重要
此功能在 Beta 版中。 工作区管理员可以从 预览 页控制对此功能的访问。 请参阅 管理 Azure Databricks 预览版。
使用 Azure Databricks 的 GenAI 生产监控,您可以在生产 GenAI 应用的跟踪上自动运行 MLflow 3 评分器,以持续监控质量。
可以安排评分系统自动评估生产流量的样本。 评分器的评估结果会自动作为反馈附加到被评估的记录上。
生产监视包括以下内容:
- 使用内置或自定义评分器进行自动化质量评估,包括用于评估整个对话的多 轮次评委 。
- 可配置的采样率,以便控制覆盖率与计算成本之间的权衡。
- 在开发和生产中使用相同的评分器来确保一致的评估。
- 持续质量评估,后台运行监控。
注释
MLflow 3 生产监控与来自 MLflow 2 的跟踪记录兼容。
有关旧版生产监视的信息,请参阅生产监视 API 参考(旧版)。
先决条件
在设置质量监视之前,请确保具备:
- MLflow 实验:正在记录日志的 MLflow 实验。 如果未指定试验,则使用活动试验。
- 有监控的生产应用程序:GenAI 应用必须使用 MLflow 记录追踪信息。 请参阅 生产跟踪指南。
-
定义的记分器:已测试过可与您的应用程序跟踪格式一同使用的记分器。 如果你在开发过程中将生产应用用作
predict_fn中的mlflow.genai.evaluate(),那么你的评分器可能已经兼容。 - SQL 仓库 ID(适用于 Unity Catalog 跟踪):如果跟踪存储在 Unity Catalog 中,则必须配置 SQL 仓库 ID,以使监控功能正常工作。
开始生产监控
本部分包含演示如何创建不同类型的记分器的示例代码。
有关记分器的详细信息,请参阅以下内容:
注释
在任何给定时间,最多 20 名评分者都可以与持续质量监视的实验相关联。
使用 UI 创建和安排 LLM 裁判
可以使用 MLflow UI 基于 LLM 法官创建和测试评分器。
- 导航到 MLflow 试验 UI 中的“ 评分者 ”选项卡。
- 单击 “新建记分器”。
- 从 LLM 模板 下拉菜单中选择内置的 LLM 法官。
- (可选)单击运行记分器以在您的跟踪子集上运行。
- (可选)调整 评估设置 ,以便对将来的跟踪进行生产监视。
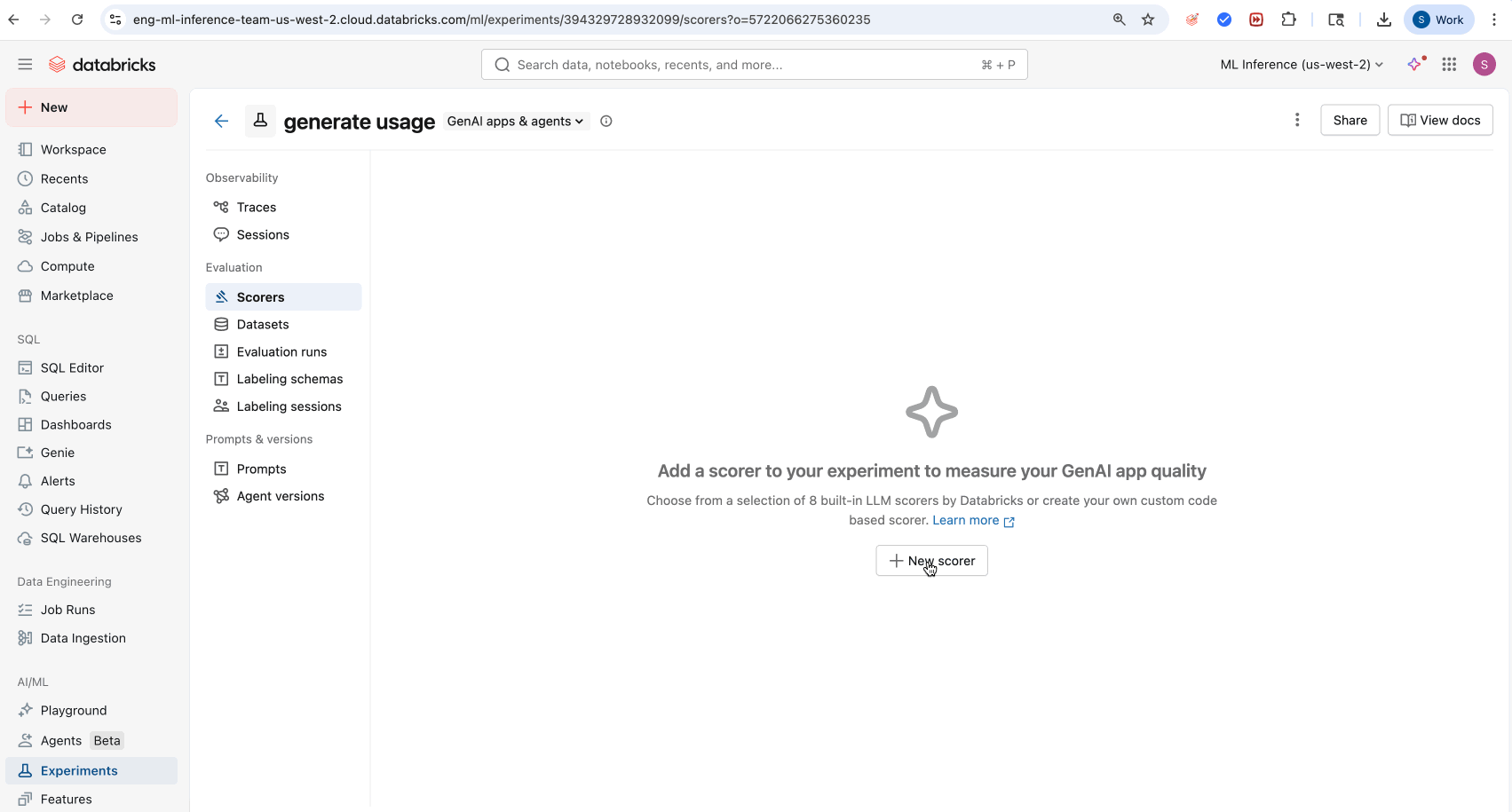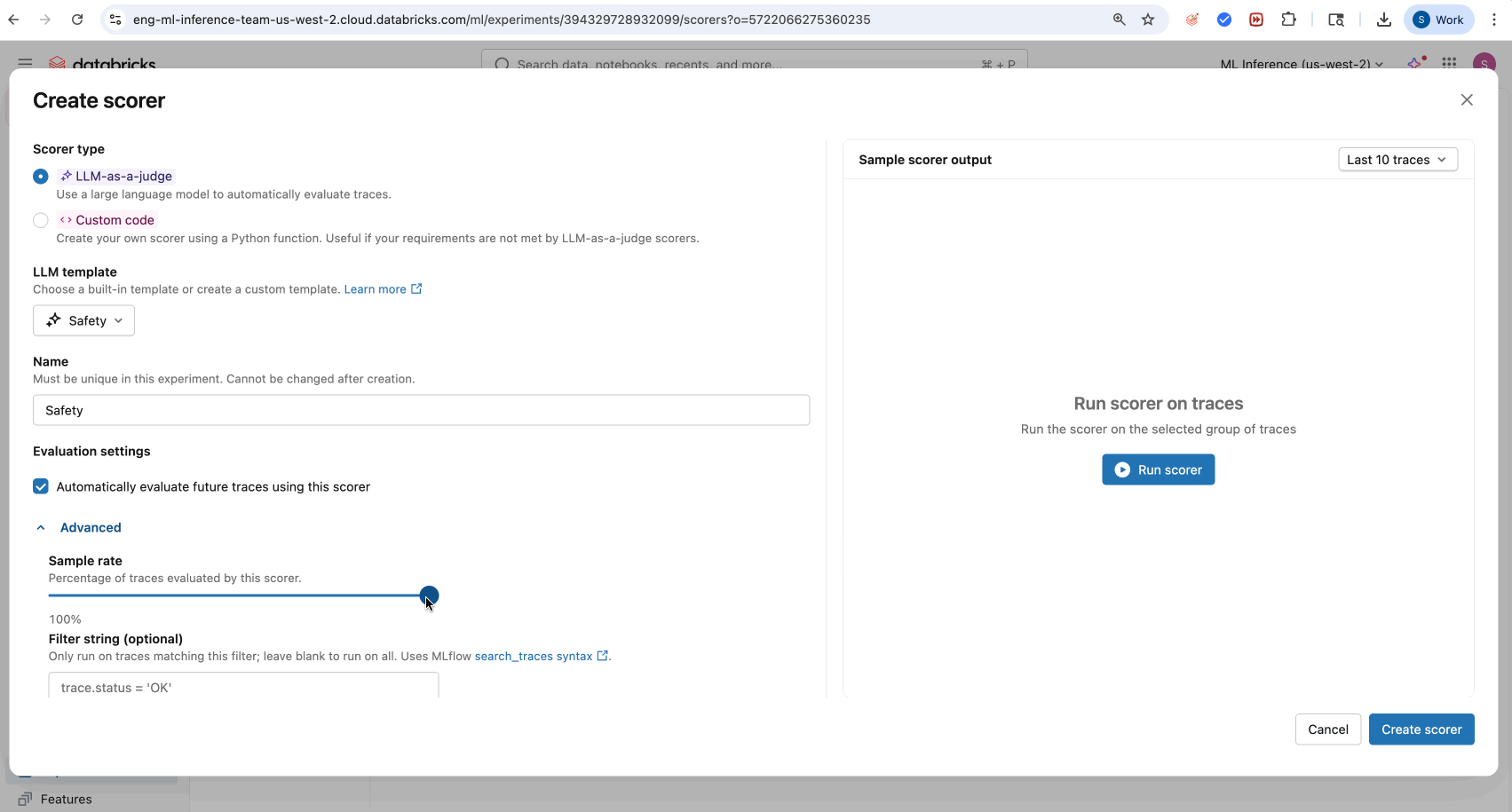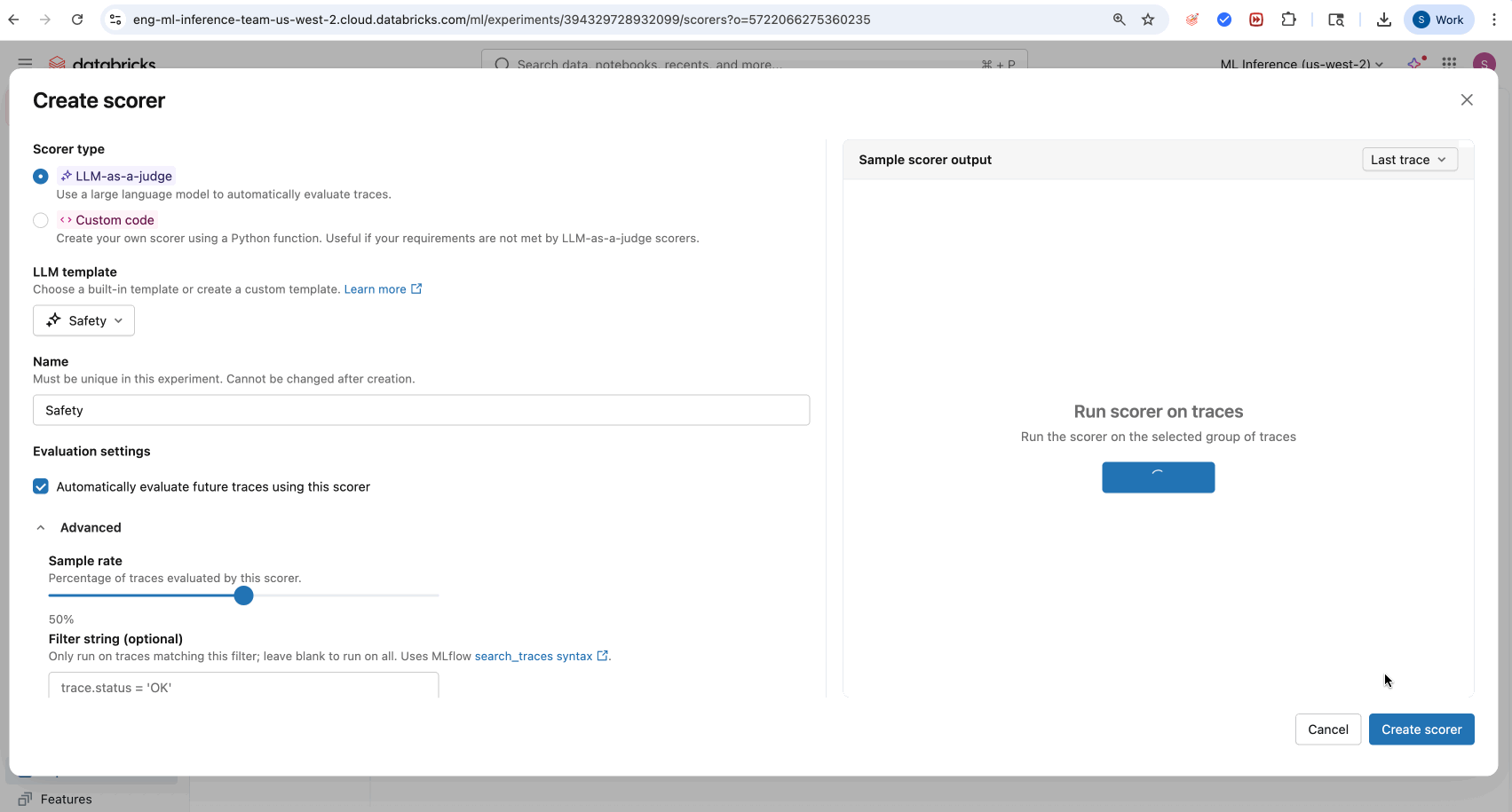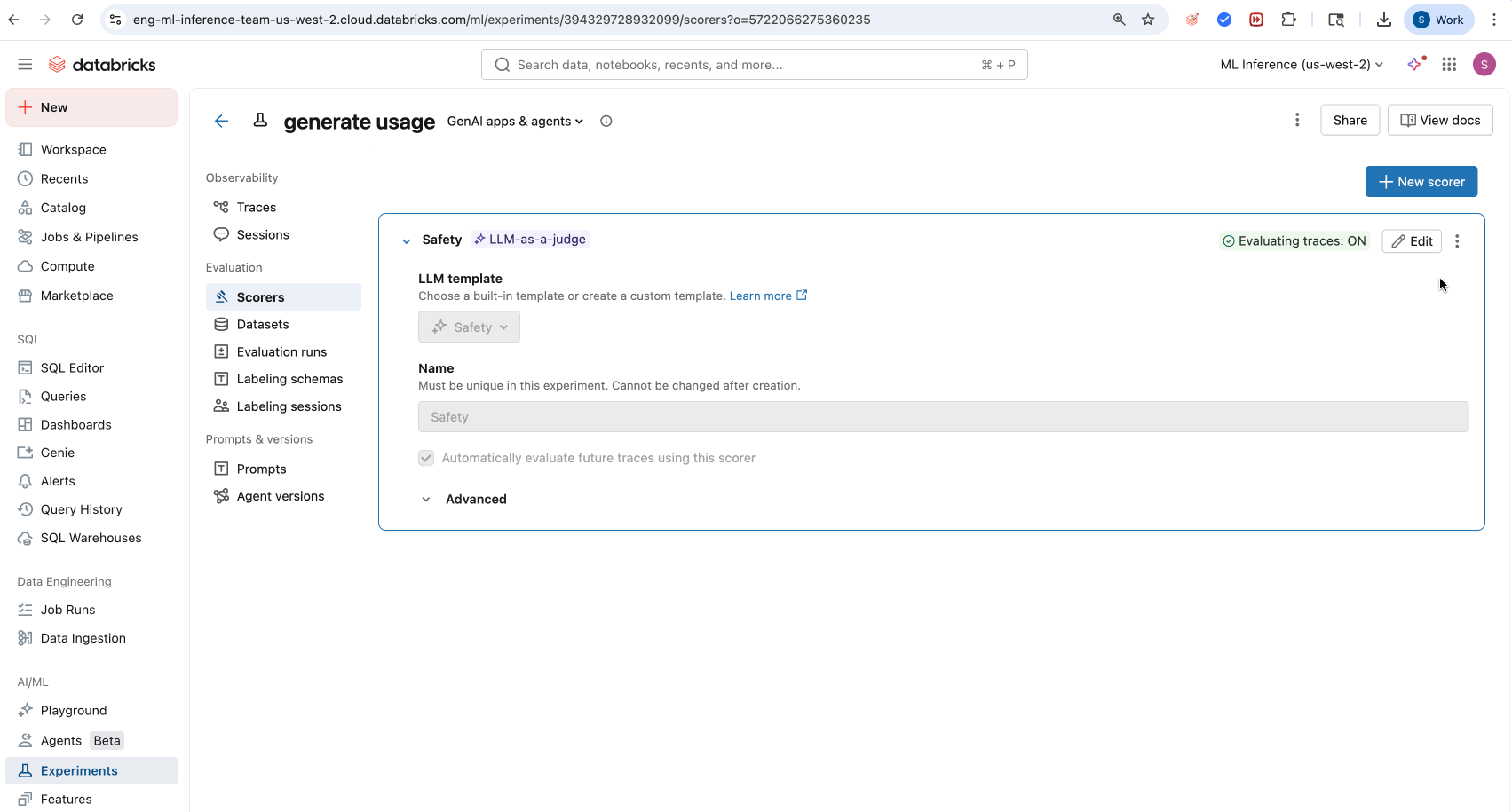
- 单击“ 创建评分器”。
使用内置的 LLM 评估器
MLflow 提供了多个现成可用的内置 LLM 评估器,你可以用于监控。
from mlflow.genai.scorers import Safety, ScorerSamplingConfig
# Register the scorer with a name and start monitoring
safety_judge = Safety().register(name="my_safety_judge") # name must be unique to experiment
safety_judge = safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.7))
默认情况下,每个法官都使用 Databricks 托管的 LLM 来执行 GenAI 质量评估。 可以使用记分器定义中的参数,将评判模型更改为使用 model 的 Databricks 模型服务端点。 必须以格式 databricks:/<databricks-serving-endpoint-name>指定模型。
safety_judge = Safety(model="databricks:/databricks-gpt-oss-20b").register(name="my_custom_safety_judge")
使用指南 LLM 法官
指导LLM 法官 使用通过/未通过的自然语言标准来评估输入和输出。
from mlflow.genai.scorers import Guidelines
# Create and register the guidelines scorer
english_judge = Guidelines(
name="english",
guidelines=["The response must be in English"]
).register(name="is_english") # name must be unique to experiment
# Start monitoring with the specified sample rate
english_judge = english_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.7))
与内置法官一样,可以更改判断模型以改用 Databricks 模型服务终结点。
english_judge = Guidelines(
name="english",
guidelines=["The response must be in English"],
model="databricks:/databricks-gpt-oss-20b",
).register(name="custom_is_english")
在自定义提示中使用 LLM 法官
对于比准则评委更大的灵活性,请使用 LLM 法官和自定义提示 ,从而允许使用可自定义的选择类别进行多级质量评估。
from typing import Literal
from mlflow.genai import make_judge
from mlflow.genai.scorers import ScorerSamplingConfig
# Create a custom judge using make_judge
formality_judge = make_judge(
name="formality",
instructions="""You will look at the response and determine the formality of the response.
Request: {{ inputs }}
Response: {{ outputs }}
Evaluate whether the response is formal, somewhat formal, or not formal.
A response is somewhat formal if it mentions friendship, etc.""",
feedback_value_type=Literal["formal", "semi_formal", "not_formal"],
model="databricks:/databricks-gpt-oss-20b", # optional
)
# Register the custom judge and start monitoring
registered_judge = formality_judge.register(name="my_formality_judge") # name must be unique to experiment
registered_judge = registered_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.1))
使用自定义记分器函数
为了获得最大的灵活性,请定义和使用 自定义记分器函数。
注释
- 仅
@scorer支持基于修饰器的评分器。 无法注册基于Scorer类的子类进行生产监视。 如果需要基于类的评分器,请重构它以改用@scorer修饰器。 - 必须在 Databricks 笔记本中定义和注册评分器。 监视服务序列化用于远程执行的记分器函数代码,并且此序列化需要笔记本环境。 无法在独立 Python 文件或本地 IDE 环境中定义的记分器进行序列化,以便进行生产监视。
- 记分器必须是自给自足的。 由于记分器函数序列化为用于远程执行的代码,因此必须在函数体内内完成所有导入。 该函数不能引用其外部定义的变量、对象或模块。 定义自定义记分器时,请勿使用需要在函数签名中导入的类型提示。 如果记分器函数正文使用需要导入的包,请将这些包内联导入函数,以确保正确序列化。
某些软件包默认可用,无需进行内联导入操作。 这些包包括databricks-agents、mlflow-skinny和openai无服务器环境版本 2 中包含的所有包。
from mlflow.genai.scorers import scorer, ScorerSamplingConfig
# Custom metric: Check if response mentions Databricks
@scorer
def mentions_databricks(outputs):
"""Check if the response mentions Databricks"""
return "databricks" in str(outputs.get("response", "")).lower()
# Custom metric: Response length check
@scorer(aggregations=["mean", "min", "max"])
def response_length(outputs):
"""Measure response length in characters"""
return len(str(outputs.get("response", "")))
# Custom metric with multiple inputs
@scorer
def response_relevance_score(inputs, outputs):
"""Score relevance based on keyword matching"""
query = str(inputs.get("query", "")).lower()
response = str(outputs.get("response", "")).lower()
# Simple keyword matching (replace with your logic)
query_words = set(query.split())
response_words = set(response.split())
if not query_words:
return 0.0
overlap = len(query_words & response_words)
return overlap / len(query_words)
# Register and start monitoring custom scorers
databricks_scorer = mentions_databricks.register(name="databricks_mentions")
databricks_scorer = databricks_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
length_scorer = response_length.register(name="response_length")
length_scorer = length_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0))
relevance_scorer = response_relevance_score.register(name="response_relevance_score") # name must be unique to experiment
relevance_scorer = relevance_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0))
使用多轮评审法官
生产监视支持 多轮次评委 来评估整个对话,而不是单个跟踪。 这些评委评估在多个互动(例如用户的沮丧情绪、对话的完整性和知识保留度)中出现的质量范式。
多回合评委的登记和启动方式与单回合评委完全一样。 监视作业自动根据mlflow.trace.session标签将跟踪分组到对话中。 多轮对话评审在会话被认为完成后进行——默认情况下,当没有新的包含该会话 ID 的轨迹被摄入超过5 分钟时,会话将被视为完成。 若要配置此缓冲区,请在 MLFLOW_ONLINE_SCORING_DEFAULT_SESSION_COMPLETION_BUFFER_SECONDS 监视作业上设置环境变量。
注释
若要使用多轮次法官,代理必须在追踪记录上设置会话 ID。 有关详细信息 ,请参阅“跟踪用户和会话 ”。
from mlflow.genai.scorers import (
ConversationCompleteness,
UserFrustration,
ConversationalSafety,
ScorerSamplingConfig,
)
# Register and start multi-turn judges just like single-turn judges
completeness_scorer = ConversationCompleteness().register(name="conversation_completeness")
completeness_scorer = completeness_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0),
)
frustration_scorer = UserFrustration().register(name="user_frustration")
frustration_scorer = frustration_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0),
)
safety_scorer = ConversationalSafety().register(name="conversational_safety")
safety_scorer = safety_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.5),
)
关于可用的多轮对话判定器的完整列表,请参阅多轮对话判定器。 有关对话评估的详细信息,请参阅 “评估对话”。
多个记分器配置
若要进行全面的监视设置,请单独注册并启动多个评分器。 可以在同一实验中组合单轮和多轮次评委。
from mlflow.genai.scorers import Safety, Guidelines, UserFrustration, ScorerSamplingConfig, list_scorers
# Register single-turn judges
safety_judge = Safety().register(name="safety") # name must be unique within an MLflow experiment
safety_judge = safety_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0), # Check all traces
)
guidelines_judge = Guidelines(
name="english",
guidelines=["Response must be in English"]
).register(name="english_check")
guidelines_judge = guidelines_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.5), # Sample 50%
)
# Register multi-turn judges alongside single-turn judges
frustration_judge = UserFrustration().register(name="user_frustration")
frustration_judge = frustration_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0), # Check all sessions
)
# List and manage all judges (both single-turn and multi-turn)
all_scorers = list_scorers()
for scorer in all_scorers:
if scorer.sample_rate > 0:
print(f"{scorer.name} is active")
else:
print(f"{scorer.name} is stopped")
记分器生命周期
记分器生命周期以 MLflow 试验为中心。 下表列出了记分器生命周期状态。
记分器是不 可变的,因此生命周期作不会修改原始评分器。 而是返回一个新的记分器实例。
| 州 | 说明 | API |
|---|---|---|
| 未注册 | 已定义计分函数,但服务器无法识别。 | |
| 注册 | 记分器注册到活动的 MLflow 实验。 | .register() |
| 积极 | 记分器以采样率 > 0 运行。 | .start() |
| 已停止 | 计分器已注册但未运行(采样率 = 0)。 | .stop() |
| 已删除 | 记分器已从服务器中删除,不再与其 MLflow 试验相关联。 | delete_scorer() |
基本记分器生命周期
from mlflow.genai.scorers import Safety, scorer, ScorerSamplingConfig
# Built-in scorer lifecycle
safety_judge = Safety().register(name="safety_check")
safety_judge = safety_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0),
)
safety_judge = safety_judge.update(
sampling_config=ScorerSamplingConfig(sample_rate=0.8),
)
safety_judge = safety_judge.stop()
delete_scorer(name="safety_check")
# Custom scorer lifecycle
@scorer
def response_length(outputs):
return len(str(outputs.get("response", "")))
length_scorer = response_length.register(name="length_check")
length_scorer = length_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.5),
)
管理记分器
以下 API 可用于管理记分器。
| API | 说明 | 示例 |
|---|---|---|
list_scorers() |
列出当前试验的所有已注册评分器。 | 列出当前评分者 |
get_scorer() |
按名称检索已注册的记分器。 | 获取和更新记分器 |
Scorer.update() |
修改活动评分器的采样配置。 这是一个不可变的操作。 | 获取和更新记分器 |
backfill_scorer() |
追溯性地将新的或更新的指标应用于历史跟踪。 | 评估历史痕迹(度量补全) |
delete_scorer() |
按名称删除已注册的记分器。 | 停止和删除评分器 |
列出当前评分者
若要查看实验的所有已注册的打分器,请执行以下步骤:
from mlflow.genai.scorers import list_scorers
# List all registered scorers
scorers = list_scorers()
for scorer in scorers:
print(f"Name: {scorer._server_name}")
print(f"Sample rate: {scorer.sample_rate}")
print(f"Filter: {scorer.filter_string}")
print("---")
获取和更新评分器
修改现有评分器配置:
from mlflow.genai.scorers import get_scorer
# Get existing scorer and update its configuration (immutable operation)
safety_judge = get_scorer(name="safety_monitor")
updated_judge = safety_judge.update(sampling_config=ScorerSamplingConfig(sample_rate=0.8)) # Increased from 0.5
# Note: The original scorer remains unchanged; update() returns a new scorer instance
print(f"Original sample rate: {safety_judge.sample_rate}") # Original rate
print(f"Updated sample rate: {updated_judge.sample_rate}") # New rate
停止和删除评分器
完全停止监视或删除记分器:
from mlflow.genai.scorers import get_scorer, delete_scorer
# Get existing scorer
databricks_scorer = get_scorer(name="databricks_mentions")
# Stop monitoring (sets sample_rate to 0, keeps scorer registered)
stopped_scorer = databricks_scorer.stop()
print(f"Sample rate after stop: {stopped_scorer.sample_rate}") # 0
# Remove scorer entirely from the server
delete_scorer(name=databricks_scorer.name)
# Or restart monitoring from a stopped scorer
restarted_scorer = stopped_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
不可变更新
评分员,包括 LLM 法官,是不可变的对象。 更新记分器时,不会修改原始记分器。 而是创建评分器的更新副本。 这种不可变性有助于确保用于生产的记分器不会被意外修改。 以下代码片段演示不可变更新的工作原理。
# Demonstrate immutability
original_judge = Safety().register(name="safety")
original_judge = original_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.3),
)
# Update returns new instance
updated_judge = original_judge.update(
sampling_config=ScorerSamplingConfig(sample_rate=0.8),
)
# Original remains unchanged
print(f"Original: {original_judge.sample_rate}") # 0.3
print(f"Updated: {updated_judge.sample_rate}") # 0.8
评估历史数据(指标回填)
可以追溯性地将新的或更新的指标应用于历史跟踪。
使用当前采样率进行基础指标回填
from databricks.agents.scorers import backfill_scorers
safety_judge = Safety()
safety_judge.register(name="safety_check")
safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
#custom scorer
@scorer(aggregations=["mean", "min", "max"])
def response_length(outputs):
"""Measure response length in characters"""
return len(outputs)
response_length.register(name="response_length")
response_length.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
# Use existing sample rates for specified scorers
job_id = backfill_scorers(
scorers=["safety_check", "response_length"]
)
使用自定义采样率和时间范围的指标回填
from databricks.agents.scorers import backfill_scorers, BackfillScorerConfig
from datetime import datetime
from mlflow.genai.scorers import Safety, Correctness
safety_judge = Safety()
safety_judge.register(name="safety_check")
safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
#custom scorer
@scorer(aggregations=["mean", "min", "max"])
def response_length(outputs):
"""Measure response length in characters"""
return len(outputs)
response_length.register(name="response_length")
response_length.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
# Define custom sample rates for backfill
custom_scorers = [
BackfillScorerConfig(scorer=safety_judge, sample_rate=0.8),
BackfillScorerConfig(scorer=response_length, sample_rate=0.9)
]
job_id = backfill_scorers(
experiment_id=YOUR_EXPERIMENT_ID,
scorers=custom_scorers,
start_time=datetime(2024, 6, 1),
end_time=datetime(2024, 6, 30)
)
最近的数据回填
from datetime import datetime, timedelta
# Backfill last week's data with higher sample rates
one_week_ago = datetime.now() - timedelta(days=7)
job_id = backfill_scorers(
scorers=[
BackfillScorerConfig(scorer=safety_judge, sample_rate=0.8),
BackfillScorerConfig(scorer=response_length, sample_rate=0.9)
],
start_time=one_week_ago
)
查看结果
计划记分器后,允许 15-20 分钟进行初始处理。 然后:
- 进入您的 MLflow 实验。
- 打开 Traces 选项卡,查看附加到追踪的评估。
- 使用监视仪表板跟踪质量趋势。
对于多轮对话评审,评估会附在每个会话中的第一个轨迹上。 有关详细信息 ,请参阅评估的存储方式 。
最佳做法
记分器状态管理
- 在使用
sample_rate进行操作之前检查记分器状态。 - 使用不可变模式。 将结果
.start().update().stop()分配给变量。 - 了解记分器生命周期。
.stop()保留注册,delete_scorer()完全删除记分器。
指标回填
- 从小开始。 从较小的时间范围开始,以估计作业持续时间和资源使用情况。
- 使用适当的采样率。 考虑使用高采样率的成本和时间影响。
采样策略
对于安全性和安保检查等关键评分标准,请使用
sample_rate=1.0。对于昂贵的评分系统,例如复杂的 LLM 模型,应使用较低的采样率(0.05-0.2)。
若要在开发期间进行迭代改进,请使用中等速率(0.3-0.5)。
平衡覆盖范围与成本,如以下示例所示:
# High-priority scorers: higher sampling safety_judge = Safety().register(name="safety") safety_judge = safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0)) # 100% coverage for critical safety # Expensive scorers: lower sampling complex_scorer = ComplexCustomScorer().register(name="complex_analysis") complex_scorer = complex_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.05)) # 5% for expensive operations
自定义记分器设计
使自定义评分器保持独立,如以下示例所示:
@scorer
def well_designed_scorer(inputs, outputs):
# All imports inside the function
import re
import json
# Handle missing data gracefully
response = outputs.get("response", "")
if not response:
return 0.0
# Return consistent types
return float(len(response) > 100)
Troubleshooting
记分器未运行
如果评分人员没有执行任务,请检查以下内容:
- 检查实验:确保将日志记录到实验,而不是记录到单个运行。
- 采样率:采样率较低,可能需要时间才能查看结果。
-
验证筛选器字符串:确保
filter_string匹配实际跟踪信息。
序列化问题
用于生产监视的自定义记分器已序列化,以便监视服务远程执行这些评分器。 这会施加多个约束:
-
笔记本要求:必须从 Databricks 笔记本定义和注册自定义
@scorer函数。 序列化机制依赖于笔记本环境。 - 自包含函数:所有导入都必须在函数体内内内联。 在序列化期间不会捕获对在函数外部定义的外部变量、模块或对象的引用。
-
没有基于类的评分器:只能注册
@scorer基于修饰器的评分器。 无法序列化基于Scorer类的子类以便进行远程执行。 -
不需要导入的类型提示:函数签名中的类型提示如果需要导入语句(例如,从
List导入typing),会导致序列化失败。
创建自定义评分器时,在函数定义中包含导入。
# ❌ Avoid external dependencies
import external_library # Outside function
@scorer
def bad_scorer(outputs):
return external_library.process(outputs)
# ✅ Include imports in the function definition
@scorer
def good_scorer(outputs):
import json # Inside function
return len(json.dumps(outputs))
# ❌ Avoid using type hints in scorer function signature that requires imports
from typing import List
@scorer
def scorer_with_bad_types(outputs: List[str]):
return False
# ❌ Class-based scorers are not supported for production monitoring
class MyScorer(Scorer):
name: str = "my_scorer"
def __call__(self, outputs):
return len(outputs) > 10
指标回填问题
“试验中未找到计划的记分器 'X' ”
- 确保记分器名称与实验中已注册的记分器匹配。
- 使用
list_scorers方法检查可用的记分器。
存档跟踪
可以将跟踪及其关联的评估保存到 Unity 目录 Delta 表,以便进行长期存储和高级分析。 这对于生成自定义仪表板、对跟踪数据执行深入分析以及维护应用程序行为的持久记录非常有用。
注释
必须具有写入指定 Unity Catalog Delta 表所需的权限。 如果目标表尚不存在,将创建该表。
如果该表已存在,则数据跟踪将追加到该表。
启用存档跟踪
MLflow API
若要开始归档实验的跟踪,请使用函数 enable_databricks_trace_archival 。 必须指定目标 Delta 表的完整名称,包括目录和架构。 如果未提供 experiment_id,则会为当前活动试验启用存档跟踪。
from mlflow.tracing.archival import enable_databricks_trace_archival
# Archive traces from a specific experiment to a Unity Catalog Delta table
enable_databricks_trace_archival(
delta_table_fullname="my_catalog.my_schema.archived_traces",
experiment_id="YOUR_EXPERIMENT_ID",
)
使用 disable_databricks_trace_archival 函数随时停止存档试验的跟踪。
from mlflow.tracing.archival import disable_databricks_trace_archival
# Stop archiving traces for the specified experiment
disable_databricks_trace_archival(experiment_id="YOUR_EXPERIMENT_ID")
Databricks 用户界面
若要在 UI 中存档实验的跟踪,请执行以下步骤:
- 转到 Databrick 工作区中的“试验”页。
- 单击 “增量同步:未启用”。
- 指定目标 Delta 表的完整名称,包括目录和架构。
若要禁用跟踪存档,请执行:
- 转到 Databrick 工作区中的“试验”页。
- 单击 “增量同步:已启用”>禁用同步。
后续步骤
参考指南
- 记分器生命周期管理 API 参考 - 用于管理记分器以监视的 API 和示例。
- 记分器 - 了解电源监视的指标。
- Evaluation Harness - 脱机评估与生产的关系。