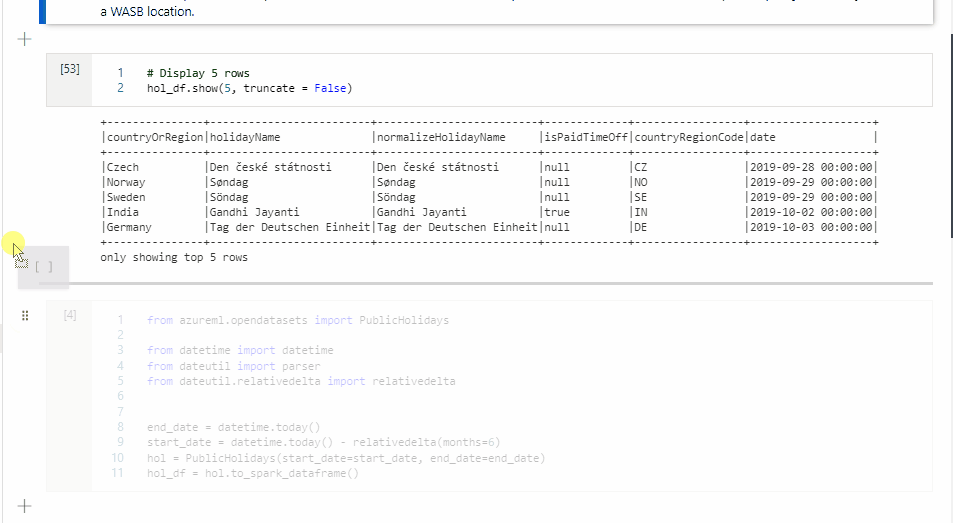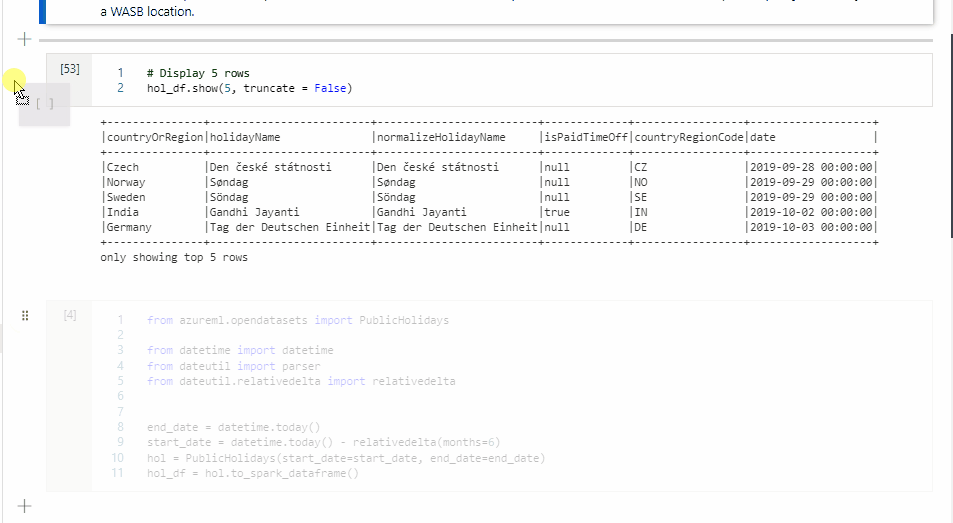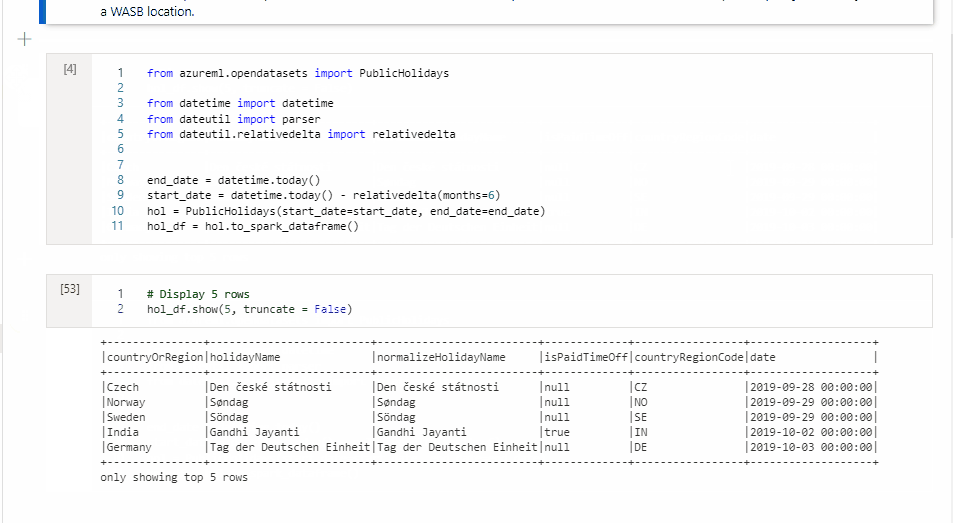
删除单元格
若要删除单元格,请选择单元格右侧的“删除”按钮。
还可以使用命令模式中的快捷键。 选择 Shift+D 删除当前单元格。
折叠单元格输入
要折叠当前单元格的输入,请选择单元格工具栏上的“更多命令”省略号 (...),然后选择“隐藏输入”。 若要展开输入,请在单元格处于折叠状态时选择“显示输入”。
折叠单元格输出
要折叠当前单元格的输出,请选择单元格工具栏上的“更多命令”省略号 (...),然后选择“隐藏输出”。 若要展开输出,请在单元格的输出处于隐藏状态时选择“显示输出”。
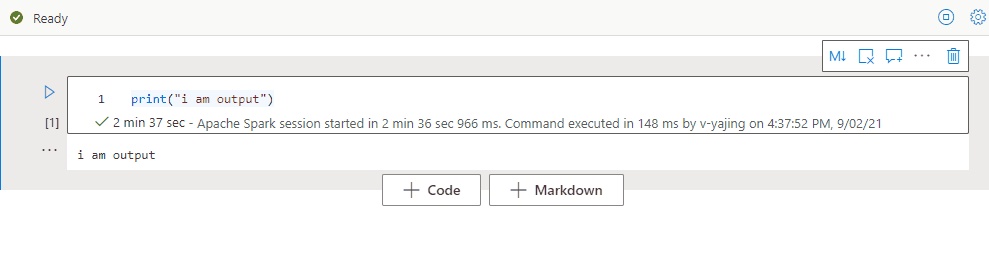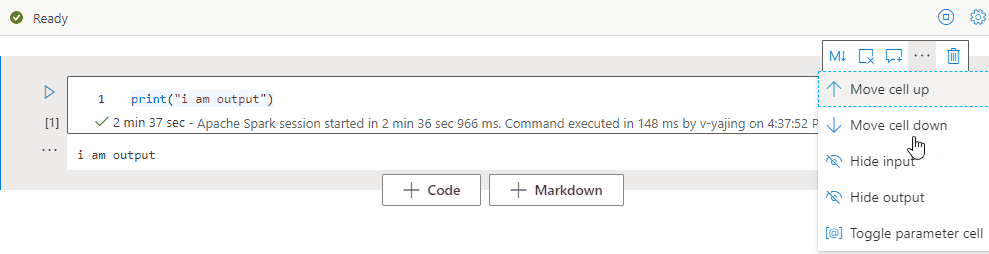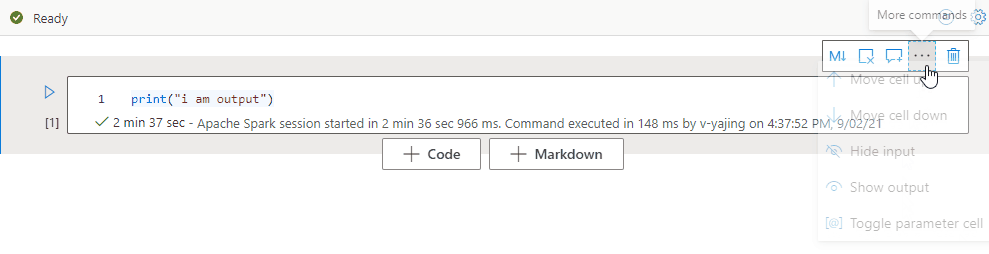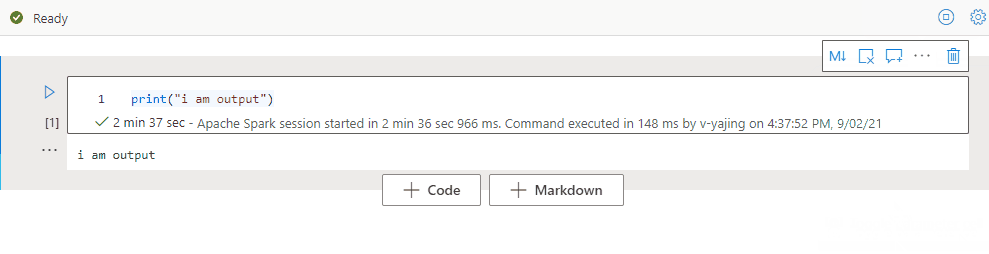
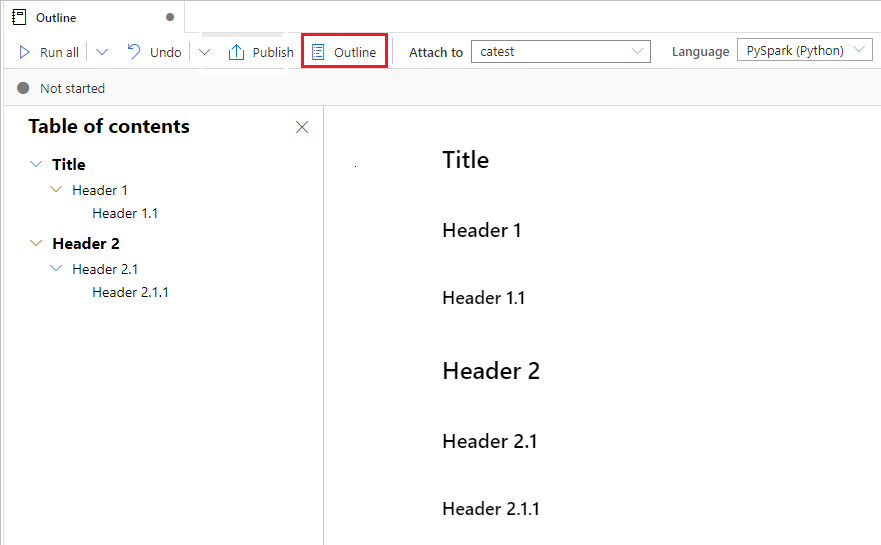
使用笔记本大纲
大纲(目录)在边栏窗口中显示任何 Markdown 单元格的第一个 Markdown 标题,用于快速导航。 大纲边栏可根据最适合屏幕的方式调整大小和折叠。 要打开或隐藏边栏,请选择笔记本命令栏上的“大纲”按钮。
运行笔记本
你可以逐个或同时在笔记本中运行代码单元格。 每个单元格的状态和进度都显示在笔记本中。
注意
删除笔记本不会自动取消当前正在运行的任何作业。 如果需要取消一项作业,请转到“监视”中心并手动取消它。
运行单元格
可以通过多种方法在单元格中运行代码:
将鼠标悬停在要运行的单元格上,然后选择“运行单元格”按钮,或选择 Ctrl+Enter。

使用命令模式下的快捷键。 选择 Shift+Enter 运行当前单元格并选择下面的单元格。 选择 Alt+Enter 运行当前单元格并在下面插入一个新单元格。
运行所有单元格
要按顺序运行当前笔记本中的所有单元格,请选择“全部运行”按钮。

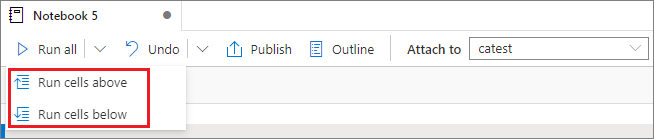
运行上方或下方的所有单元格
要按顺序运行当前单元格上方的所有单元格,请展开“全部运行”按钮的下拉列表,然后选择“运行上方的单元格”。 选择“运行下方的单元格”,按顺序运行当前单元格下方的所有单元格。
取消所有正在运行的单元格
要取消正在运行的单元格或在队列中等待的单元格,请选择“全部取消”按钮。

引用笔记本
要在当前笔记本上下文中引用另一个笔记本,请使用 %run <notebook path> magic 命令。 引用笔记本中定义的所有变量在当前笔记本中都可用。
下面是一个示例:
%run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }
可以在交互模式和管道中使用笔记本引用。
%run magic 命令具有以下限制:
- 此命令支持嵌套调用,但不支持递归调用。
- 此命令仅支持将绝对路径或笔记本名称作为参数传递。 它不支持相对路径。
- 此命令目前只支持四种参数值类型:
int、float、bool和string。 它不支持变量替换操作。 - 必须发布引用的笔记本。 需要发布笔记本来引用它们,除非选择用于启用未发布的笔记本引用的选项。
- 引用的笔记本不支持语句超过五行。
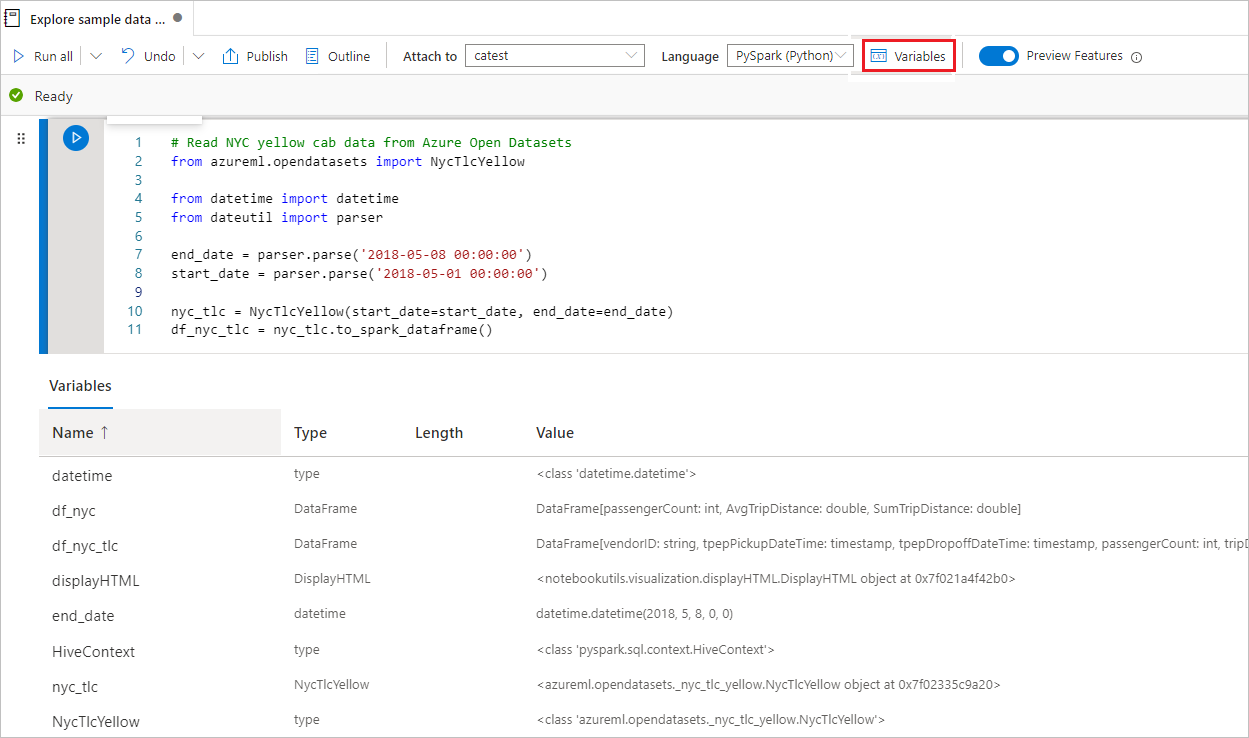
使用变量资源管理器
Synapse 笔记本以表的形式提供内置变量资源管理器,其在 PySpark (Python) 单元格的当前 Spark 会话中列出变量。 该表包括变量名称、类型、长度和值的列。 在代码单元格中定义更多变量时,系统会自动显示这些变量。 选择每个列标题时,会对表中的变量进行排序。
要打开或隐藏变量资源管理器,请选择笔记本命令栏上的“变量”按钮。
注意
变量资源管理器仅支持 Python。
使用单元格状态指示器
逐步单元格运行状态显示在单元格下方,可帮助查看其当前进度。 单元格运行完成后,会显示具有总持续时间和结束时间的摘要,并将其保留在此处供将来引用。

使用 Spark 进度指示器
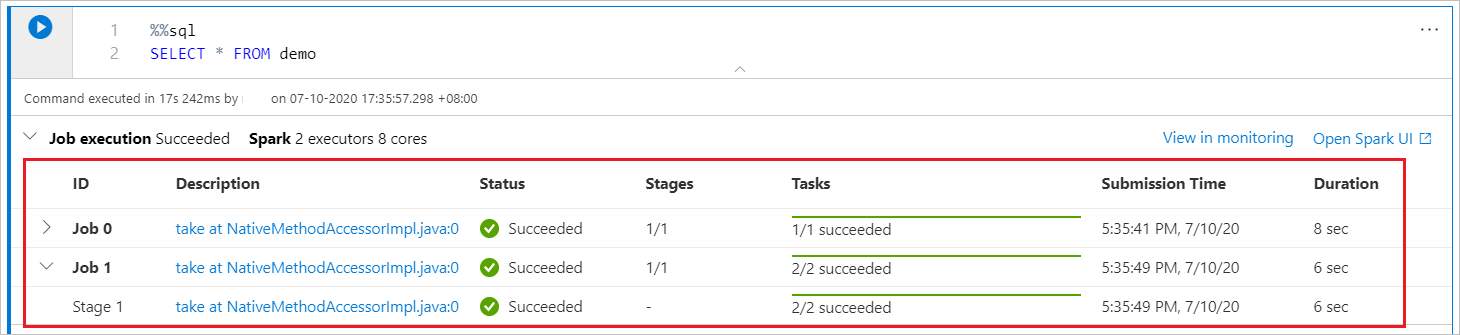
Synapse 笔记本仅基于 Spark。 代码单元格在无服务器 Apache Spark 池上远程运行。 Spark 作业进度指示器提供有实时进度栏,可帮助了解作业运行状态。
每个作业或阶段的任务数有助于识别 Spark 作业的并行级别。 还可选择作业(或阶段)名称上的链接,来更深入地了解特定作业(或阶段)的 Spark UI。
配置 Spark 会话
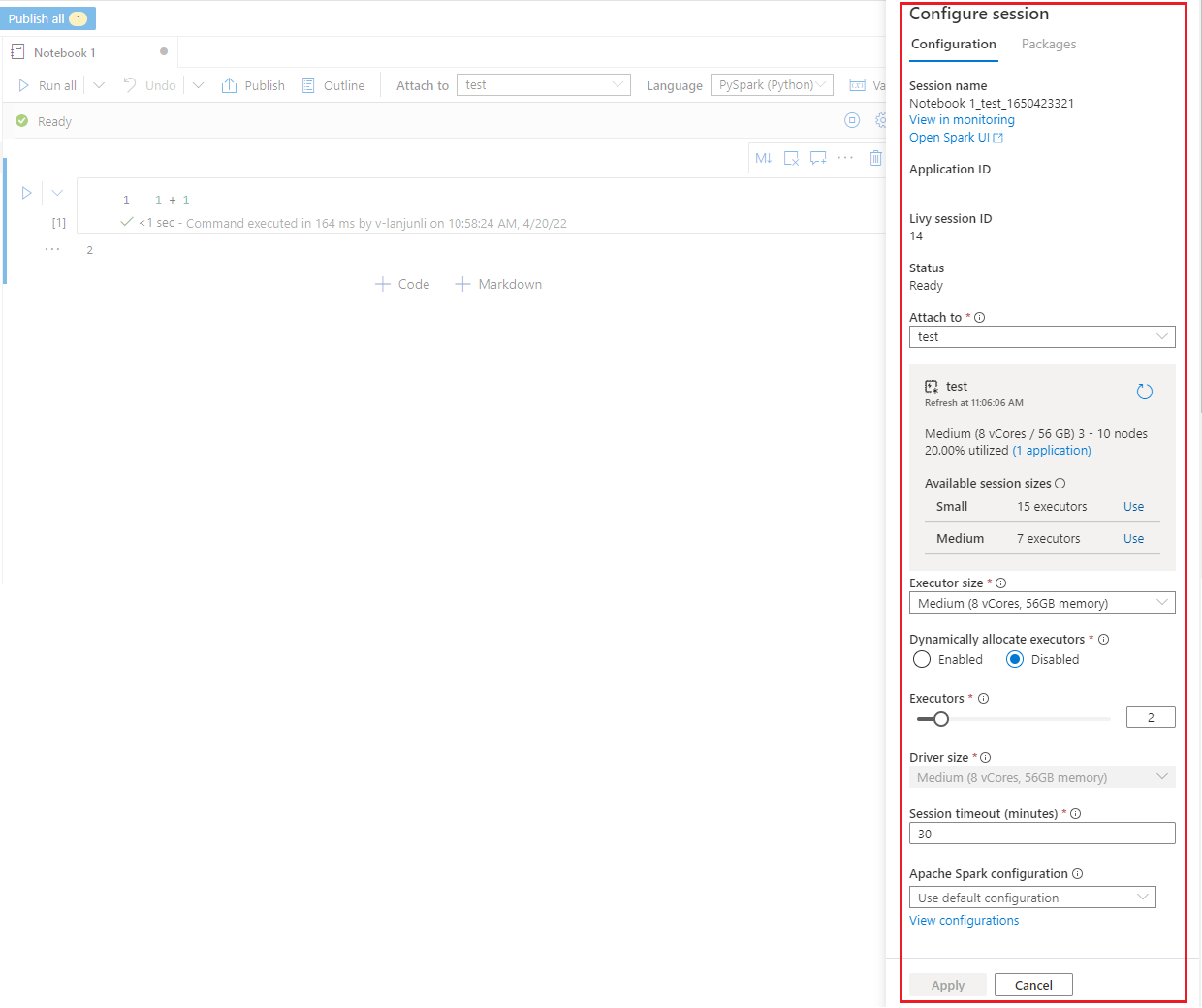
在“配置会话”窗格中,可以为当前 Spark 会话指定超时持续时间、执行器数量和执行器的大小。 重启 Spark 会话,以使配置更改生效。 缓存的所有笔记本变量都将被清除。
还可以从 Apache Spark 配置创建配置,或选择现有配置。 有关详细信息,请参阅 管理 Apache Spark 配置。
用于配置 Spark 会话的 magic 命令
还可以通过 magic 命令 %%configure 指定 Spark 会话设置。 要使设置生效,请重启 Spark 会话。
建议在笔记本开头运行 %%configure。 下面是一个示例。 有关有效参数的完整列表,请参阅 GitHub 上的 Livy 信息。
%%configure
{
//You can get a list of valid parameters to configure the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.chinacloudapi.cn/<path>/myjar1.jar"],
"conf":{
//Example of a standard Spark property. To find more available properties, go to https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of a customized property. You can specify the count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
以下是 %%configure magic 命令的一些注意事项:
- 建议使用与
%%configure中driverMemory和executorMemory相同的值。 还建议driverCores和executorCores具有相同的值。 - 可以在 Synapse 管道中使用
%%configure,但如果未在第一个代码单元格中设置它,管道运行将因无法重启会话而失败。 - 将忽略
mssparkutils.notebook.run中使用的%%configure命令,但%run <notebook>中使用的命令将继续运行。 - 必须在
"conf"正文中使用标准 Spark 配置属性。 不支持 Spark 配置属性的第一级引用。 - 某些特殊的 Spark 属性不会在
"conf"正文中生效,包括"spark.driver.cores"、"spark.executor.cores"、"spark.driver.memory"、"spark.executor.memory"和"spark.executor.instances"。
管道中的参数化会话配置
可以使用参数化会话配置将 %%configure magic 命令中的值替换为管道运行(笔记本活动)参数。 准备 %%configure 代码单元格时,可以使用如下所示的对象替代默认值:
{
"activityParameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
以下示例显示了 4 和 "2000" 的默认值,这些默认值也是可配置的:
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
如果直接在交互模式下运行笔记本,或者管道笔记本活动没有提供与 "activityParameterName" 匹配的参数,笔记本将使用默认值。
在管道运行模式下,可以使用“设置”选项卡来配置管道笔记本活动的设置。
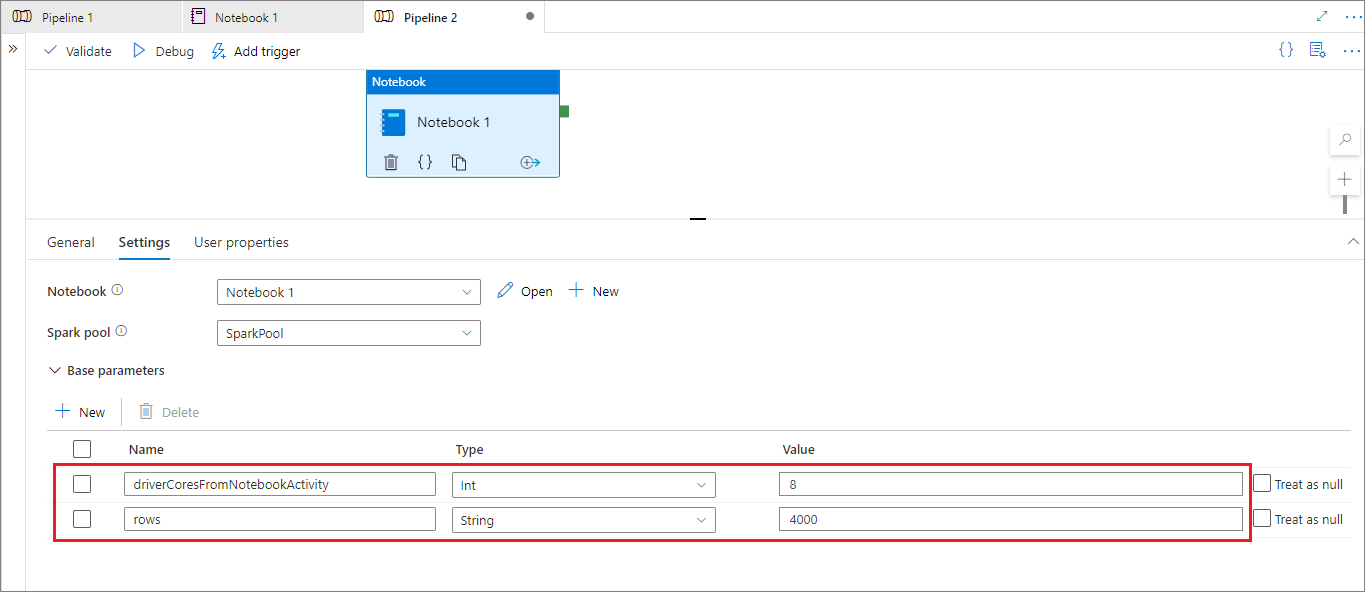
如果要更改会话配置,管道笔记本活动参数的名称应与笔记本中的 activityParameterName 相同。 在此示例中,在管道运行期间,8 替换 %%configure 中的 driverCores,4000 替换 livy.rsc.sql.num-rows。
如果在使用 %%configure magic 命令后管道运行失败,可以在笔记本的交互模式下运行 %%configure magic 单元格来查找更多错误信息。
将数据引入笔记本
如以下代码示例所示,可以从 Azure Data Lake Storage Gen 2、Azure Blob 存储和 SQL 池加载数据。
从 Azure Data Lake Storage Gen2 读取 CSV 文件作为 Spark 数据帧
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.chinacloudapi.cn/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
从 Azure Blob 存储读取 CSV 文件作为 Spark 数据帧
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow Spark to access from Azure Blob Storage remotely
wasb_path = 'wasbs://%s@%s.blob.core.chinacloudapi.cn/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.chinacloudapi.cn' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
从主存储帐户读取数据
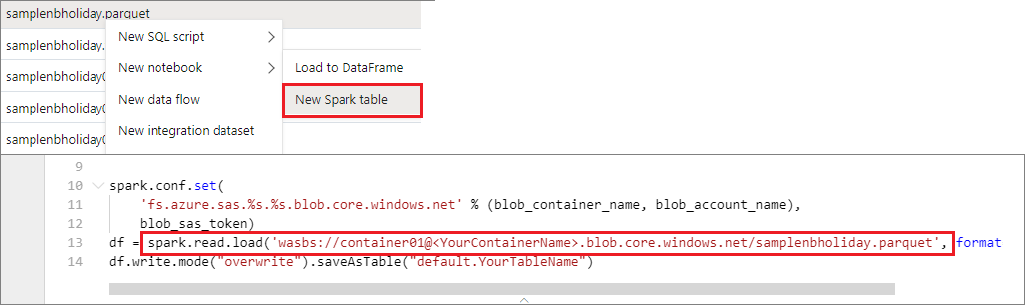
你可以直接访问主存储帐户中的数据。 无需提供密钥。 在数据资源管理器中,右键单击某个文件,然后选择“新建笔记本”以查看自动生成了数据提取器的新笔记本。
使用 IPython 小组件
这些小组件是事件化的 Python 对象,它们在浏览器中具有表示形式,通常表示为滑块或文本框等控件。 IPython 小组件仅在 Python 环境中工作。 目前不支持其他语言(例如 Scala、SQL 或 C#)。
IPython 小组件的使用步骤
导入
ipywidgets模块以使用 Jupyter 小组件框架:import ipywidgets as widgets使用顶级
display函数来呈现小组件,或者在代码单元格的最后一行保留widget类型的表达式:slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() slider运行该单元。 小组件显示在输出区域。
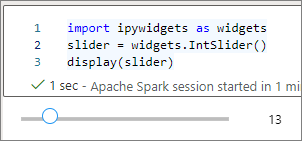
可以使用多个 display() 调用来多次呈现同一小组件实例,但它们会相互保持同步。
slider = widgets.IntSlider()
display(slider)
display(slider)
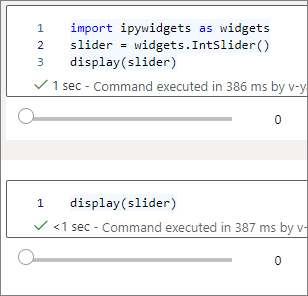
若要呈现两个彼此独立的小组件,请创建两个小组件实例:
slider1 = widgets.IntSlider()
slider2 = widgets.IntSlider()
display(slider1)
display(slider2)
支持的小组件
| 小组件类型 | 小组件 |
|---|---|
| 数字 | IntSlider,FloatSlider,FloatLogSlider,IntRangeSlider,FloatRangeSlider,IntProgress,FloatProgress,BoundedIntText,BoundedFloatText,IntText,FloatText |
| 布尔 | ToggleButton,Checkbox,Valid |
| 选择 | Dropdown,RadioButtons,Select,SelectionSlider,SelectionRangeSlider,ToggleButtons,SelectMultiple |
| 字符串 | Text,Text area,Combobox,Password,Label,HTML,HTML Math,Image,Button |
| 播放(动画) | Date picker,Color picker,Controller |
| 容器/布局 | Box,HBox,VBox,GridBox,Accordion,Tabs,Stacked |
已知限制
下表列出了当前不支持的小组件以及解决方法:
功能 解决方法 Output小组件可以改用 print()函数将文本写入stdout。widgets.jslink()可以使用 widgets.link()函数链接两个相似的小组件。FileUpload小组件无可用项。 Azure Synapse Analytics 提供的全局
display函数不支持在一次调用(即display(a, b))中显示多个小组件。 此行为不同于 IPythondisplay函数。如果关闭包含 IPython 小组件的笔记本,则在再次运行相应的单元格之前,你无法看到该小组件,也无法与之交互。
保存笔记本
可以在工作区中保存单个笔记本或所有笔记本:
要保存对单个笔记本所做的更改,请在笔记本命令栏上选择“发布”按钮。

要保存工作区中的所有笔记本,请在工作区命令栏上选择“发布所有”按钮。

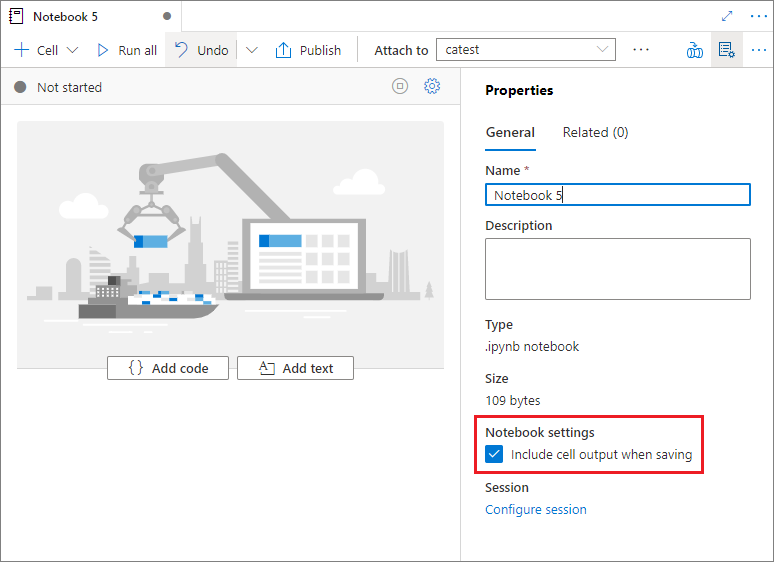
在笔记本的“属性”窗格上,可以配置保存时是否包括单元格输出。
使用 magic 命令
可以在 Synapse 笔记本中使用熟悉的 Jupyter magic 命令。 查看以下列表,其中列出了目前可用的 magic 命令。 告诉我们你在 GitHub 上的用例,以便我们可以继续创建更多 magic 命令来满足你的需求。
注意
Synapse 管道仅支持以下 magic 命令:%%pyspark、%%spark、%%csharp、%%sql。
行的可用 magic 命令:
%lsmagic,%time,%timeit,%history,%run,%load
单元格的可用 magic 命令:
%%time,%%timeit,%%capture,%%writefile,%%sql,%%pyspark,%%spark,%%csharp,%%html,%%configure
引用未发布的笔记本
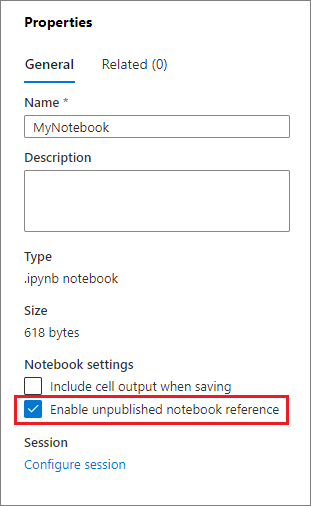
如果要在本地调试,引用未发布的笔记本会很有帮助。 启用此功能时,笔记本运行会提取 Web 缓存中的当前内容。 如果运行包含引用笔记本语句的单元格,则引用当前笔记本浏览器中的演示笔记本,而不是群集中的已保存版本。 其他笔记本可以在笔记本编辑器中引用更改,而无需您发布更改。 通过使用此方法,可以在开发或调试过程中防止常见库的污染。
可以通过选中“属性”窗格上的相应复选框来启用引用未发布的笔记本。
下表比较了这两种情形。 尽管此处 %run 和 mssparkutils.notebook.run 具有相同的行为,但表使用 %run 作为示例。
| 案例 | 禁用 | 启用 |
|---|---|---|
Nb1(已发布)%run Nb1 |
运行 Nb1 的已发布版本 | 运行 Nb1 的已发布版本 |
Nb1(新)%run Nb1 |
错误 | 运行新的 Nb1 |
Nb1(之前发布的,已编辑)%run Nb1 |
运行 Nb1 的已发布版本 | 运行 Nb1 的已编辑版本 |
综上所述:
- 如果禁用引用未发布的笔记本,请始终运行已发布版本。
- 如果启用引用未发布的笔记本,则引用运行始终采用笔记本 UX 上显示的当前版本的笔记本。
管理活动会话
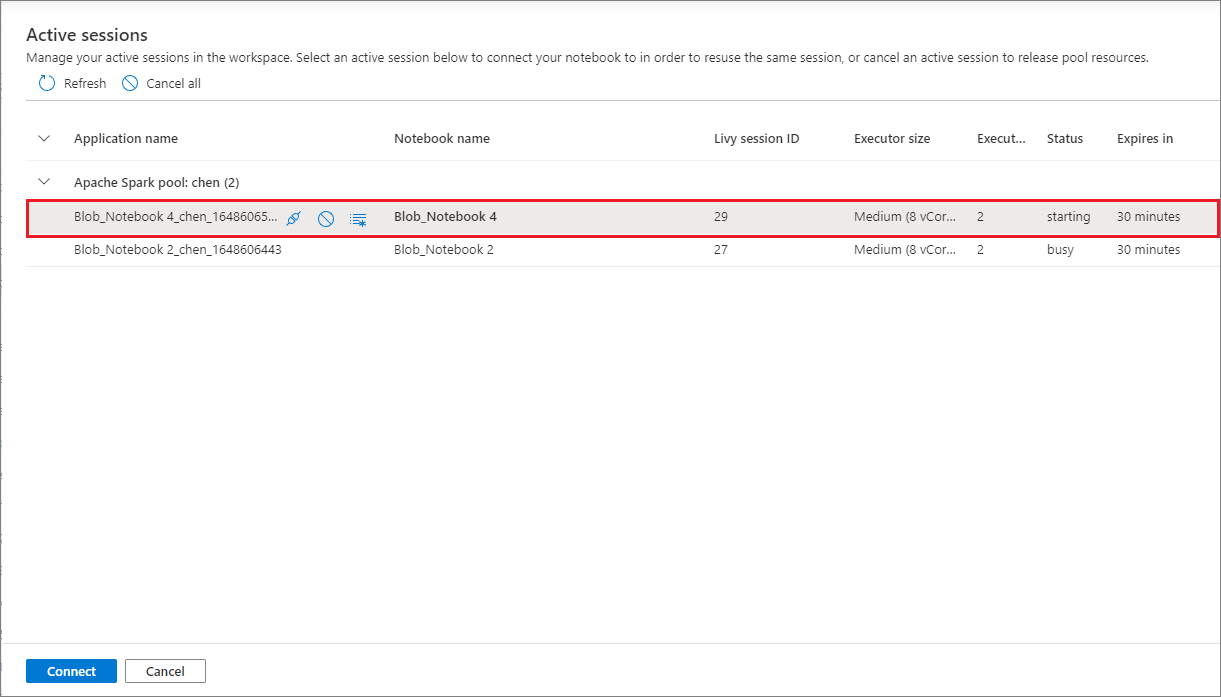
可以重复使用笔记本会话,而无需启动新会话。 在 Synapse 笔记本中,可以在单个列表中管理活动会话。 若要打开列表,请选择省略号 (...),然后选择“管理会话”。
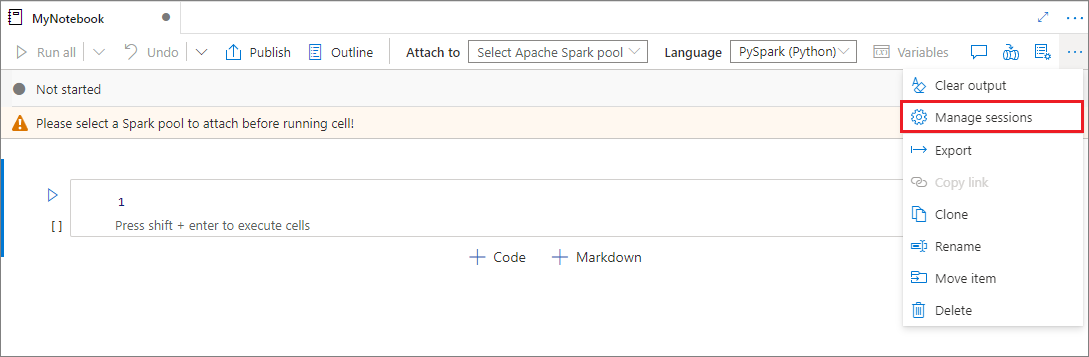
“活动会话”窗格列出了从笔记本启动的当前工作区中的所有会话。 该列表显示会话信息和相应的笔记本。 可以在此处执行“与笔记本分离”、“停止会话”和“在监视中查看”操作。 还可以将所选笔记本连接到从另一个笔记本启动的活动会话。 然后,会话与上一个笔记本(如果它未空闲)分离,并附加到当前笔记本。
使用笔记本中的 Python 日志
可以查找 Python 日志,并使用以下示例代码设置不同的日志级别和格式:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize the log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# Logger that uses the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# Logger that uses the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
查看输入命令的历史记录
Synapse 笔记本支持 magic 命令 %history 打印当前会话的输入命令历史记录。 %history magic 命令类似于标准 Jupyter IPython 命令,适用于笔记本中的多语言上下文。
%history [-n] [range [range ...]]
在前面的代码中,-n 是打印执行编号。 range 值可以为:
N:打印Nth执行的单元格的代码。M-N:打印从Mth到Nth执行的单元格的代码。
例如,若要打印从第一个到第二个执行单元格的输入历史记录,请使用 %history -n 1-2。
集成笔记本
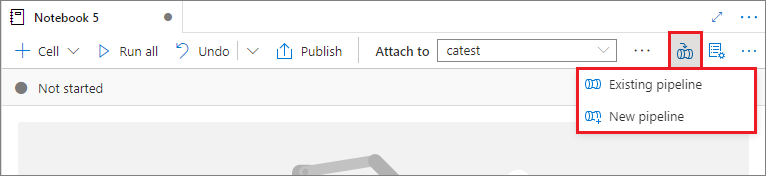
将笔记本添加到管道
要将笔记本添加到现有管道或创建新管道,请选择右上角的“添加到管道”按钮。
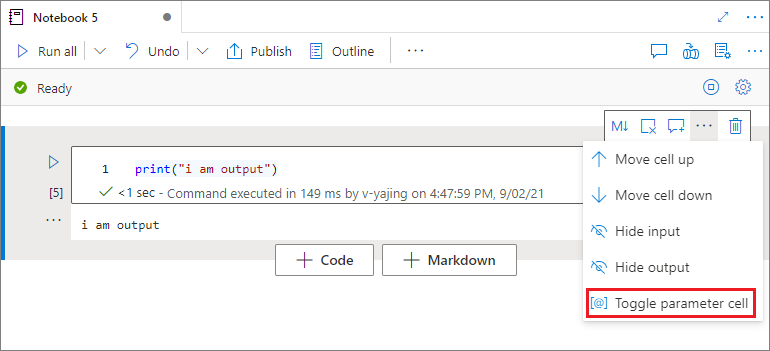
指定参数单元格
要对笔记本进行参数化,请选择省略号 (...) 以访问单元格工具栏上的更多命令。 然后选择“切换参数单元格”,将该单元格指定为参数单元格。
Azure 数据工厂查找参数单元格,并将此单元格作为执行时传入的参数的默认单元格。 执行引擎将使用输入参数在参数单元格下面添加新的单元格,以覆盖默认值。
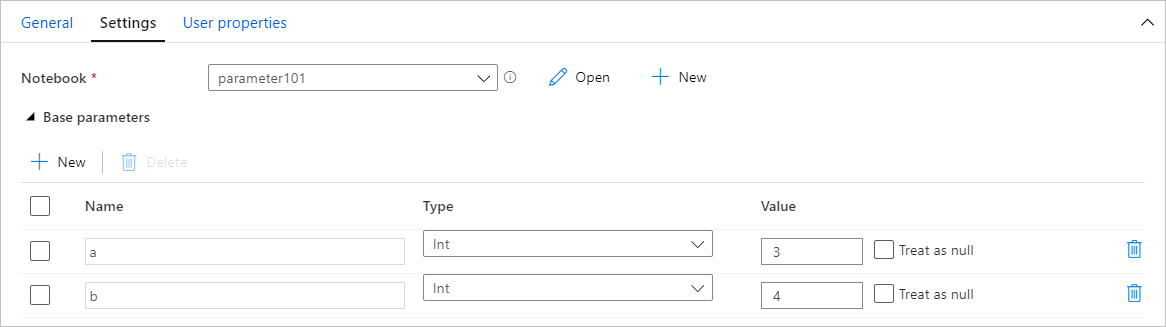
从管道分配参数值
使用参数创建笔记本后,可以使用 Synapse 笔记本活动从管道中运行该笔记本。 将活动添加到管道画布后,便可以在“设置”选项卡的“基参数”部分设置参数值。
使用快捷键
与 Jupyter Notebooks 类似,Synapse 笔记本具有模式用户界面。 键盘根据笔记本单元格的具体模式执行不同的任务。 Synapse 笔记本支持代码单元格的以下两种模式:
命令模式:当没有文本光标提示键入时,单元格处于命令模式。 当单元格处于命令模式时,可以将笔记本作为一个整体进行编辑,但不能键入单独的单元格。 选择 Esc 键或使用鼠标选择单元格编辑器区域外部,进入命令模式。

编辑模式:当单元格处于编辑模式时,文本光标会提示键入单元格。 选择 Enter 键或使用鼠标选择单元格的编辑器区域,进入编辑模式。

命令模式下的快捷键
| 操作 | Synapse 笔记本快捷方式 |
|---|---|
| 运行当前单元格并选择下方的单元格 | Shift+Enter |
| 运行当前单元格并在下方插入 | Alt+Enter |
| 运行当前单元格 | Ctrl+Enter |
| 选择上方的单元格 | 向上 |
| 选择下方的单元格 | 向下 |
| 选择上一个单元格 | K |
| 选择下一个单元格 | J |
| 在上方插入单元格 | A |
| 在下方插入单元格 | B |
| 删除所选单元格 | Shift+D |
| 切换到编辑模式 | Enter |
编辑模式下的快捷键
| 操作 | Synapse 笔记本快捷方式 |
|---|---|
| 上移光标 | 向上 |
| 下移光标 | 向下 |
| 撤消 | Ctrl+Z |
| 重做 | Ctrl+Y |
| 注释/撤销注释 | Ctrl+/ |
| 删除插入提示之前的字 | Ctrl+Backspace |
| 删除插入提示之后的字 | Ctrl+Delete |
| 转到单元格开头 | Ctrl+Home |
| 转到单元格末尾 | Ctrl+End |
| 左移一个字 | Ctrl+Left |
| 右移一个字 | Ctrl+Right |
| 全选 | Ctrl+A |
| 缩进 | Ctrl +] |
| 取消缩进 | Ctrl+[ |
| 切换到命令模式 | Esc |