在确定要用于 Spark 应用程序或为其更新的 Scala、Java、R(预览版)或 Python 包后,就可将它们安装到 Spark 池中或从中移除它们。 池级别的库可用于池中运行的所有笔记本和作业。
可以通过两种主要方式在 Spark 池上安装库:
- 安装已作为工作区包上传的工作区库。
- 若要更新 Python 库,请提供 requirements.txt 或 Conda environment.yml 环境规范,以从 PyPI、Conda-Forge 等存储库中安装包。 有关详细信息,请参阅环境规范格式部分。
保存更改后,Spark 作业将运行安装并缓存生成的环境,供以后再次使用。 作业完成后,新的 Spark 作业或笔记本会话将使用更新的池库。
重要
- 如果要安装的包很大,或者需要很长时间才能完成安装,则会影响 Spark 实例的启动时间。
- 不支持更改 PySpark、Python、Scala/Java、.NET、R 或 Spark 版本。
- 不支持在已启用“数据外泄防护”的工作区中安装来自 PyPI、Conda-Forge 等外部存储库或默认 Conda 通道的包。
通过 Synapse Studio 或 Azure 门户管理包
通过 Synapse Studio 或 Azure 门户可以管理 Spark 池库。
在 Azure 门户中,导航到你的 Azure Synapse Analytics 工作区。
在 Analytics 池 部分,选择 Apache Spark 池 选项卡,然后从列表中选择一个 Spark 池。
在 Spark 池的“设置”部分选择“包”。

对于 Python 源库,请使用该页面“包”部分的文件选择器上传环境配置文件。
还可以选择其他“工作区包”,将 Jar、Wheel 或 Tar.gz 文件添加到池中。
还可以从“工作区包”部分移除已弃用的包,然后你的池将不再附加这些包。
保存更改后,将触发系统作业来安装和缓存指定的库。 此过程有助于缩短总体会话启动时间。
作业成功完成后,所有新会话都会选取更新后的池库。


重要
通过选择“强制使用新设置”选项,将结束所选 Spark 池的所有当前会话。 会话结束后,必须等待池重启。
如果未选中此设置,则需要等待当前 Spark 会话结束或手动将其停止。 会话结束后,需要让池重启。
跟踪安装进度
每次为池更新一组新的库时,都会启动系统预留的 Spark 作业。 此 Spark 作业有助于监视库的安装状态。 如果由于库冲突或其他问题而导致安装失败,Spark 池将恢复为以前的状态或默认状态。
此外,用户可以检查安装日志来识别依赖项冲突,或查看在池更新过程中安装了哪些库。
若要查看这些日志:
在 Synapse Studio 中,导航到“监视”选项卡中的 Spark 应用程序列表。
选择与您的池更新相对应的系统 Spark 应用程序任务。 这些系统作业在 SystemReservedJob-LibraryManagement 标题下运行。
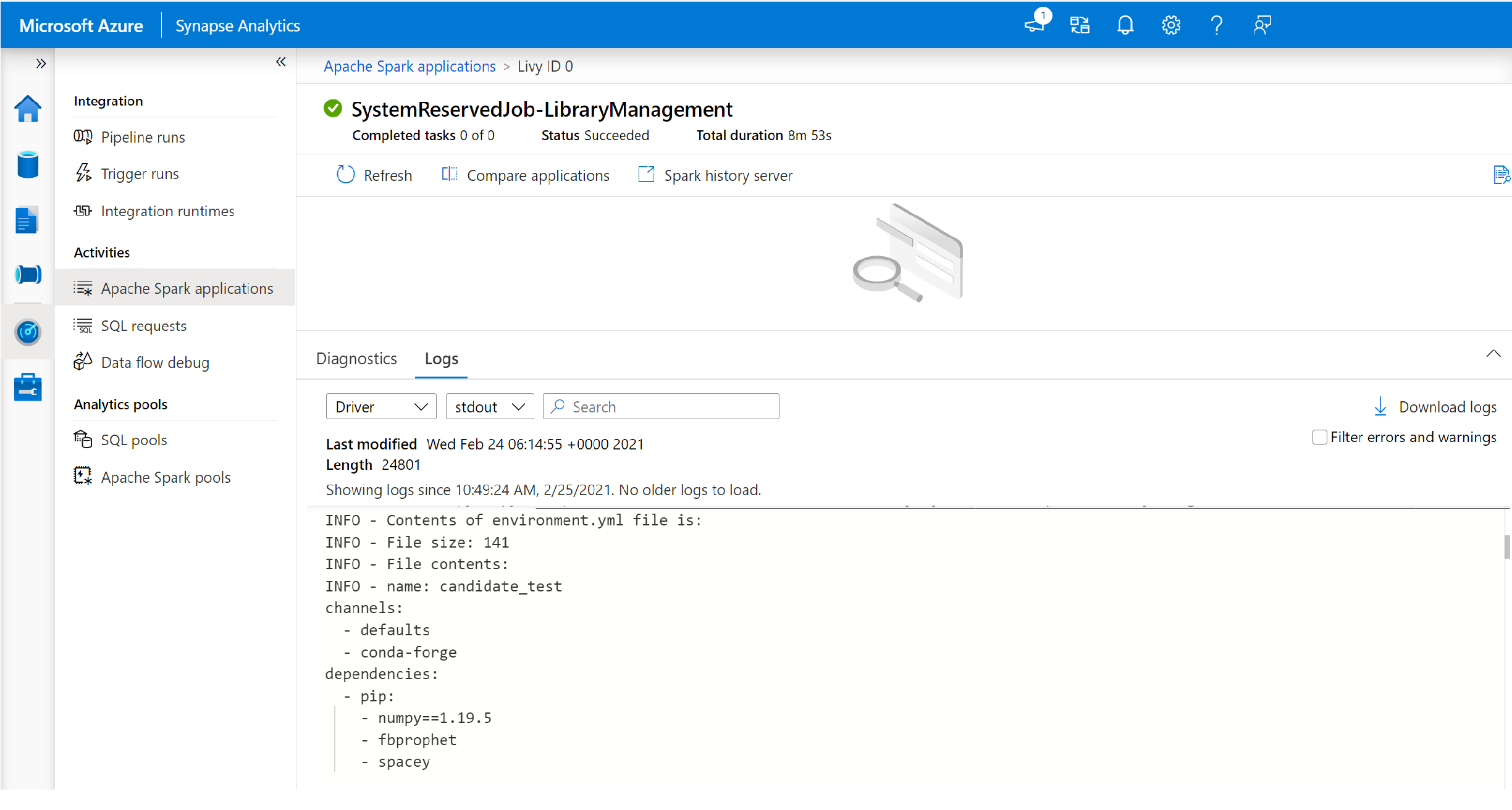
切换查看驱动程序和stdout日志。
结果包含与你的依赖项安装相关的日志。


环境规范格式
PIP requirements.txt
可以使用 requirements.txt 文件(pip freeze 命令的输出)来升级环境。 更新池时,将从 PyPI 下载此文件中列出的包。 然后,将所有依赖关系缓存并保存,以便池可以在以后重复使用。
以下代码片段显示了要求文件的格式。 PyPI 包名称将与确切的版本一起列出。 此文件遵循 pip freeze 参考文档中所述的格式。
此示例固定使用一个特定版本。
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
YML 格式
此外,可以提供 environment.yml 文件来更新池环境。 此文件中列出的包是从默认 Conda 通道、Conda-Forge 和 PyPI 下载的。 可以使用配置选项指定其他通道或删除默认通道。
此示例指定通道和 Conda/PyPI 依赖项。
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
有关从此 environment.yml 文件创建环境的详细信息,请参阅激活环境。