用户在Azure Synapse Analytics中创建 Spark 池,并根据分析工作负荷要求调整其大小。 在企业团队中,将 Spark 池用于多个数据工程过程是很常见的,池的使用情况可能因数据引入率、数据量和其他因素而异。 Spark 池可用于计算密集型数据转换以及执行数据探索过程,在这些情况下,用户可以启用“自动缩放”选项并指定最小和最大节点数,平台会根据需求在这些限制内缩放活动节点数。
通过查看应用程序级别执行程序要求,用户发现很难优化执行程序配置,因为它们在 Spark 作业执行过程的不同阶段大不相同,这也取决于不时变化的已处理数据量。 用户可以在池配置中启用“执行程序的动态分配”选项,这将根据 Spark 池中的可用节点自动将执行程序分配给 Spark 应用程序。
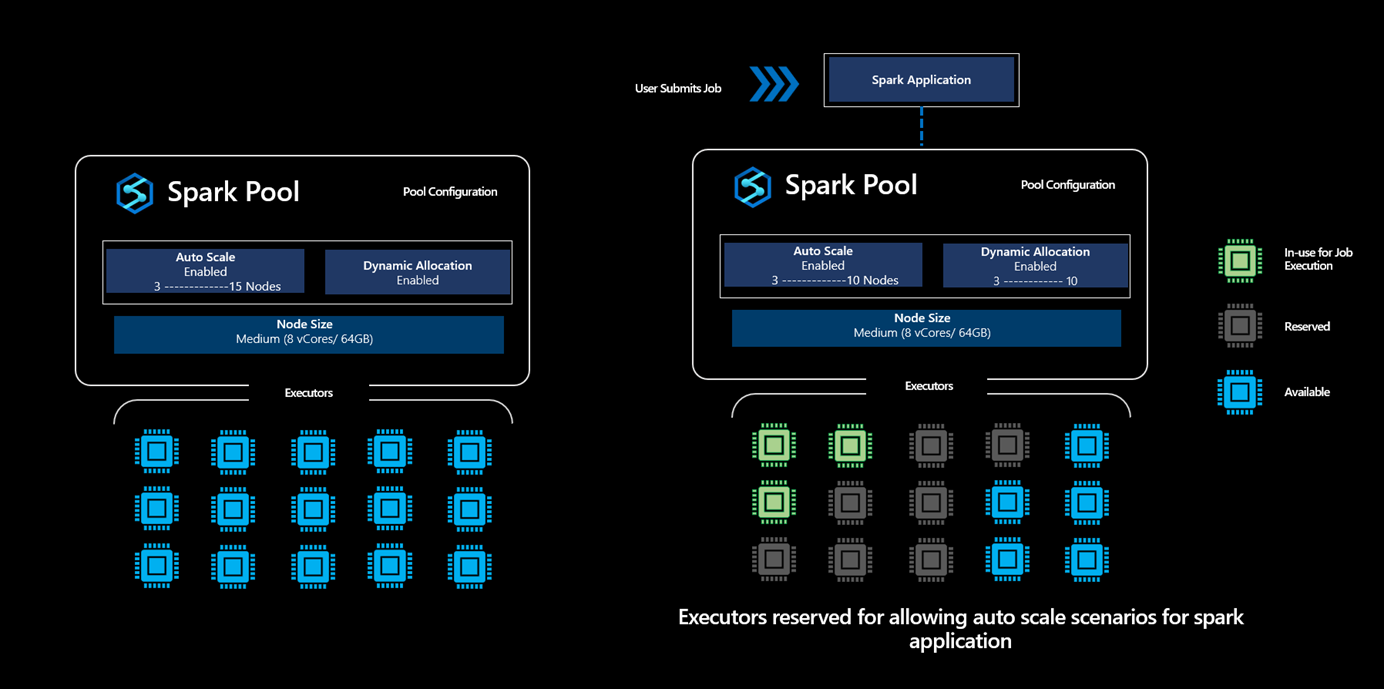
启用“动态分配”选项后,对于提交的每个 Spark 应用程序,系统会在作业提交步骤期间根据用户指定的最大节点数来保留执行程序,以支持成功的自动缩放方案。
注释
这种保守的方法允许平台在不耗尽容量的情况下从 3 个节点缩放到 10 个节点,从而为用户提供更高的作业执行可靠性。
执行程序保留意味着什么?
在 Synapse Spark 池中启用了动态分配选项的情况下,平台会根据用户为提交的任何 Spark 应用程序指定的最大限制来保留执行程序数。 仅当可用的执行程序大于保留的执行程序的最大数量时,才会接受用户提交的新作业。
重要
但是,此预留活动不会影响计费,因为用户仅针对使用的核心数计费,而不针对处于保留状态的核心数计费。
针对 Spark 池提交多个作业时,此动态分配的工作原理
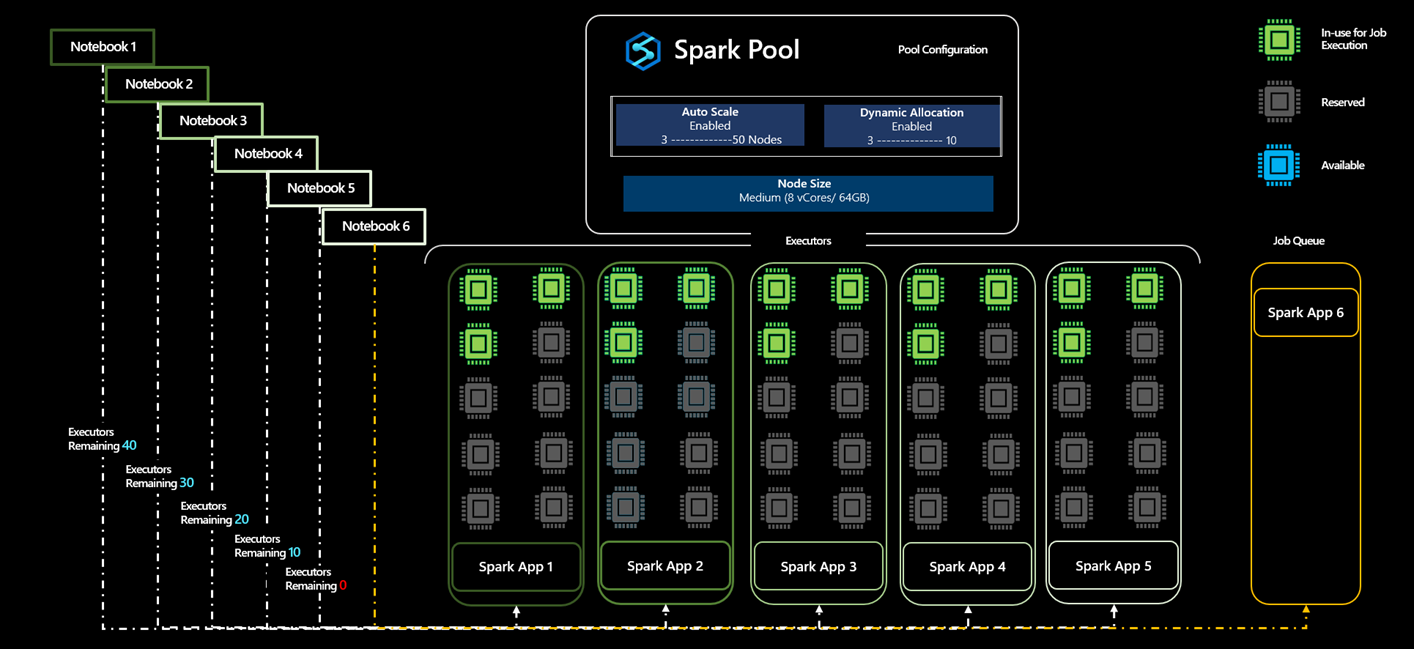
让我们看一个示例方案:有一个用户创建一个 Spark 池 A 并启用了自动缩放,其节点数最少为 5,最多 50 个。 由于用户不确定 Spark 作业所需的计算量,因此用户启用动态分配以允许执行程序缩放。
- 用户首先提交应用程序 App1,该应用程序首先运行三个执行程序,并且可以从 3 个执行程序扩展到 10 个执行程序。
- 为 Spark 池分配的最大节点数为 50。 提交 App1 后,将预留 10 个执行程序,Spark 池中的可用执行程序数将减少到 40 个。
- 用户提交另一个 Spark Application App2,其计算配置与 App1 的计算配置相同,其中应用程序首先运行 3 个执行程序,最多可扩展到 10 个执行程序,从而从 Spark 池中可用的执行程序总数中再保留 10 个执行程序。
- Spark 池中的可用执行程序总数已减少到 30 个。
- 用户提交与其他应用程序相同的应用程序 App3、App4 和 App5,因为第六个作业将排队,因为在接受 App3 之后,可用执行程序的数量减少到 20,并且类似地减少到 10,然后当 App5 作为来自池中的可用执行程序集合的 10 个执行器的保留的一部分被接受时,减少到 0。
- 由于没有可用核心,App6 将一直处于队列中,直到这些其他应用程序完成执行,并且一旦池中的可用执行程序数从 0 增加到 10,App6 就会被接受。
注释
- 即使已执行执行程序的保留,但并非所有执行程序都在使用,但保留这些执行程序是为了支持这些应用程序的自动缩放方案。
- 如果 App1、App2、App3、App4 和 App5 的所有应用程序都能够以最小节点容量运行,则执行程序总共为 15 个执行程序,但 35 个执行程序中的其余部分作为保留添加,则允许在运行这些应用程序时从 3 个执行程序横向扩展到 10 个执行程序。
- 即使预留了 35 个执行程序,用户也只会为本例中使用的 15 个执行程序计费,而非针对预留状态下的 35 个执行程序计费。
- 禁用动态分配时:在用户禁用动态分配的情况下,执行程序的保留将基于用户指定的执行器的最小和最大数量。
- 如果上述示例中的用户将执行程序数指定为 5,则将为每个提交的应用程序预留 5 个执行程序,并且用户可以提交 App6,并且 App6 不会排队。
将并发作业提交到 Synapse 工作区中的 Spark 池的方案
用户可以在 Synapse Analytics 工作区中创建多个 Spark 池,并根据其分析工作负载要求调整 Spark 池的大小。 对于创建的这些 Spark 池,如果用户已启用动态分配,则任何时间点给定工作区的可用核心总数将为
工作区的可用核心总数 = 所有 Spark 池的内核总数 - 保留或用于 Spark 池中运行的活动作业的核心数
当工作区的可用核心总数为 0 时,用户提交的作业将出现工作区容量超出错误。
多用户方案中核心的动态分配和预留
在多个用户尝试在给定的 Synapse 工作区中运行多个 Spark 作业的方案中,如果 User1 正在将作业提交到启用了动态分配的 Spark 池,则占用池中的所有可用核心。 如果 User2 提交作业,并且假设 Spark 池没有可用核心,因为其中一些核心正被主动用于执行 User1 提交的作业,而有些内核是为支持执行而保留的,则 User2 将遇到“工作区容量超出错误”。
小窍门
用户可以通过增加核心数来增加可用核心总数,以避免工作区容量超过错误。