完成言语标记后,可以开始训练模型。 训练是模型从标记的语句进行学习的过程。
若要训练模型,请启动训练作业。 只有已成功完成的作业才能创建模型。 训练作业在七天后过期,则无法再检索作业详细信息。 如果训练作业成功完成并创建了模型,则作业不会过期。 一次只能运行一个训练作业,不能在同一微调任务中启动其他作业。
注意
使用快速部署选项时,对话语言理解(CLU)会自动创建一个即时训练作业,以便使用所选择的LLM部署设置CLU意向路由器。
对于简单的项目,训练时间可能只需几秒,而如果达到语音单元的最大限制,则可能需要几个小时。
成功完成训练后,将自动触发模型评估。 评估过程首先使用经过训练的模型对测试集中的语句运行预测,并将预测结果与提供的标签进行比较(这确立了真实性的基线)。
先决条件
-
有效的 Azure 订阅。 如果没有帐户,可以免费创建一个帐户。
-
必备权限。 确保在订阅级别,将负责建立帐户和项目的人员指派为 Azure AI 帐户所有者角色。 或者,具有 贡献者 或 认知服务贡献者 角色在订阅范围内也能满足该要求。
-
在 Language Studio 中创建的项目。
- 已标注的语句,用于微调任务。
平衡训练数据
在训练数据方面,请尝试保持架构均衡。 对一个意图的大量包含和对另一个意图的少量包含会导致模型向特定意图偏斜。
为了解决这种情况,您可能需要对训练集进行降采样。 或者可能需要补充训练集样本。 若要向下采样,可以:
- 随机删除特定百分比的训练数据。
- 分析数据集并删除过多的重复条目,这是一种更系统的方式。
若要补充训练集,请在 Language Studio 中的“数据标签”选项卡上选择“建议语句”。 对话语言理解会调用 Azure OpenAI 以生成类似的言语。
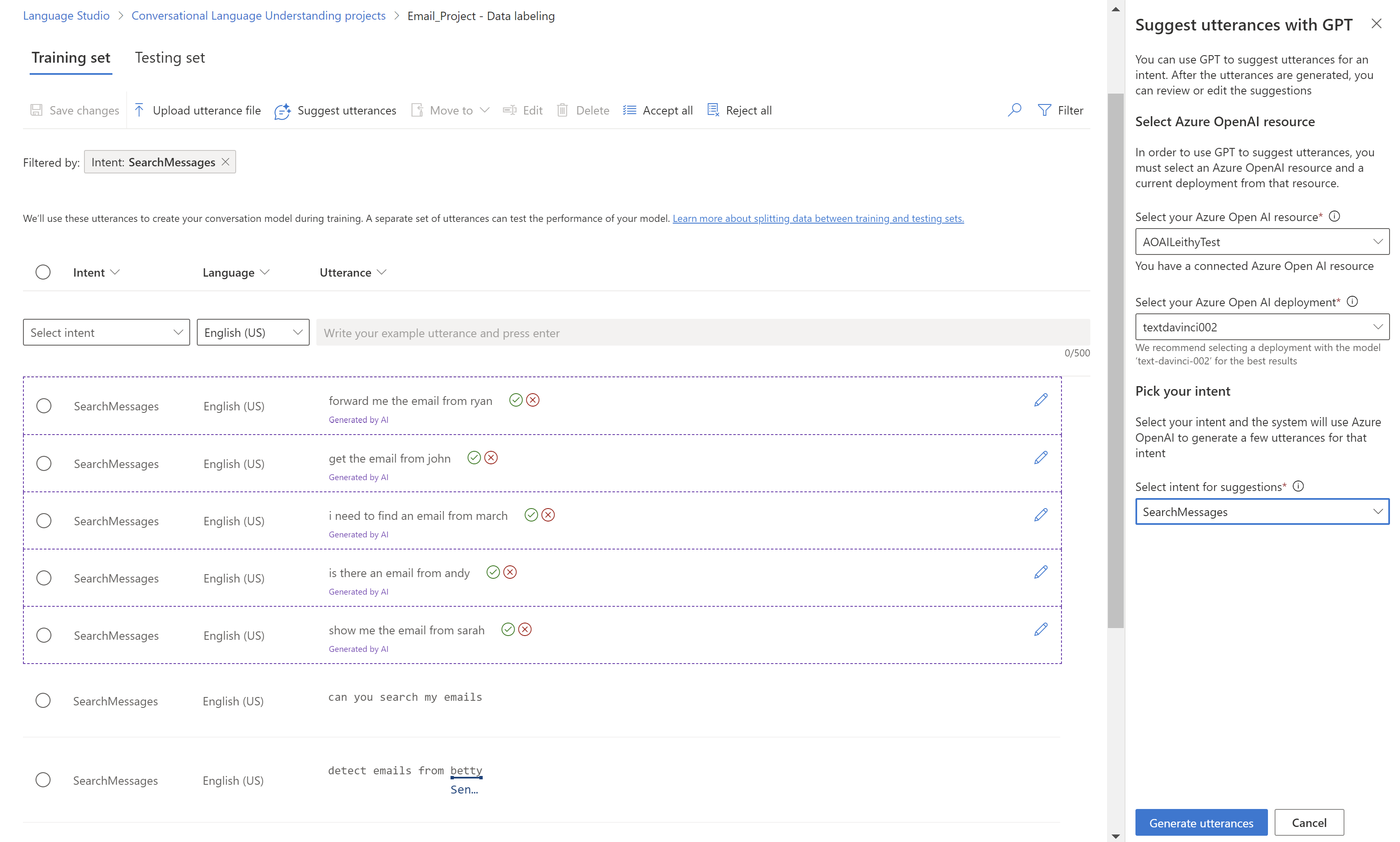
您还应在训练集中查找无意的模式。 例如,检查特定意向的训练集是否全为小写,或以特定短语开头。 在这种情况下,训练的模型可能会学习训练集中的这些意外偏差,而不是变得通用化。
建议在训练集中引入大小写和标点符号多样性。 如果期望模型预期处理变体,请确保有一个也反映这种多样性的训练集。 例如,添加一些采用正确大小写的语句,再添加一些全部小写的语句。
数据拆分
开始训练过程之前,项目中标记的语句会划分为训练集和测试集。 每个函数都提供不同的功能:
-
训练集用于训练模型,模型从中学习标记的话语。
- 测试集是一个盲集,它不是在训练期间引入到模型的,而是在评估期间引入的。
成功训练模型后,可将其用于根据测试集中的语句进行预测。 这些预测用于计算评估指标。
我们建议您确保在训练和测试集中充分表示所有的意图和实体。
对话语言理解支持两种数据拆分方法:
- 根据所选的百分比,自动从训练数据拆分测试集:系统会根据所选的百分比在训练集和测试集之间拆分标记的数据。 建议的拆分百分比为 80% 用于训练,20% 用于测试。
注意
如果选择 自动从训练数据中拆分测试集 选项,则只根据提供的百分比拆分分配给训练集的数据。
- 使用手动拆分训练和测试数据:此方法使用户能够定义语句应分别属于哪个集合。 只有在 标记期间向测试集添加了话语时,才启用此步骤。
训练模式
对话语言理解(CLU)支持两种模式来训练模型
标准训练 使用快速机器学习算法快速训练模型。 此培训级别目前仅适用于 英语 ,并且对于不使用英语(美国)或英语(UK)的任何项目,都禁用该培训级别作为其主要语言。 此训练选项是免费的。 标准培训允许您添加语句并快速免费进行测试。 显示的评估分数可以引导你在项目中的适当位置进行更改以及添加更多语句。 虽然标准训练最适合快速测试和更新模型,但使用高级训练时,应看到更好的模型质量。 虽然标准训练最适合快速测试和更新模型,但使用高级训练时,应看到更好的模型质量。 经过几次迭代并进行增量改进后,可以考虑使用高级训练方法来训练模型的另一个版本。
高级训练使用最新的机器学习技术基于数据来自定义模型。 此训练级别预计将为模型显示更好的性能分数,并使你能够使用 CLU 的多 语种功能 。 高级训练的定价不同。 有关详细信息,请参阅定价信息。
请参考评估分数做出决定。 在高级训练中,错误预测特定示例的情况可能比在使用标准训练模式时更常见。 但是,如果通过高级训练获得的总体评估结果更好,那么我们建议您将该模型作为最终模型使用。 如果情况并非如此,并且你不希望使用任何多语言功能,则可以继续使用使用标准模式训练的模型。
注意
在选择不同的训练模式时,预期会在意向置信度评分中看到行为差异,因为每种算法以不同的方式校准其评分。
训练模型
若要在 Language Studio 中开始训练模型,请执行以下操作:
在左侧菜单中,选择“训练模型”。
从顶部菜单中选择“启动训练作业”。
选择“训练新模型”,然后在文本框中输入新模型名称。 但要将现有模型替换为已针对新数据训练的模型,请选择“覆盖现有模型”,然后选择现有模型。 覆盖已训练的模型是不可逆的,但这在部署新模型之前不会影响已部署的模型。
选择训练模式。 可以选择“标准训练”以加快训练速度,但此模式仅适用于英语。 或者,可以选择其他语言和多语言项目支持的“高级训练”,但此模式需要更长的训练时间。 详细了解训练模式。
选择一种数据拆分方法。 可以选择“从训练数据中自动拆分测试集”,系统将根据指定的百分比在训练集和测试集之间拆分语句。 或者,可以使用 手动拆分训练和测试数据,只有在 标记话语时向测试集添加了话语时,此选项才启用。
选择“训练”按钮。
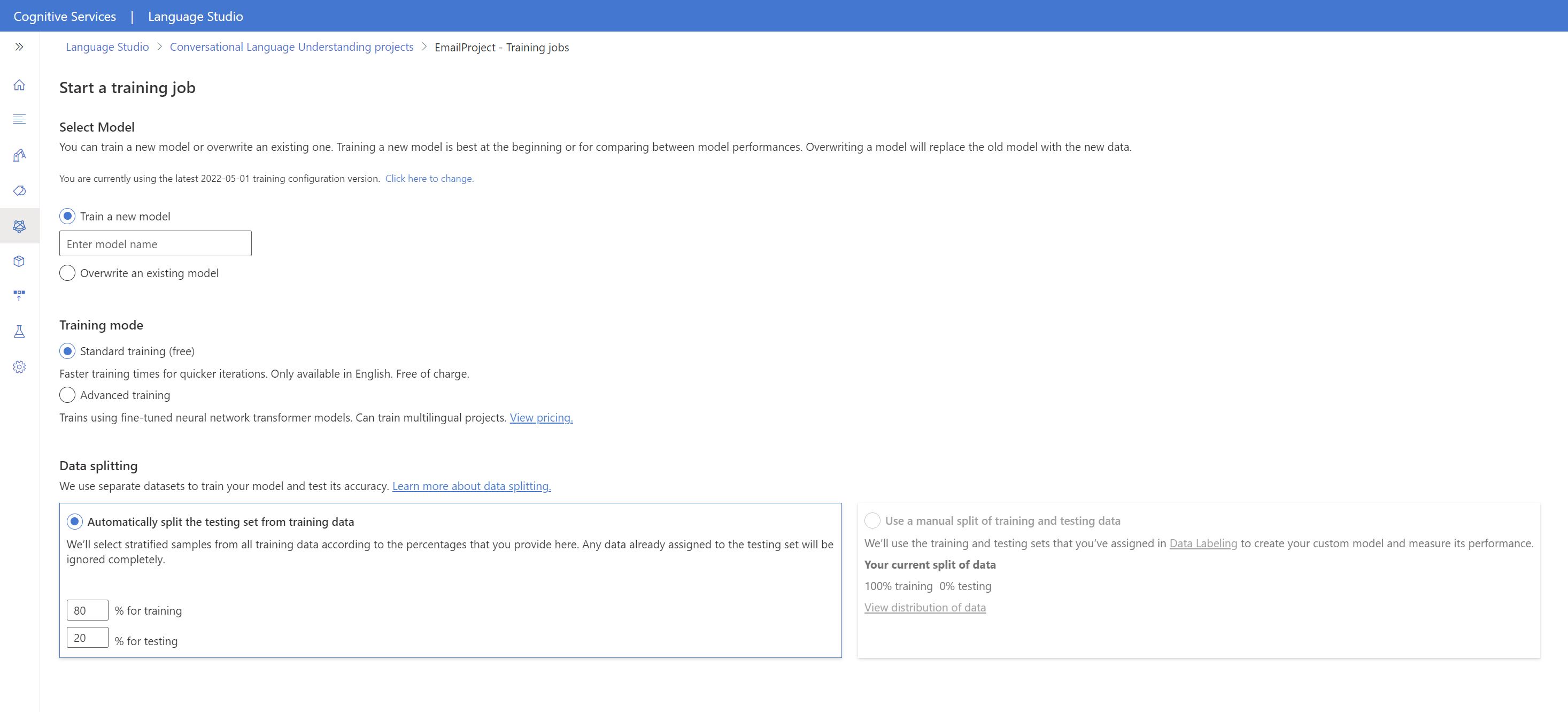
从列表中选择训练作业 ID。 出现一个面板,在该面板中可以检查此作业的训练进度、作业状态和其他详细信息。
注意
- 只有成功完成的训练作业才会生成模型。
- 训练时间从几分钟到几个小时不等,具体取决于语句数量。
- 一次只能运行一个训练作业。 在运行的作业完成之前,无法在同一项目中启动其他训练作业。
- 用于训练模型的机器学习会定期更新。 如果要在以前的配置版本上进行训练,请在“启动训练作业”页中选择“选择此处进行更改”,然后选择以前的版本。
启动训练作业
使用以下 URL、标头和 JSON 正文创建 POST 请求以提交训练作业。
请求 URL
创建 API 请求时,请使用以下 URL。 将占位符值替换为你自己的值。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| 占位符 |
值 |
示例 |
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 |
https://<your-custom-subdomain>.cognitiveservices.azure.cn |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
EmailApp |
{API-VERSION} |
要调用的 API 的版本。 |
2023-04-01 |
使用以下标头对请求进行身份验证。
| 键 |
值 |
Ocp-Apim-Subscription-Key |
资源密钥。 用于对 API 请求进行身份验证。 |
请求正文
在请求中使用以下对象。 训练完成后,模型将以用于 modelLabel 参数的值命名。
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "{TRAINING-MODE}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| 键 |
占位符 |
值 |
示例 |
modelLabel |
{MODEL-NAME} |
模型名称。 |
Model1 |
trainingConfigVersion |
{CONFIG-VERSION} |
训练配置模型版本。 默认情况下将使用最新的模型版本。 |
2022-05-01 |
trainingMode |
{TRAINING-MODE} |
用于训练的训练模式。 支持的模式为“标准训练”(训练速度更快,但仅适用于英语)和“高级训练”(受其他语言和多语言项目的支持,但训练时间更长)。 详细了解训练模式。 |
standard |
kind |
percentage |
拆分方法。 可能的值为 percentage 或 manual。 有关详细信息,请参阅如何训练模型。 |
percentage |
trainingSplitPercentage |
80 |
要包含在训练集中的已标记数据的百分比。 建议的值为 80。 |
80 |
testingSplitPercentage |
20 |
要包含在测试集中的已标记数据的百分比。 建议的值为 20。 |
20 |
注意
仅当 trainingSplitPercentage 设置为 testingSplitPercentage 时 Kind 和 percentage 才是必需的,并且两个百分比的总和应等于 100。
发送 API 请求后,会收到指示 202 成功的响应。 在响应标头中,提取 operation-location 格式如下的值:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
可以使用此 URL 获取训练作业状态。
获取训练作业状态
训练可能需要一些时间,具体取决于训练数据和架构的复杂性。 可以使用以下请求不断轮询训练作业的状态,直至成功完成。
发送成功的训练请求后,用于检查作业状态的完整请求 URL(包括终结点、项目名称和作业 ID)会包含在响应的 operation-location 标头中。
使用以下 GET 请求来获取模型在训练过程中的状态。 将占位符值替换为你自己的值。
请求 URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| 占位符 |
值 |
示例 |
{YOUR-ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 |
https://<your-custom-subdomain>.cognitiveservices.azure.cn |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
EmailApp |
{JOB-ID} |
用于查找模型训练状态的 ID。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
要调用的 API 的版本。 |
2023-04-01 |
使用以下标头对请求进行身份验证。
| 键 |
值 |
Ocp-Apim-Subscription-Key |
资源密钥。 用于对 API 请求进行身份验证。 |
响应正文
发送请求后,会收到以下响应。 继续轮询此终结点,直到“状态”参数变为“已成功”。
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"trainingMode": "{TRAINING-MODE}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxx-xxxxx-xxxx-xxxxx-xxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| 键 |
值 |
示例 |
modelLabel |
模型名称 |
Model1 |
trainingConfigVersion |
训练配置版本。 默认使用最新版本。 |
2022-05-01 |
trainingMode |
你选择的训练模式。 |
standard |
startDateTime |
开始训练的时间 |
2022-04-14T10:23:04.2598544Z |
status |
训练作业的状态 |
running |
estimatedEndDateTime |
预计的训练作业完成时间 |
2022-04-14T10:29:38.2598544Z |
jobId |
训练作业 ID |
xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
训练作业创建日期和时间 |
2022-04-14T10:22:42Z |
lastUpdatedDateTime |
训练作业上次更新日期和时间 |
2022-04-14T10:23:45Z |
expirationDateTime |
训练作业过期日期和时间 |
2022-04-14T10:22:42Z |
取消训练作业
使用以下 URL、标头和 JSON 正文创建 POST 请求,以取消训练作业。
请求 URL
创建 API 请求时,请使用以下 URL。 将占位符值替换为你自己的值。
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}/:cancel?api-version={API-VERSION}
| 占位符 |
值 |
示例 |
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 |
https://<your-custom-subdomain>.cognitiveservices.azure.cn |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
EmailApp |
{JOB-ID} |
训练作业 ID。 |
XXXXX-XXXXX-XXXX-XX |
{API-VERSION} |
要调用的 API 的版本。 |
2023-04-01 |
使用以下标头对请求进行身份验证。
| 键 |
值 |
Ocp-Apim-Subscription-Key |
资源密钥。 用于对 API 请求进行身份验证。 |
发送 API 请求后,会收到 202 响应,指示成功,这意味着训练作业已取消。 带有用于检查作业状态的 Operation-Location 标头的成功调用结果。
后续步骤
使用 模型评估指标查看模型的性能。

