本教程演示如何使用 Synapse Studio 创建 Apache Spark 作业定义,然后将其提交到无服务器 Apache Spark 池。
本教程涵盖以下任务:
- 为 PySpark (Python) 创建 Apache Spark 作业定义
- 为 Spark (Scala) 创建 Apache Spark 作业定义
- 为 .NET Spark (C#/F#) 创建 Apache Spark 作业定义
- 通过导入 JSON 文件创建作业定义
- 将 Apache Spark 作业定义文件导出到本地
- 以批处理作业形式提交 Apache Spark 作业定义
- 将 Apache Spark 作业定义添加到管道
先决条件
在开始学习本教程之前,请确保满足以下要求:
- 一个 Azure Synapse Analytics 工作区。 有关说明,请参阅创建 Azure Synapse Analytics 工作区。
- 无服务器 Apache Spark 池。
- ADLS Gen2 存储帐户。 你需要是所要使用的 ADLS Gen2 文件系统的存储 Blob 数据参与者。 如果还不是该所有者,则需要手动添加权限。
- 如果不想使用工作区默认存储,请链接 Synapse Studio 中所需的 ADLS Gen2 存储帐户。
为 PySpark (Python) 创建 Apache Spark 作业定义
在本部分中,为 PySpark (Python) 创建 Apache Spark 作业定义。
打开 Synapse Studio。
可转到创建 Apache Spark 作业定义的示例文件下载 python.zip 的示例文件,然后将压缩包解压缩,并提取 wordcount.py 和 shakespeare.txt 文件 。
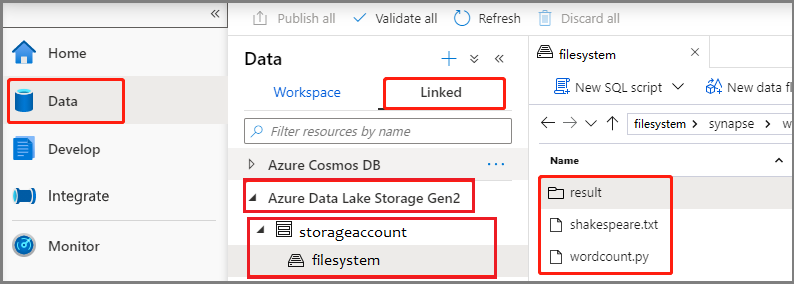
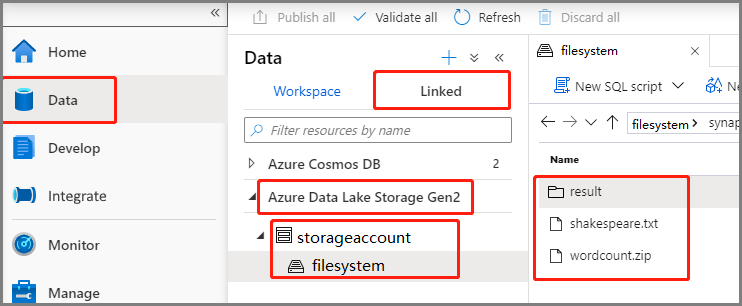
选择“数据”-“已链接”->“Azure Data Lake Storage Gen2”,然后将“wordcount.py”和“shakespeare.txt”上传到 ADLS Gen2 文件系统。
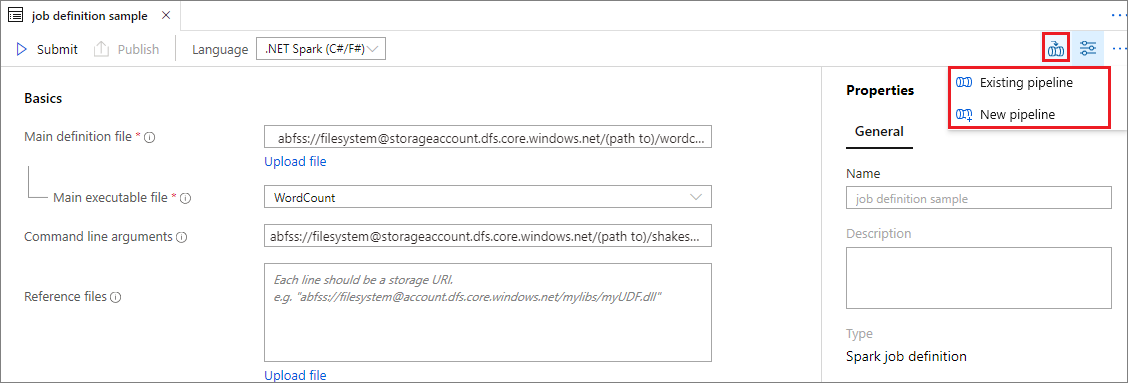
依次选择“开发”中心、“+”图标,然后选择“Spark 作业定义”以新建 Spark 作业定义 。
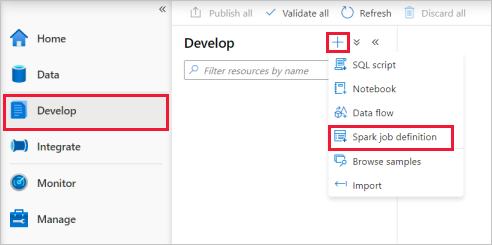
从 Apache Spark 作业定义主窗口中的“语言”下拉列表中选择“PySpark (Python)”。
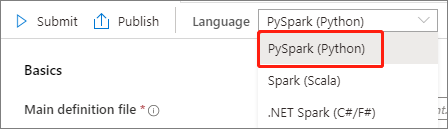
填写 Apache Spark 作业定义的信息。
属性 说明 作业定义名称 输入 Apache Spark 作业定义的名称。 在发布作业定义之前,随时可以更新此名称。
示例:job definition sample主定义文件 用于作业的主文件。 从存储中选择一个 PY 文件。 可以选择“上传文件”以将文件上传到存储帐户。
示例:abfss://…/path/to/wordcount.py命令行参数 作业的可选参数。
示例:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
注意: 示例作业定义的两个参数用空格分隔。引用文件 用于主定义文件中的引用的其他文件。 可以选择“上传文件”以将文件上传到存储帐户。 Spark 池 作业将提交到选定的 Apache Spark 池。 Spark 版本 正在运行 Apache Spark 池的 Apache Spark 版本。 执行程序 要在作业的指定 Apache Spark 池中提供的执行程序数目。 执行程序大小 作业的指定 Apache Spark 池中提供的执行程序要使用的核心数和内存量。 驱动程序大小 作业的指定 Apache Spark 池中提供的驱动程序要使用的核心数和内存量。 Apache Spark 配置 通过添加以下属性来自定义配置。 如果未添加属性,Azure Synapse 将使用默认值(如果适用)。 
选择“发布”以保存 Apache Spark 作业定义。

为 Apache Spark(Scala) 创建 Apache Spark 作业定义
在本部分中,为 Apache Spark(Scala) 创建 Apache Spark 作业定义。
可转到创建 Apache Spark 作业定义的示例文件下载 scala.zip 的示例文件,然后将压缩包解压缩,并提取 wordcount.jar 和 shakespeare.txt 文件 。
选择“数据”-“已链接”->“Azure Data Lake Storage Gen2”,然后将“wordcount.jar”和“shakespeare.txt”上传到 ADLS Gen2 文件系统。
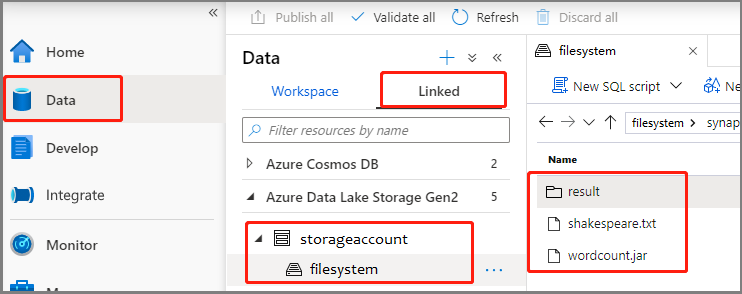
依次选择“开发”中心、“+”图标,然后选择“Spark 作业定义”以新建 Spark 作业定义 。 (示例图像与“为 PySpark 创建 Apache Spark 作业定义 (Python)”的步骤 4 相同。)
从 Apache Spark 作业定义主窗口中的“语言”下拉列表中选择“Spark(Scala)”。
填写 Apache Spark 作业定义的信息。 可复制示例信息。
属性 说明 作业定义名称 输入 Apache Spark 作业定义的名称。 在发布作业定义之前,随时可以更新此名称。
示例:scala主定义文件 用于作业的主文件。 从存储中选择一个 JAR 文件。 可以选择“上传文件”以将文件上传到存储帐户。
示例:abfss://…/path/to/wordcount.jar主类名 主定义文件中的完全限定标识符或主类。
示例:WordCount命令行参数 作业的可选参数。
示例:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
注意: 示例作业定义的两个参数用空格分隔。引用文件 用于主定义文件中的引用的其他文件。 可以选择“上传文件”以将文件上传到存储帐户。 Spark 池 作业将提交到选定的 Apache Spark 池。 Spark 版本 正在运行 Apache Spark 池的 Apache Spark 版本。 执行程序 要在作业的指定 Apache Spark 池中提供的执行程序数目。 执行程序大小 作业的指定 Apache Spark 池中提供的执行程序要使用的核心数和内存量。 驱动程序大小 作业的指定 Apache Spark 池中提供的驱动程序要使用的核心数和内存量。 Apache Spark 配置 通过添加以下属性来自定义配置。 如果未添加属性,Azure Synapse 将使用默认值(如果适用)。 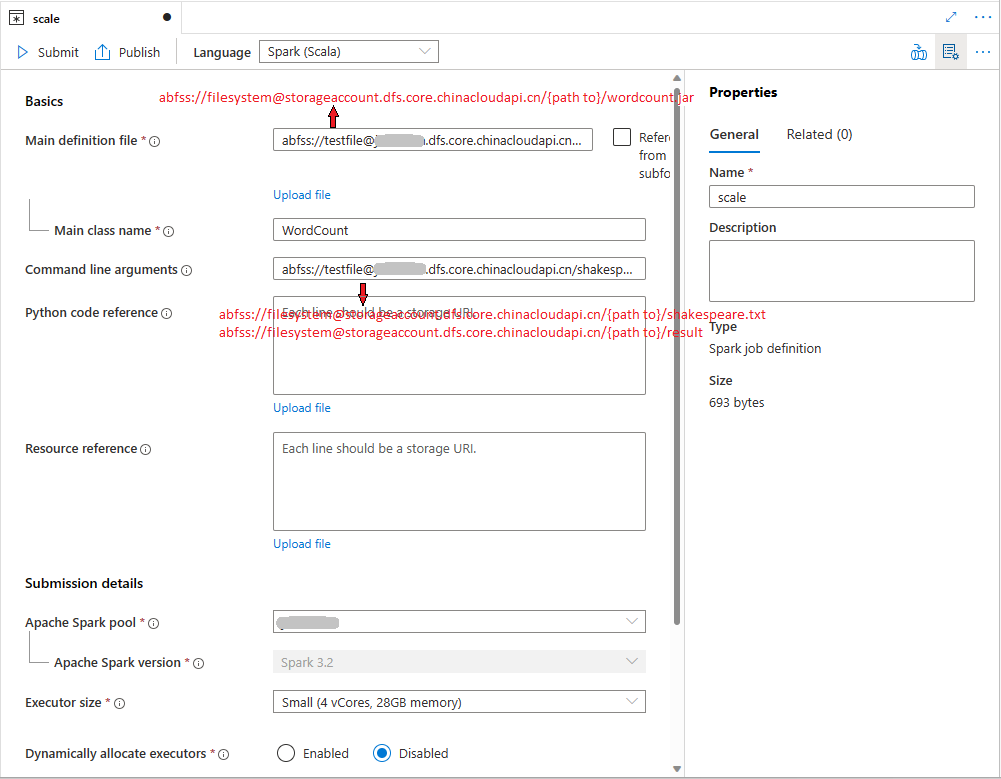
选择“发布”以保存 Apache Spark 作业定义。

为 .NET Spark(C#/F#) 创建 Apache Spark 作业定义
在本部分中,为 .NET Spark(C#/F#) 创建 Apache Spark 作业定义。
可转到创建 Apache Spark 作业定义的示例文件下载 dotnet.zip 的示例文件,然后将压缩包解压缩,并提取 wordcount.zip 和 shakespeare.txt 文件 。
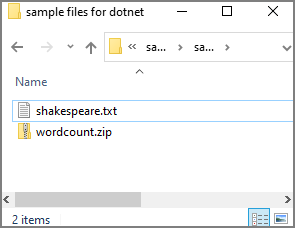
选择“数据”-“已链接”->“Azure Data Lake Storage Gen2”,然后将“wordcount.zip”和“shakespeare.txt”上传到 ADLS Gen2 文件系统。
依次选择“开发”中心、“+”图标,然后选择“Spark 作业定义”以新建 Spark 作业定义 。 (示例图像与“为 PySpark 创建 Apache Spark 作业定义 (Python)”的步骤 4 相同。)
从 Apache Spark 作业定义主窗口中的“语言”下拉列表中选择“.NET Spark(C#/F#)”。
填写 Apache Spark 作业定义的信息。 可复制示例信息。
属性 说明 作业定义名称 输入 Apache Spark 作业定义的名称。 在发布作业定义之前,随时可以更新此名称。
示例:dotnet主定义文件 用于作业的主文件。 从存储中选择包含 .NET for Apache Spark 应用程序的 ZIP 文件(即,主可执行文件、包含用户定义的函数的 DLL,以及其他所需文件)。 可以选择“上传文件”以将文件上传到存储帐户。
示例:abfss://…/path/to/wordcount.zip主可执行文件 主定义 ZIP 文件中的主可执行文件。
示例:WordCount命令行参数 作业的可选参数。
示例:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
注意: 示例作业定义的两个参数用空格分隔。引用文件 工作器节点所需的其他文件(即,依赖的 jar、其他用户定义的函数 DLL,以及其他配置文件),用于执行主定义 ZIP 文件中不包含的 .NET for Apache Spark 应用程序。 可以选择“上传文件”以将文件上传到存储帐户。 Spark 池 作业将提交到选定的 Apache Spark 池。 Spark 版本 正在运行 Apache Spark 池的 Apache Spark 版本。 执行程序 要在作业的指定 Apache Spark 池中提供的执行程序数目。 执行程序大小 作业的指定 Apache Spark 池中提供的执行程序要使用的核心数和内存量。 驱动程序大小 作业的指定 Apache Spark 池中提供的驱动程序要使用的核心数和内存量。 Apache Spark 配置 通过添加以下属性来自定义配置。 如果未添加属性,Azure Synapse 将使用默认值(如果适用)。 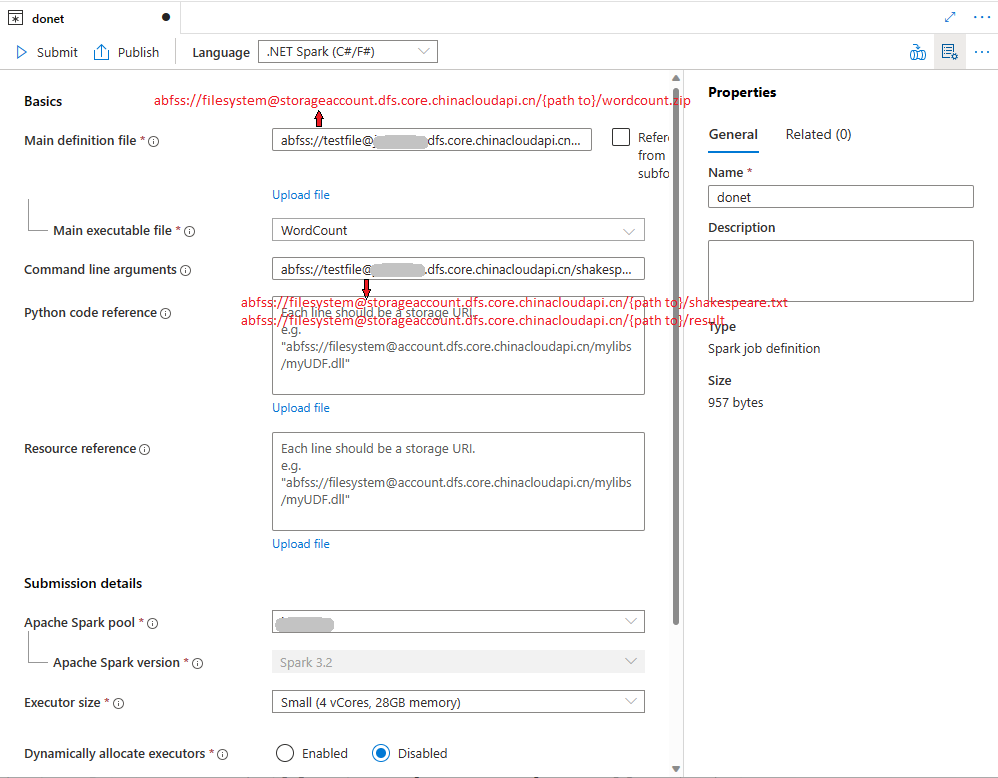
选择“发布”以保存 Apache Spark 作业定义。

注意
对于 Apache Spark 配置,如果 Apache Spark 配置 Apache Spark 作业定义不执行任何特殊操作,在运行该作业时,将会使用默认配置。
通过导入 JSON 文件创建 Apache Spark 作业定义
可以从 Apache Spark 作业定义资源管理器的“操作”(...) 菜单将现有的本地 JSON 文件导入 Azure Synapse 工作区,以创建新的 Apache Spark 作业定义。
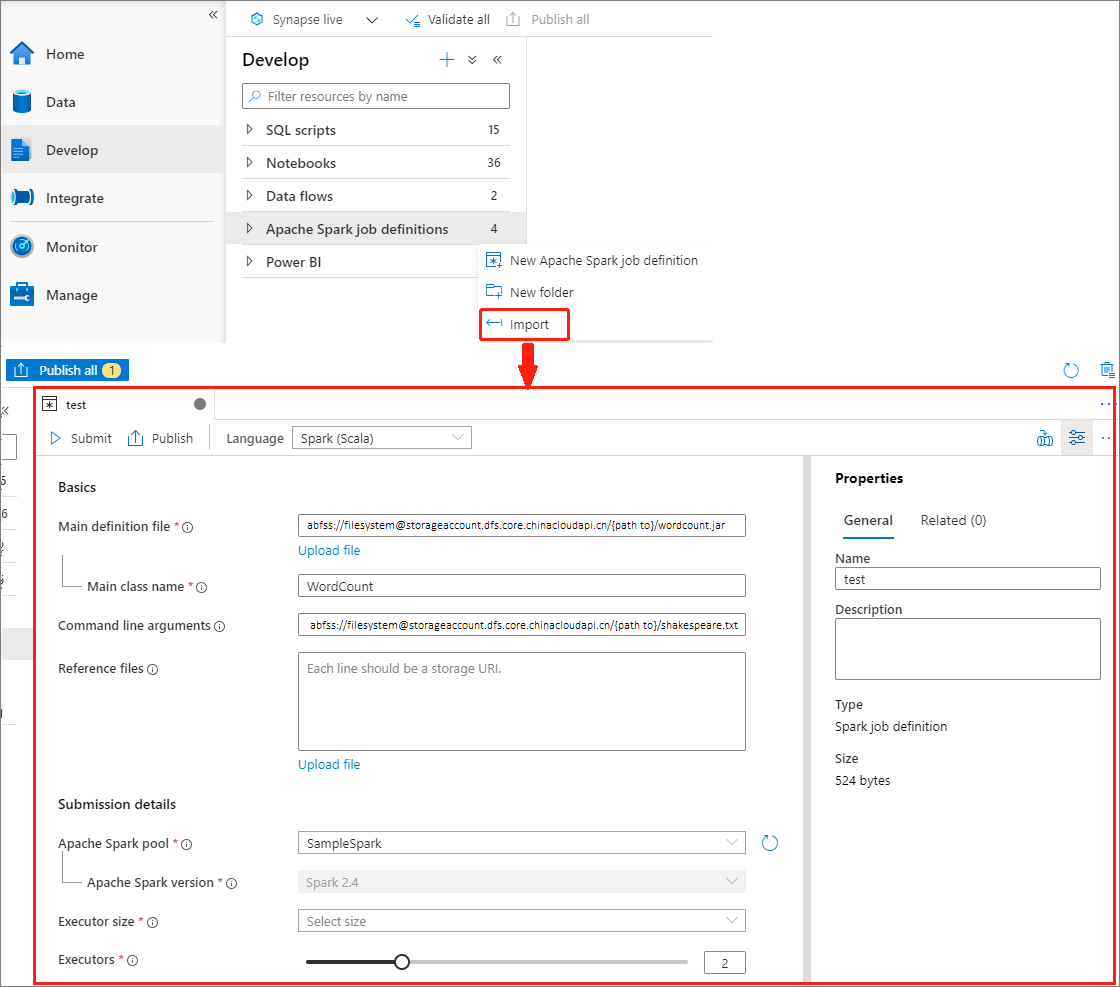
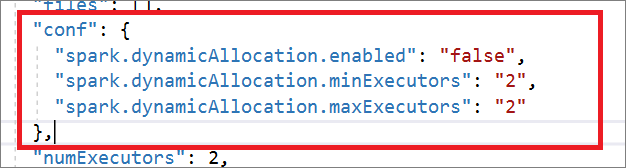
Spark 作业定义与 Livy API 完全兼容。 可以在本地 JSON 文件中为其他 Livy 属性 (Livy Docs - REST API (apache.org) 添加其他参数。 还可以在配置属性中指定与 Spark 配置相关的参数,如下所示。 然后,可以重新导入 JSON 文件,为批处理作业创建新的 Apache Spark 作业定义。 Spark 定义导入的示例 JSON:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "abfss://filesystem@storageaccount.dfs.core.chinacloudapi.cn/{path to}/wordcount.jar",
"className": "WordCount",
"args": [
"abfss://filesystem@storageaccount.dfs.core.chinacloudapi.cn/{path to}/shakespeare.txt"
],
"jars": [],
"files": [],
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
导出现有的 Apache Spark 作业定义文件
可以从文件资源管理器的“操作”(...) 菜单将现有的 Apache Spark 作业定义文件导出到本地。 可以进一步更新 JSON 文件以获取其他 Livy 属性,并在必要时将其重新导入以创建新的作业定义。
以批处理作业形式提交 Apache Spark 作业定义
创建 Apache Spark 作业定义后,可将其提交到 Apache Spark 池。 请确保你是所要使用的 ADLS Gen2 文件系统的存储 Blob 数据参与者。 如果还不是该所有者,则需要手动添加权限。
应用场景 1:提交 Apache Spark 作业定义
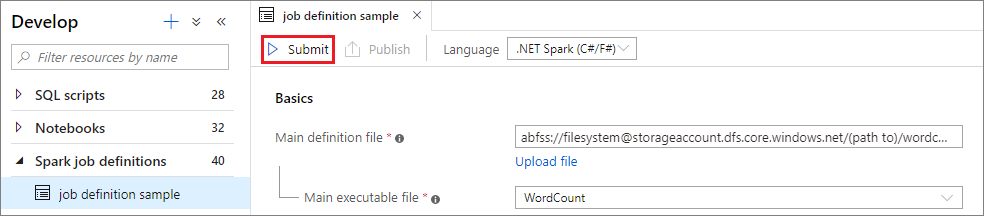
通过选择 Apache Spark 作业定义来打开其窗口。
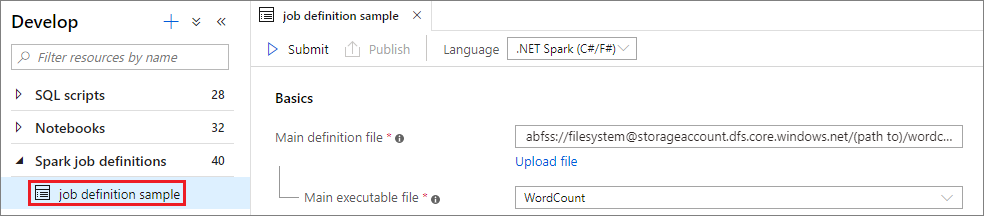
选择“提交”按钮,将项目提交到选定的 Apache Spark 池。 可选择“Spark 监视 URL”选项卡,查看 Apache Spark 应用程序的 LogQuery。
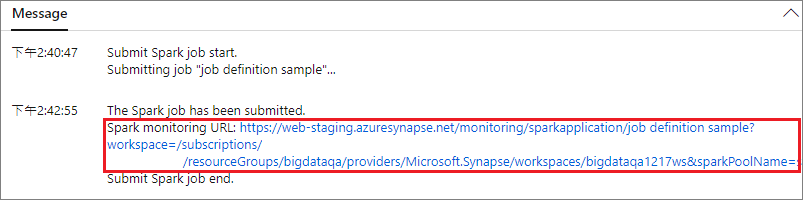
应用场景 2:查看 Apache Spark 作业运行进度
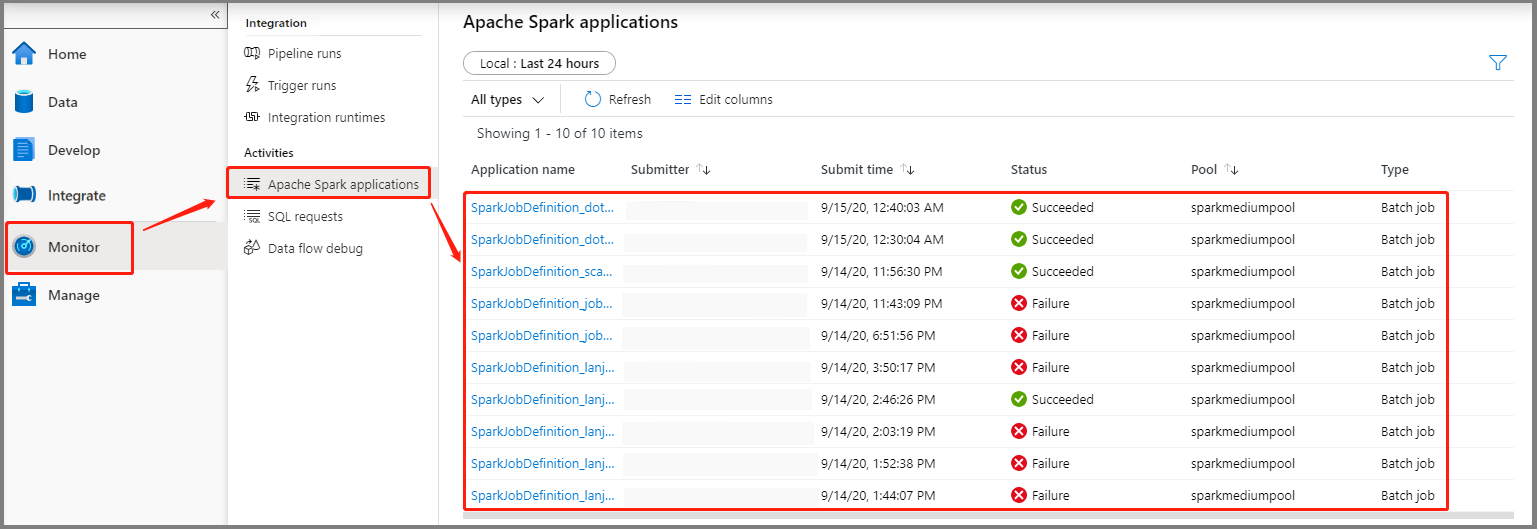
选择“监视”,然后选择“Apache Spark 应用程序”选项 。 可找到已提交的 Apache Spark 应用程序。
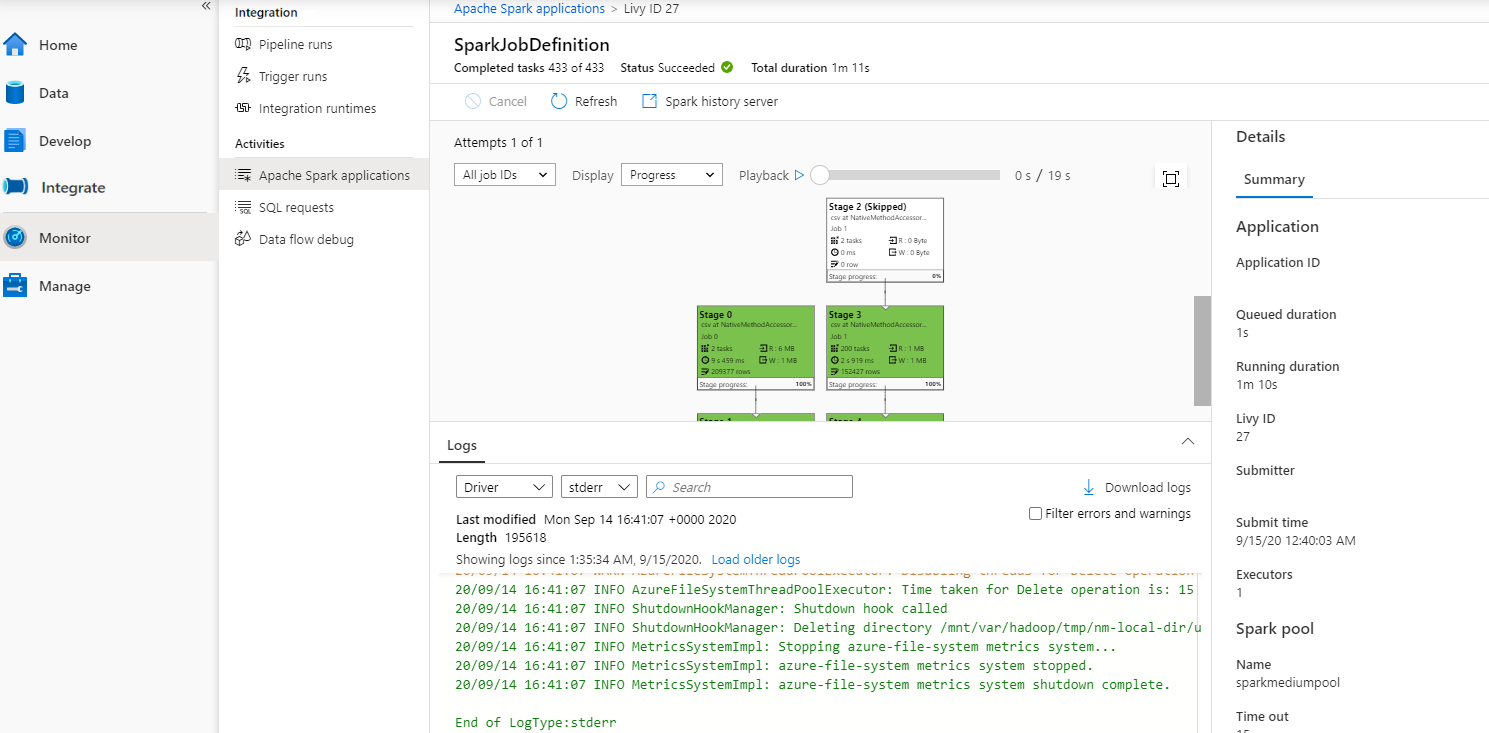
然后选择 Apache Spark 应用程序,此时会显示 SparkJobDefinition 作业窗口。 可在此处查看作业执行进度。
应用场景 3:检查输出文件
选择“数据”-“已链接”->“Azure Data Lake Storage Gen2”(hozhaobdbj),然后打开之前创建的结果文件夹,可转到结果文件夹查看是否已生成输出。
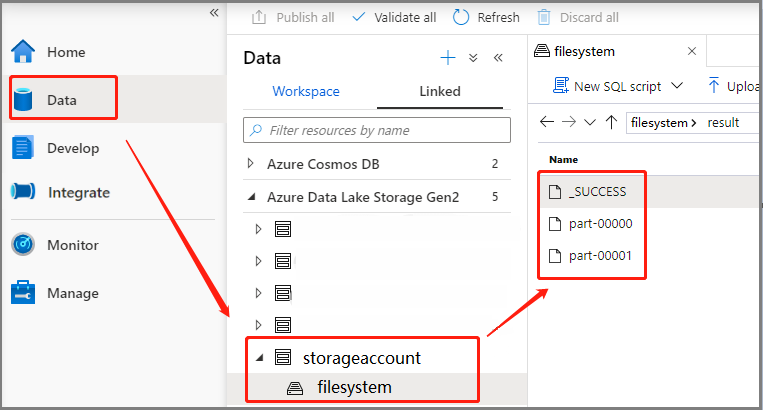
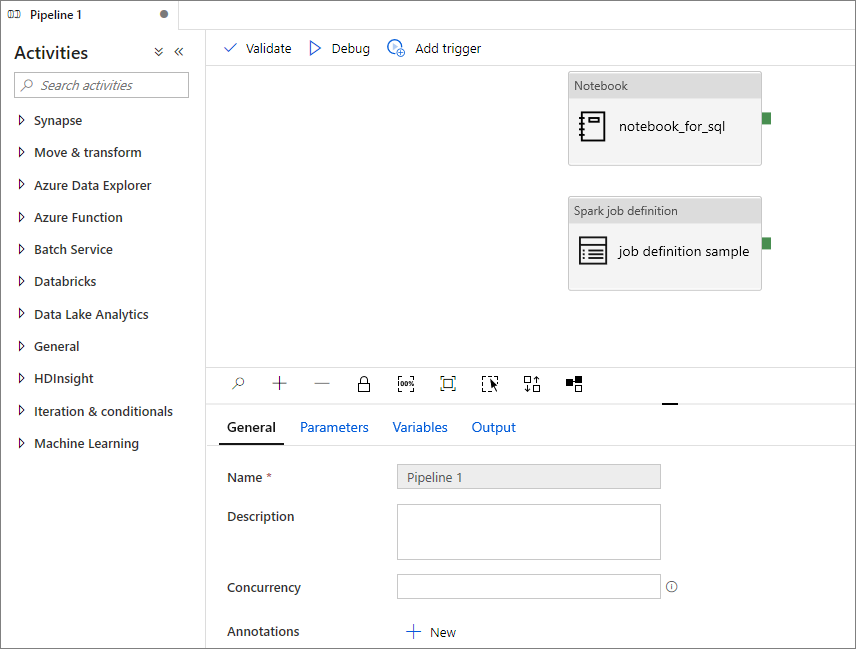
将 Apache Spark 作业定义添加到管道
在本部分中,将 Apache Spark 作业定义添加到管道。
打开现有的 Apache Spark 作业定义。
选择 Apache Spark 作业定义右上方的图标,选择“现有管道”或“新建管道” 。 有关详细信息,请参阅“管道”页面。