本文演示如何使用 Lakeflow 作业协调任务来读取和处理示例数据集。 在本快速入门中,请执行以下操作:
创建新笔记本并添加代码,以检索包含按年份排列的常用婴儿姓名的示例数据集。
将示例数据集保存到 Unity Catalog。
创建新的笔记本并添加代码,以从 Unity Catalog 读取数据集,按年份对其进行筛选,并显示结果。
使用笔记本创建新作业并配置两个任务。
运行作业并查看结果。
要求
如果工作区启用了 Unity Catalog,并且启用了无服务器作业,则默认情况下作业会在无服务器计算上运行。 你不需群集创建权限即可使用无服务器计算来运行作业。
否则,你必须拥有创建作业计算的群集创建权限或对通用计算资源的权限。
Unity Catalog 中必须有一个卷。 本文使用一个示例卷,名称为my-volume,位于名为default的架构中,该架构在名为main的目录内。 必须在 Unity Catalog 中具有以下权限:
-
READ VOLUME和WRITE VOLUME或ALL PRIVILEGES(对于my-volume卷)。 -
USE SCHEMA或ALL PRIVILEGES(对于default架构)。 -
USE CATALOG或ALL PRIVILEGES(对于main目录)。
若要设置这些权限,请联系 Databricks 管理员或参阅 Unity Catalog 特权和安全对象。
创建笔记本
以下步骤创建两个笔记本以在此工作流中运行。
检索和保存数据
若要创建检索示例数据集并将其保存到 Unity 目录的笔记本,请执行以下作:
单击侧栏中的“
 新建 ”,然后单击“ 笔记本”。
新建 ”,然后单击“ 笔记本”。Databricks 会在默认文件夹中创建一个新的空白笔记本并将其打开。 默认语言是你最近使用的语言,笔记本会自动附加到你最近使用的计算资源。
(可选)重命名笔记本 “检索名称数据”。
如果需要,可将默认语言更改为 Python。
复制以下 Python 代码并将其粘贴到笔记本的第一个单元格中。
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
读取和显示经过筛选的数据
创建用于筛选和显示数据的笔记本:
单击侧栏中的“
新建 ”,然后单击“ 笔记本”。(可选)重命名笔记本 筛选器名称数据。
以下 Python 代码读取在上一步中保存的数据并创建表。 它还会创建一个可用于筛选表中数据的小组件。
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
创建作业
要创建的作业由两个任务组成。
创建第一个任务:
在工作区中,单击
 ,然后在边栏中选择作业和管道。
,然后在边栏中选择作业和管道。单击创建,然后选择作业。
单击 “笔记本” 磁贴以配置第一个任务。 如果 笔记本 磁贴不可用,请单击“ 添加其他任务类型 ”并搜索 笔记本。
(可选)将作业的名称(默认为
New Job <date-time>)替换为作业名称。在“任务名称”字段中,输入任务的名称,例如 retrieve-baby-names 。
如有必要,请从“类型”下拉菜单中选择“笔记本”。
在 “源 ”下拉菜单中,选择 “工作区”,以便使用之前保存的笔记本。
对于 Path,请使用文件浏览器查找创建的第一个笔记本,单击笔记本名称,然后单击“ 确认”。
单击“创建任务”。 屏幕右上角会显示一条通知。
创建第二个任务:
单击“ + 添加任务>笔记本”。
在“任务名称”字段中,输入任务的名称,例如 filter-baby-names 。
对于 Path,请使用文件浏览器查找创建的第二个笔记本,单击笔记本名称,然后单击“ 确认”。
在“参数”下单击“添加” 。 在“键”字段中,选择
year。 在“值”字段中,输入 。2014单击“创建任务”。
运行作业
若要立即运行作业,请单击右上角的  。
。
查看运行详细信息
单击“ 运行 ”选项卡,然后单击“ 开始时间”列中 的链接以打开要查看的运行。
单击任一任务以查看输出和详细信息。 例如,单击 filter-baby-names 任务可查看筛选任务的输出和运行详细信息:
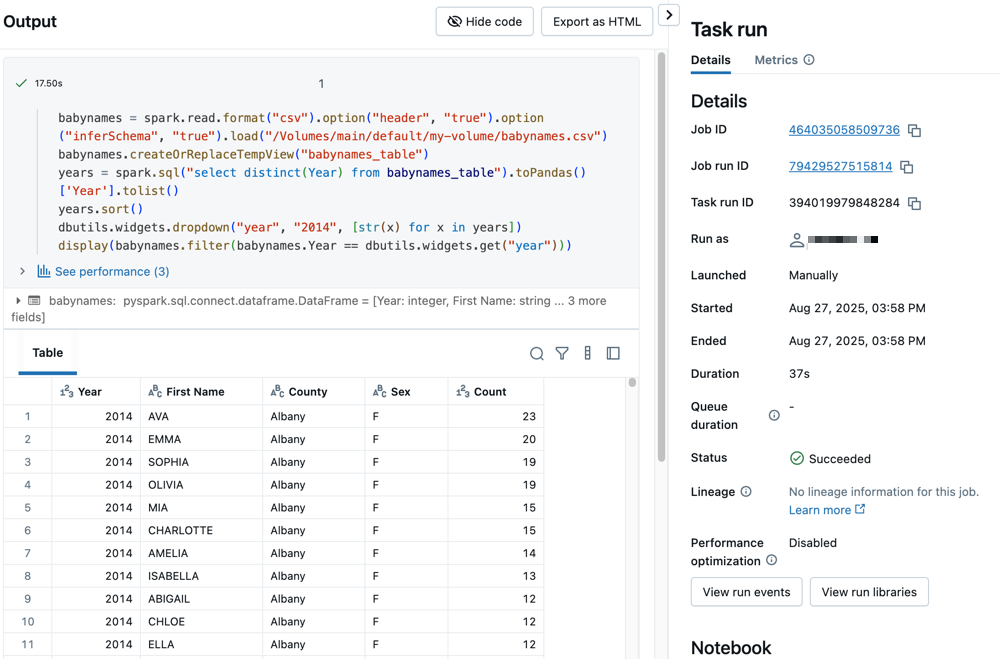
使用不同的参数运行
若要重新运行作业并筛选不同年份的婴儿姓名,请执行以下操作:
单击“
 Blue Down Caret立即运行”旁边的,然后选择“立即运行”,并使用不同的设置。
Blue Down Caret立即运行”旁边的,然后选择“立即运行”,并使用不同的设置。在“值”字段中,输入 。
2015单击 “运行” 。