本文介绍如何使用 Databricks 资产捆绑生成、部署和运行 Scala JAR。 有关捆绑包的信息,请参阅 什么是 Databricks 资产捆绑包?。
有关生成 Java JAR 并将其上传到 Unity 目录的示例配置,请参阅 将 JAR 文件上传到 Unity 目录的捆绑包。
要求
本教程要求 Databricks 工作区满足以下要求:
- 已启用 Unity Catalog。 请参阅为 Unity Catalog 启用工作区。
- 在 Databricks 中,您必须拥有一个 Unity Catalog 卷,用于存储构建工件,并且需要有将 JAR 上传到指定卷路径的权限。 请参阅 “创建和管理 Unity 目录卷”。
- 已启用无服务器计算。 请务必查看无服务器计算 功能限制。
- 工作区位于 受支持的区域中。
此外,本地开发环境必须安装以下各项:
- Java 开发工具包 (JDK) 17
- IntelliJ IDEA
- sbt
- Databricks CLI 版本 0.218.0 或更高版本。 若要检查安装的 Databricks CLI 版本,请运行命令
databricks -v。 要安装 Databricks CLI,请参阅《安装或更新 Databricks CLI》。 - Databricks CLI 身份验证使用配置文件
DEFAULT进行配置。 若要配置身份验证,请参阅 “配置对工作区的访问权限”。
步骤 1:创建捆绑包
首先,使用 bundle init 命令 和 Scala 项目捆绑模板创建捆绑包。
Scala JAR 捆绑模板创建一个捆绑包,该捆绑包生成 JAR,将其上传到指定卷,并使用在无服务器计算上运行的 JAR 定义具有 Spark 任务的作业。 模板项目中的 Scala 定义了一个 UDF,该 UDF 将简单的转换应用于示例数据帧并输出结果。 模板的源位于 捆绑示例存储库中。
在本地开发计算机上的终端窗口中运行以下命令。 它会提示输入某些必填字段的值。
databricks bundle init default-scala对于项目的名称,请输入
my_scala_project。 这将确定此捆绑包的根目录的名称。 此根目录是在当前工作目录中创建的。对于卷目标路径,请提供 Databricks 中要创建捆绑包目录的 Unity Catalog 卷路径,该目录包含 JAR 和其他工件,例如
/Volumes/my-catalog/my-schema/bundle-volumes。注释
模板项目配置无服务器计算,但如果将其更改为使用经典计算,管理员可能需要将您指定的 Volumes JAR 路径加入允许列表。 请参阅在采用标准访问模式(以前称为“共享访问模式”)的计算上将库和初始化脚本加入允许列表。
步骤 2:配置 VM 选项
将包含
build.sbt的当前目录导入到 IntelliJ 中。在 IntelliJ 中选择 Java 17。 转到 文件>项目结构>SDK。
打开
src/main/scala/com/examples/Main.scala。导航到 Main 的配置以添加 VM 选项:
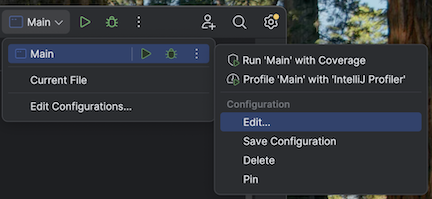
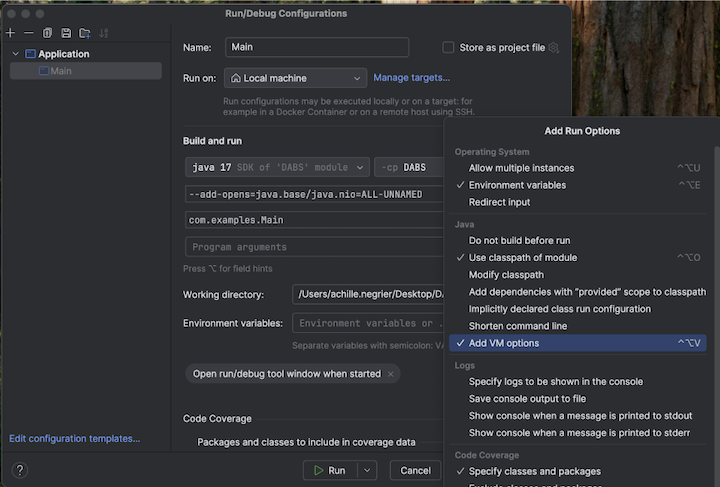
将以下内容添加到 VM 选项:
--add-opens=java.base/java.nio=ALL-UNNAMED
小窍门
或者,如果使用 Visual Studio Code,请将以下内容添加到 sbt 生成文件:
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
然后从终端运行应用程序:
sbt run
步骤 3:浏览捆绑包
若要查看模板生成的文件,请切换到新创建的捆绑包的根目录,并在 IDE 中打开此目录。 该模板使用 sbt 编译和打包 Scala 文件,并配合 Databricks Connect 进行本地开发。 有关详细信息,请参阅生成的项目 README.md。
特别感兴趣的文件包括:
-
databricks.yml:此文件指定程序包的编程名称,包括对作业定义的引用,并指定有关目标工作区的设置。 -
resources/my_scala_project.job.yml:此文件指定作业的 JAR 任务和群集设置。 -
src/:此目录包括 Scala 项目的源文件。 -
build.sbt:此文件包含重要的生成和依赖库设置。 -
README.md:此文件包含以下入门步骤,以及本地生成说明和设置。
步骤 4:验证项目的程序包配置文件
接下来,使用 捆绑包验证命令检查捆绑包配置是否有效。
从根目录运行 Databricks CLI
bundle validate命令。 在其他检查中,这将验证工作区中是否存在配置文件中指定的卷。databricks bundle validate如果返回了捆绑包配置的摘要,则表示验证成功。 如果返回任何错误,请修复错误,然后重复此步骤。
如果在此步骤后对捆绑包进行任何更改,请重复此步骤以检查捆绑配置是否仍然有效。
步骤 5:将本地项目部署到远程工作区
现在,使用 捆绑部署命令将捆绑包部署到远程 Azure Databricks 工作区。 此步骤将生成 JAR 文件并将其上传到指定的卷。
运行 Databricks CLI
bundle deploy命令:databricks bundle deploy -t dev检查本地生成的 JAR 文件是否已部署:
- 在 Azure Databricks 工作区的边栏中,单击 “目录资源管理器”。
- 导航到初始化捆绑包时指定的卷目标路径。 JAR 文件应位于该路径内的以下文件夹中:
/my_scala_project/dev/<user-name>/.internal/
检查作业是否已创建:
- 在 Azure Databricks 工作区的边栏中,单击作业和管道。
- (可选)选择作业和归我所有筛选器。
- 单击 [dev
<your-username>]my_scala_project。 - 单击“任务”选项卡。
应该有一个任务:main_task。
如果在此步骤后对捆绑包进行任何更改,请重复验证和部署步骤。
步骤 6:运行部署的项目
最后,使用 捆绑包运行命令运行 Azure Databricks 作业。
在根目录中,运行 Databricks CLI
bundle run命令,并在定义文件中my_scala_project.job.yml指定作业的名称:databricks bundle run -t dev my_scala_project复制终端中显示的
Run URL值,并将该值粘贴到 Web 浏览器中以打开 Azure Databricks 工作区。在 Azure Databricks 工作区中,任务成功完成并显示绿色标题栏后,请单击 main_task 任务以查看结果。