本页介绍如何使用 Delta Sharing 开放共享 协议和承载令牌读取与您共享的数据。 它包括有关使用以下工具读取共享数据的说明:
- Databricks
- Iceberg 客户端
- Apache Spark
- 熊猫
- Power BI
- Tableau
在此开放共享模型中,你将使用由数据提供程序与团队成员共享的凭据文件,以获得对共享数据的安全读取访问权限。 只要凭据有效且提供商继续共享数据,访问就会持续。 提供商管理凭据过期和轮换。 数据更新几乎实时可用。 可以读取和创建共享数据的副本,但不能修改源数据。
注意
如果使用 Databricks-to-Databricks Delta 共享共享数据,则不需要凭证文件来访问数据,因此此页面不适用于你。 相反,请参阅 读取通过 Databricks 到 Databricks Delta 共享的数据(供接收者使用)。
以下部分介绍如何使用 Azure Databricks、Apache Spark、 pandasPower BI 和 Iceberg 客户端通过凭据文件访问和读取共享数据。 有关 Delta Sharing 连接器的完整列表及其用法的信息,请参阅 Delta Sharing 开放源代码文档。 如果在访问共享数据时遇到问题,请联系数据提供者。
开始之前
团队成员必须下载数据提供程序共享的凭据文件,并使用安全通道与你共享该文件或文件位置。 请参阅在开放共享模型中获取访问权限。
有关连接器特定的文档,请参阅 下载凭据页。
Azure Databricks:使用开放共享连接器读取共享的数据
本部分介绍如何导入提供程序以及如何在目录资源管理器或 Python 笔记本中查询共享数据:
如果为 Unity Catalog 启用了 Azure Databricks 工作区,请在目录资源管理器中使用“导入提供程序”界面。 无需存储或指定凭据文件即可执行以下作:
- 只需点击按钮,即可从共享中创建目录。
- 使用 Unity 目录访问控制授予对共享表的访问权限。
- 使用标准 Unity 目录语法查询共享数据。
如果未为 Unity Catalog 启用 Azure Databricks 工作区,请参阅 Python 笔记本说明示例。
目录资源管理器
必需的权限:元存储管理员,或者对 Unity Catalog 元存储同时具有 CREATE PROVIDER 和 USE PROVIDER 权限的用户。
在 Azure Databricks 工作区中,单击
 以打开目录资源管理器。
以打开目录资源管理器。在目录窗格顶部,单击
 ,然后选择Delta Sharing(增量共享)。
,然后选择Delta Sharing(增量共享)。或者,在“快速访问”页中,单击“Delta Sharing >”按钮。
在“与我共享的内容”选项卡上,单击“导入数据”。
输入提供程序名称。
名称不能包含空格。
上传提供程序与你共享的凭据文件。
许多提供程序都有自己的 Delta Sharing 网络,你可以从中接收数据共享。 有关详细信息,请参阅特定提供程序的配置。
(可选)输入注释。
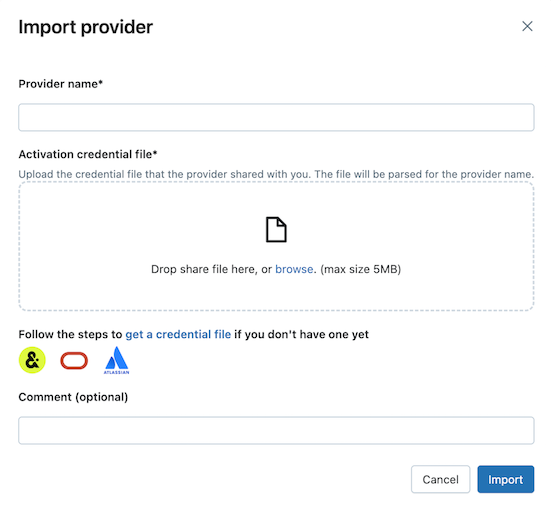
单击导入。
基于共享数据创建目录。
在“共享”选项卡上,单击共享行上的“创建目录”。
有关使用 SQL 或 Databricks CLI 基于共享创建目录的信息,请参阅基于共享创建目录。
授予对目录的访问权限。
像读取在 Unity Catalog 中注册的任何数据对象一样读取共享数据对象。
有关详细信息和示例,请参阅访问共享表或卷中的数据。
Python
本部分介绍如何使用开放共享连接器在 Azure Databricks 工作区中通过笔记本访问共享的数据。 你或团队的另一个成员将凭据文件存储在 Azure Databricks 中,然后使用它向数据提供程序的 Azure Databricks 帐户进行身份验证,并读取数据提供程序与你共享的数据。
注意
这些说明假定未为 Unity Catalog 启用 Azure Databricks 工作区。 如果使用 Unity Catalog,则从共享读取时无需指向凭据文件。 你可以读取共享表中的数据,就像从 Unity Catalog 中注册的任何表中读取一样。 Databricks 建议在目录资源管理器中使用“导入提供程序”界面,而不是按此处提供的说明操作。
首先将凭据文件存储为 Azure Databricks 工作区文件,以便团队中的用户可以访问共享数据。
若要在 Azure Databricks 工作区中导入凭据文件,请参阅 “导入文件”。
单击文件旁边的
“Kebab”菜单图标 “共享”(权限),授予其他用户访问文件的权限。 输入应有权访问文件的 Azure Databricks 标识。 有关文件权限的详细信息,请参阅 文件 ACL。
存储凭据文件后,请使用笔记本列出和读取共享表。
在 Azure Databricks 工作区中,单击新建 > 笔记本。
有关 Azure Databricks 笔记本的详细信息,请参阅 Databricks 笔记本。
若要使用 Python 或
pandas访问共享数据,请安装 增量共享 Python 连接器。 在笔记本编辑器中,粘贴以下命令:%sh pip install delta-sharing运行该单元。
delta-sharing如果尚未安装 Python 库,则会在群集中安装。使用 Python 列出共享中的表。
在新的单元格中粘贴以下命令。 将工作区路径替换为凭据文件的文件路径。
代码运行时,Python 读取凭据文件。
import delta_sharing client = delta_sharing.SharingClient(f"/Workspace/path/to/config.share") client.list_all_tables()运行该单元。
结果是一个表数组,以及每个表的元数据。 以下输出显示了两个表:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]如果输出为空或不包含预期的表,请与数据提供者联系。
查询某个共享表。
使用 Scala:
在新的单元格中粘贴以下命令。 代码运行时,将从工作区文件读取凭据文件。
替换变量,如下所示:
-
<profile-path>:凭据文件的工作区路径。 例如/Workspace/Users/user.name@email.com/config.share。 -
<share-name>:表的share=的值。 -
<schema-name>:表的schema=的值。 -
<table-name>:表的name=的值。
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);运行该单元。 每次加载共享表时,你都会看到来自源的新数据。
-
使用 SQL:
若要使用 SQL 查询数据,必须从共享表在工作区中创建本地表,然后查询本地表。 共享数据不存储或缓存在本地表中。 每次查询本地表时,你都会看到共享数据的当前状态。
在新的单元格中粘贴以下命令。
替换变量,如下所示:
-
<local-table-name>:本地表的名称。 -
<profile-path>:凭据文件的位置。 -
<share-name>:表的share=的值。 -
<schema-name>:表的schema=的值。 -
<table-name>:表的name=的值。
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;运行该命令时,将直接查询共享数据。 作为测试,查询该表并返回前 10 个结果。
-
如果输出为空或不包含预期的数据,请与数据提供者联系。
Iceberg 客户端:读取共享数据
重要
此功能目前以公共预览版提供。
使用外部 Iceberg 客户端(如 Snowflake、Trino、Flink 和 Spark)使用 Apache Iceberg REST 目录 API 读取具有零复制访问权限的共享数据资产。
获取连接凭据
在与外部 Iceberg 客户端访问共享数据资产之前,请收集以下凭据:
- Iceberg REST 目录终结点
- 有效的持有者令牌
- 共享名称
- (可选)命名空间或架构名称
- (可选)表名称
Iceberg REST 目录终结点 (icebergEndpoint) 和持有者令牌位于数据提供程序与你共享的凭据文件中。 有关详细信息,请参阅开始之前。 可以使用 Delta Sharing API 以编程方式发现共享名称、命名空间和表名。
重要
该 icebergEndpoint 文件位于凭据文件中,其格式 <workspace-url>/api/2.0/delta-sharing/metastores/<metastore-id>/iceberg为 。
以下示例演示如何获取其他凭据。 根据需要从凭据文件输入终结点、Iceberg 终结点和持有者令牌:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
注意
此方法始终检索最新资产列表。 但是,它需要 Internet 访问,在无代码环境中更难集成。
配置 Iceberg 目录
获取必要的连接凭据后,请将客户端配置为使用 Iceberg REST 目录终结点创建和查询表。
对于每个共享,请创建目录集成。
USE ROLE ACCOUNTADMIN; CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER> CATALOG_SOURCE = ICEBERG_REST TABLE_FORMAT = ICEBERG REST_CONFIG = ( CATALOG_URI = '<icebergEndpoint>', WAREHOUSE = '<share_name>', ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS ) REST_AUTHENTICATION = ( TYPE = BEARER, BEARER_TOKEN = '<bearerToken>' ) ENABLED = TRUE;(可选)添加
REFRESH_INTERVAL_SECONDS以使元数据保持最新状态。 根据目录更新频率设置值。REFRESH_INTERVAL_SECONDS = 30配置目录后,从目录创建数据库。 这会自动在该目录中创建所有架构和表。
CREATE DATABASE <DATABASE_PLACEHOLDER> LINKED_CATALOG = ( CATALOG = <CATALOG_PLACEHOLDER> );若要确认共享成功,请从数据库中的表进行查询。 您应该能够看到来自 Azure Databricks 的共享数据。
如果结果为空或发生错误,请按照以下常见故障排除步骤作:
- 仔细检查特权、快照生成状态和 REST 凭据。
- 请联系数据供应商。
- 请参阅特定于 Iceberg 客户端的文档。
示例:使用不同的 Iceberg 客户端访问共享表
以下示例演示如何在获取连接凭据后使用外部 Iceberg 客户端(如 Snowflake、Apache Spark、PyIceberg 和 REST API)访问 Delta 共享表。 有关获取连接凭据的详细信息,请参阅 开始之前。
Snowflake
若要在 Snowflake 中读取共享数据资产,请上传下载的凭据文件并生成所需的 SQL 命令:
从 Delta 共享激活链接中,单击 Snowflake 图标。
在 Snowflake 集成页上,上传从数据提供程序收到的凭据文件。
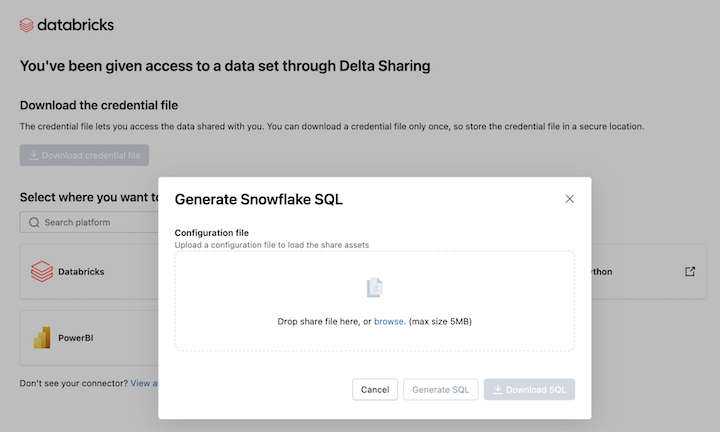
加载凭据后,选择要在 Snowflake 中访问的共享资源。
选择所需资产后,单击“ 生成 SQL ”。

将生成的 SQL 复制并粘贴到 Snowflake 工作表中。 将
CATALOG_PLACEHOLDER替换为您想使用的目录名称,将DATABASE_PLACEHOLDER替换为您想使用的数据库名称。
局限性
连接到 Snowflake 中的 Iceberg REST 目录具有以下限制:
- 元数据文件不会自动更新以包含最新的快照。 必须依赖于自动刷新或手动刷新。
- 不支持 R2。
- 所有 Iceberg 客户端限制 都适用。
Apache Spark
若要使用 Apache Spark 访问共享表,请使用以下设置配置 Iceberg REST 目录 API。 将 <spark-catalog-name> 替换为您的目录名称,并提供连接凭据:
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
# Configuration for accessing tables shared using Delta Sharing
"spark.sql.catalog.<spark-catalog-name>":"org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.<spark-catalog-name>.type": "rest",
"spark.sql.catalog.<spark-catalog-name>.uri": "<icebergEndpoint>",
"spark.sql.catalog.<spark-catalog-name>.token": "<bearerToken>",
"spark.sql.catalog.<spark-catalog-name>.warehouse":"<share_name>",
"spark.sql.catalog.<spark-catalog-name>.scope":"all-apis"
PyIceberg
PyIceberg 是一种 Python 实现,用于访问 Iceberg 表而不使用 JVM。 PyIceberg 要求 pyarrow 执行表操作,例如读取数据和检查表元数据。 使用 pyarrow 额外组件安装 PyIceberg:
pip install "pyiceberg[pyarrow]"
若要访问共享表,请将以下目录配置添加到 PyIceberg 配置文件:
catalog:
delta_sharing:
type: rest
uri: <icebergEndpoint>
warehouse: <share_name>
token: <bearerToken>
REST API
使用 REST API 调用(如以下示例 curl )加载表并检索其元数据以及用于访问数据文件的临时凭据:
curl -X GET -H "Authorization: Bearer <bearerToken>" -H "Accept: application/json" \
<icebergEndpoint>/v1/shares/<share_name>/namespaces/<schema_name>/tables/<table_name>
响应包括 Iceberg 表元数据、S3 位置和临时 AWS 凭据,这些凭据允许客户端读取数据文件:
{
"metadata-location": "s3://bucket/path/to/iceberg/table/metadata/file",
"metadata": <iceberg-table-metadata-json>,
"config": {
"expires-at-ms": "<epoch-ts-in-millis>",
"s3.access-key-id": "<temporary-s3-access-key-id>",
"s3.session-token": "<temporary-s3-session-token>",
"s3.secret-access-key": "<temporary-secret-access-key>",
"client.region": "<aws-bucket-region-for-metadata-location>"
}
}
Iceberg 客户端限制
从 Iceberg 客户端查询 Delta Sharing 数据时,以下限制适用:
- 在命名空间中列出表时,如果命名空间包含 100 多个共享视图,则响应限制为前 100 个视图。
Apache Spark:读取共享的数据
按照以下步骤使用 Spark 3.x 或更高版本访问共享的数据。
这些说明假设你有权访问数据提供程序共享的凭据文件。 请参阅在开放共享模型中获取访问权限。
重要
使用绝对路径确保 Apache Spark 可以访问凭据文件。 路径可以指向云对象或 Unity Catalog 卷。
注意
如果你在启用了 Unity Catalog 目录的 Azure Databricks 工作区上使用 Spark,并且使用了导入提供程序 UI 导入提供商和共享,则本部分的说明对你不适用。 你可以像在 Unity Catalog 中注册的任何其他表一样访问共享表。 无需安装 delta-sharing Python 连接器或提供凭据文件的路径。 请参阅 Azure Databricks:使用开放共享连接器读取共享数据。
安装 Delta Sharing Python 和 Spark 连接器
若要访问与共享数据相关的元数据(例如与你共享的表列表),请执行以下操作。 本示例使用 Python。
安装 delta-sharing Python 连接器。 有关 Python 连接器限制的信息,请参阅 Delta 共享 Python 连接器限制。
pip install delta-sharing安装 Apache Spark 连接器。
使用 Spark 列出共享的表
列出共享中的表。 在下面的示例中,将 <profile-path> 替换为凭据文件的位置。
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
结果是一个表数组,以及每个表的元数据。 以下输出显示了两个表:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
如果输出为空或不包含预期的表,请与数据提供者联系。
使用 Spark 访问共享的数据
运行以下命令并替换以下变量:
-
<profile-path>:凭据文件的位置。 -
<share-name>:表的share=的值。 -
<schema-name>:表的schema=的值。 -
<table-name>:表的name=的值。 -
<version-as-of>:可选。 要加载数据的表的版本。 只有在数据提供者共享表的历史记录的情况下才有效。 需要delta-sharing-spark0.5.0 或更高版本。 -
<timestamp-as-of>:可选。 在给定时间戳的版本或其之前的版本加载数据。 只有在数据提供者共享表的历史记录的情况下才有效。 需要delta-sharing-spark0.6.0 或更高版本。
Python
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
Scala(编程语言)
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
使用 Spark 访问共享的变更数据馈送
如果表历史记录已与你共享,并且源表上启用了更改数据馈送(CDF),请运行以下命令来访问更改数据馈送,替换这些变量。 需要 delta-sharing-spark 0.5.0 或更高版本。
必须提供一个启动参数。
-
<profile-path>:凭据文件的位置。 -
<share-name>:表的share=的值。 -
<schema-name>:表的schema=的值。 -
<table-name>:表的name=的值。 -
<starting-version>:可选。 查询的起始版本(含)。 指定为长整型。 -
<ending-version>:可选。 查询的结束版本(含)。 如果未提供结束版本,API 将使用最新的表版本。 -
<starting-timestamp>:可选。 查询的起始时间戳,将被转换为创建时间大于或等于此时间戳的版本。 指定为采用yyyy-mm-dd hh:mm:ss[.fffffffff]格式的字符串。 -
<ending-timestamp>:可选。 查询的结束时间戳,它将被转换为一个在此时间戳之前或等于此时间戳创建的版本。 请将其指定为格式为yyyy-mm-dd hh:mm:ss[.fffffffff]的字符串
Python
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala(编程语言)
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
如果输出为空或不包含预期的数据,请与数据提供者联系。
使用 Spark 结构化流处理来访问共享表
如果表历史记录已与你共享,你可以流式读取共享数据。 需要 delta-sharing-spark 0.6.0 或更高版本。
支持的选项:
-
ignoreDeletes:忽略删除数据的事务。 -
ignoreChanges:如果由于数据更改操作(例如UPDATE、MERGE INTO、DELETE(分区内)或OVERWRITE)而在源表中重写了文件,则重新处理更新。 未更改的行仍然可以被发出。 因此,下游使用者应能够处理重复项。 删除不会传播到下游。ignoreChanges包括ignoreDeletes。 因此,如果使用ignoreChanges,则流不会因对源表的删除或更新而中断。 -
startingVersion:起始的共享表版本。 从此版本(含)开始的所有表更改都由流式处理源读取。 -
startingTimestamp:启动的时间戳。 流式处理源将读取所有在时间戳及其之后提交的表更改(包括该时间戳在内)。 示例:"2023-01-01 00:00:00.0"。 -
maxFilesPerTrigger:每个微批中需要考虑的新文件数量。 -
maxBytesPerTrigger:在每个微批中处理的数据量。 此选项设置一个“柔性最大值”,这意味着批处理大约处理此数量的数据,并且可能会超过此限制,以便在最小输入单元大于此限制的情况下,继续处理流式查询。 -
readChangeFeed:流式读取共享表的变更数据流。
不支持的选项:
Trigger.availableNow
结构化流式处理查询示例
Scala(编程语言)
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Python
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
另请参阅结构化流式处理概念。
读取启用了删除矢量或列映射的表
重要
此功能目前以公共预览版提供。
删除向量是提供商可以在共享 Delta 表上启用的一项存储优化功能。 请参阅 Databricks 中的删除向量。
Azure Databricks 还支持 Delta 表的列映射。 请参阅使用 Delta Lake 列映射重命名和删除列。
如果你的提供商共享了启用了删除矢量或列映射的表,则可以使用运行 delta-sharing-spark 3.1 或更高版本的计算来读取该表。 如果你使用 Databricks 群集,则可以使用运行 Databricks Runtime 14.1 或更高版本的群集执行批量读取。 CDF 和流式处理查询需要 Databricks Runtime 14.2 或更高版本。
可以按原样执行批处理查询,因为它们可以根据共享表的表功能自动解析 responseFormat。
若要读取变更数据馈送 (CDF) 或对启用了删除向量或列映射的共享表执行流式处理查询,必须设置附加选项 responseFormat=delta。
以下示例显示了批处理、CDF 和流式处理查询:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Pandas:读取共享的数据
按照以下步骤访问 0.25.3 或更高版本中的 pandas 共享数据。
这些说明假设你有权访问数据提供程序共享的凭据文件。 请参阅在开放共享模型中获取访问权限。
注意
如果你在启用了 Unity Catalog 的 Azure Databricks 工作区上使用 pandas,并且使用导入提供程序 UI 导入了提供程序和共享,那么本节中的说明对你不适用。 你可以像在 Unity Catalog 中注册的任何其他表一样访问共享表。 无需安装 delta-sharing Python 连接器或提供凭据文件的路径。 请参阅 Azure Databricks:使用开放共享连接器读取共享数据。
安装 Delta Sharing Python 连接器
若要访问与共享数据相关的元数据(例如与你共享的表列表),必须安装 delta-sharing Python 连接器。 有关 Python 连接器限制的信息,请参阅 Delta 共享 Python 连接器限制。
pip install delta-sharing
使用 pandas 列出共享表
若要列出共享中的表,请运行以下命令并将 <profile-path>/config.share 替换为凭据文件的位置。
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
如果输出为空或不包含预期的表,请与数据提供者联系。
使用 pandas 访问共享数据
若要使用 Python 访问共享数据 pandas ,请运行以下命令,替换变量,如下所示:
-
<profile-path>:凭据文件的位置。 -
<share-name>:表的share=的值。 -
<schema-name>:表的schema=的值。 -
<table-name>:表的name=的值。
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
使用 pandas 访问共享更改数据馈送
若要使用 Python 访问共享表 pandas 的更改数据馈送,请运行以下命令,如下所示替换变量。 可能未提供更改数据馈送,具体取决于数据提供程序是否共享了表的更改数据馈送。
-
<starting-version>:可选。 查询的起始版本(含)。 -
<ending-version>:可选。 查询的结束版本(含)。 -
<starting-timestamp>:可选。 查询的起始时间戳。 此值将转换为在晚于或等于此时间戳创建的版本。 -
<ending-timestamp>:可选。 查询的结束时间戳。 将其转换至一个在早于或等于此时间戳创建的版本。
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
如果输出为空或不包含预期的数据,请与数据提供者联系。
Power BI:读取共享的数据
使用 Power BI Delta Sharing 连接器可以通过 Delta Sharing 开放协议来发现、分析和可视化与你共享的数据集。
要求
- Power BI Desktop 2.99.621.0 或更高版本。
- 访问数据提供者共享的凭据文件。 请参阅在开放共享模型中获取访问权限。
连接到 Databricks
若要使用 Delta Sharing 连接器连接到 Azure Databricks,请执行以下操作:
使用文本编辑器打开共享的凭据文件以检索终结点 URL 和令牌。
打开 Power BI Desktop。
在“获取数据”菜单中,搜索“Delta Sharing”。
选择连接器并单击“连接”。
在“Delta Sharing 服务器 URL”字段中,输入您从凭据文件中复制的端点 URL。
(可选)在“高级选项”选项卡中,为可下载的最大行数设置“行限制”。 此限制默认设置为 100 万行。
单击 “确定” 。
对于“身份验证”,请将从凭据文件中检索的令牌复制到“持有者令牌”中。
单击“连接” 。
Power BI Delta Sharing 连接器的限制
Power BI Delta Sharing 连接器具有以下限制:
- 该连接器加载的数据必须能够装入计算机的内存。 为了管理此要求,该连接器会将导入的行数限制为在 Power BI Desktop 的“高级选项”选项卡下设置的“行限制”。
Tableau:读取共享数据
使用 Tableau Delta Sharing 连接器可以通过 Delta Sharing 开放协议来发现、分析和可视化与你共享的数据集。
要求
- Tableau Desktop 和 Tableau Server 2024.1 或更高版本
- 可以访问数据提供者共享的凭据文件。 请参阅在开放共享模型中获取访问权限。
连接到 Azure DataBricks
若要使用 Delta Sharing 连接器连接到 Azure Databricks,请执行以下操作:
转到Tableau Exchange,按照说明下载 Delta Sharing 连接器,并将其放入相应的桌面文件夹中。
打开 Tableau Desktop。
在“连接器”页上,搜索“Delta Sharing by Databricks”。
选择上传共享文件,然后选择提供者共享的凭证文件。
单击“获取数据”。
在数据资源管理器中,选择该表。
(可选)添加 SQL 筛选器或行限制。
点击“获取表数据”。
局限性
Tableau Delta Sharing 连接器具有以下限制:
- 该连接器加载的数据必须能够装入计算机的内存。 为了管理此要求,连接器会将导入的行数限制为在 Tableau 中设置的行限制。
- 所有列都作为类型
String返回。 - 只有当 Delta Sharing 服务器支持predicateHint时,SQL 筛选器才有效。
- 不支持删除矢量。
- 不支持列映射。
Delta Sharing Python 连接器的限制
这些限制特定于 Delta 共享 Python 连接器:
- Delta Sharing Python 连接器 1.1.0+ 支持对具有列映射的表的快照查询,但不支持对具有列映射的表执行 CDF 查询。
- 如果在查询的版本范围内架构发生更改,Delta Sharing Python 连接器在执行 CDF 查询时会失败,并显示错误代码
use_delta_format=True。
请求新凭据
如果你的凭据激活 URL 或下载的凭据丢失、损坏或泄露,或者凭据过期且提供商未发送新凭据,请联系提供商请求新凭据。