本页提供了用于管理各种用户界面、工具、库和语言的 Unity 目录 卷 中的文件的示例。
Databricks 建议使用卷来管理对云对象存储中非表格数据的所有访问,以及存储工作负荷支持文件。 示例包括:
- 用于引入的数据文件,例如 CSV、JSON 和 Parquet
- 用于数据科学、ML 和 AI 工作负载的文本、图像和音频文件
- 由 Azure Databricks 编写的用于与外部系统集成的 CSV 或 JSON 工件
- 库、初始化脚本和构建产物
卷提供可移植操作系统接口(POSIX)样式的路径,这些路径能够与基于用户空间文件系统(FUSE)的工具和框架一起使用。 这使得它们非常适合需要 POSIX 样式访问的机器学习框架和开源 Python 模块。 有关 URI 方案、POSIX 路径及其与卷的关系的详细信息,请参阅是否需要提供用于访问数据的 URI 方案?
管理卷中的文件的方法
有关每个方法的快速示例,请参阅 在 Unity Catalog 卷中处理文件。
| 接口 | Description |
|---|---|
| Catalog Explorer 界面 | 通过 Azure Databricks 工作区进行交互式文件管理 |
| 编程访问 | 使用 Apache Spark、Pandas 或 SQL 读取和写入文件 |
| Databricks 实用工具 | 在笔记本中使用 dbutils.fs 或 magic 命令(%fs, %sh)进行文件操作 |
| SQL 命令 | 使用 SQL 关键字(LIST、PUT INTO、GET、REMOVE)和连接器的文件操作 |
| Databricks CLI | 使用 databricks fs 命令的命令行操作 |
| SDK | 使用 Python、Java 或 Go SDK 执行文件操作 |
| REST API | 自定义集成的直接 API 访问 |
使用目录浏览器
目录资源管理器提供了用于使用 Unity 目录卷存储的文件的常见文件管理任务的选项。
若要与卷中的文件交互,请执行以下操作:
在 Azure Databricks 工作区中,单击
 目录。
目录。搜索或浏览要使用的卷并将其选中。
有关创建和管理卷的详细信息,请参阅 创建和管理 Unity 目录卷。
将文件上传到卷
可以将任何格式的文件(包括结构化、半结构化或非结构化)上传到卷。 通过 UI 上传时,文件大小限制为 5 GB。 但是,卷本身支持的文件大小可达到底层云存储所支持的最大上限。 可以使用 Spark 编写非常大的文件,并使用 Azure Databricks API 或 SDK 上传大型文件。
要求
在上传到卷之前,请确保具有以下各项:
- 启用了 Unity Catalog 的工作区
-
WRITE VOLUME在目标卷上 -
USE SCHEMA父架构上的 -
USE CATALOG于父目录中
有关详细信息,请参阅 Unity 目录特权和安全对象。
上传步骤
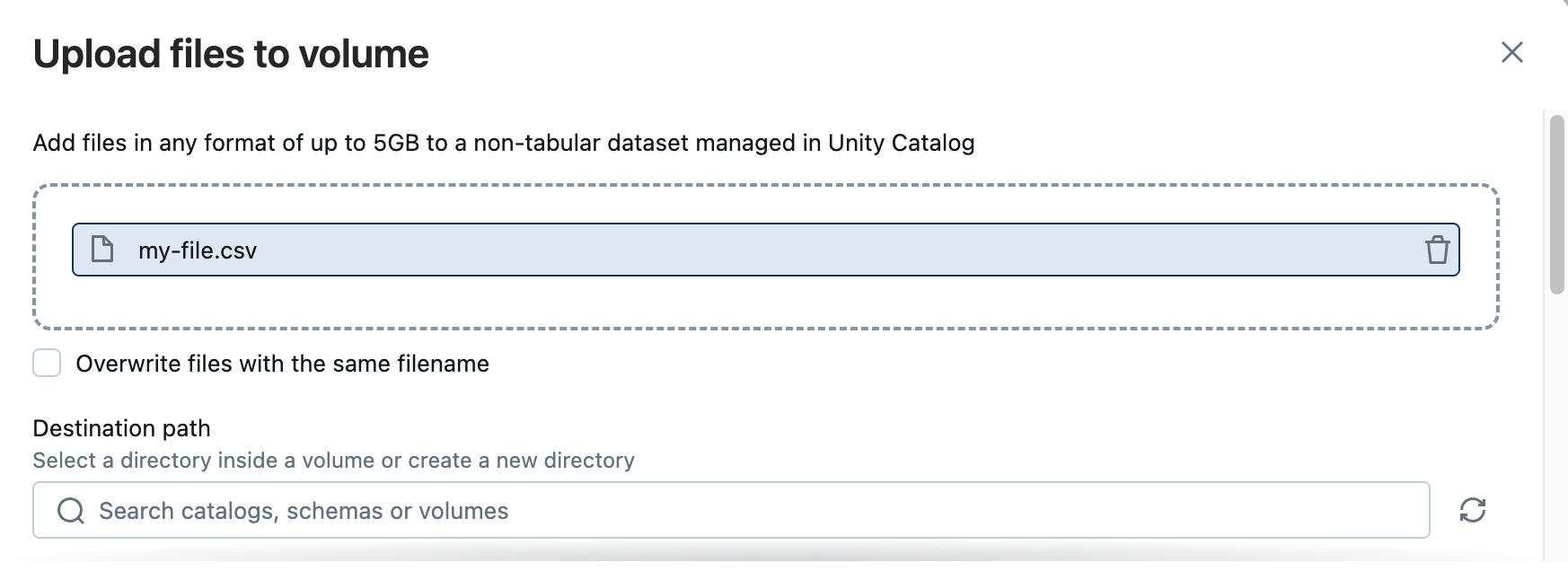
在目录资源管理器中,单击“ 将数据>上传到卷”。
单击“ 浏览 ”或“将文件拖放到放置区域”。
选择卷或目录,或粘贴卷路径。
- 如果目标架构中不存在卷,请创建一个卷。
- 还可以在目标卷中创建新目录。
还可以通过以下方式访问上传 UI:
- 在边栏中: 新建>将数据>上传到卷
- 从笔记本: 文件>将文件上传到卷
后续步骤
上传到卷后,可以执行以下操作:
从文件创建 Unity 目录托管表。 请参阅 从卷中的数据创建表。
在机器学习和数据科学工作负载中使用文件
使用上传的文件,配置群集库、笔记本限定的库或作业依赖项。
从卷中下载文件
若要从卷下载文件,请执行以下操作:
选择一个或多个文件。
单击“下载”以下载这些文件。
删除卷中的文件
若要删除卷中的文件,请执行以下操作:
选择一个或多个文件。
单击 “删除” 。
单击“删除”,在出现的对话框中确认删除。
创建空目录
若要在卷中创建新目录,请执行以下操作:
在“卷概述”选项卡上,单击“ 创建目录”。
输入目录名称。
单击 “创建” 。
下载目录
在卷中要下载一个目录时,请执行以下操作:
- 单击
 目录右侧的 kebab 菜单。
目录右侧的 kebab 菜单。 - 单击“ 下载目录”。
目录以 ZIP 文件的形式下载。
从卷中删除目录
若要从卷中删除目录,请执行以下操作:
选择一个或多个目录。
单击 “删除” 。
单击“删除”,在出现的对话框中确认删除。
卷的 UI 文件管理任务
单击文件名旁的![]() 以进行以下操作:
以进行以下操作:
- 复制路径
- 下载文件
- 删除文件
- 创建表
从数据卷创建表格
Azure Databricks 提供了一个 UI,用于从存储在 Unity Catalog 卷中的文件或文件目录创建 Unity Catalog 托管表。
必须在目标架构中具有 CREATE TABLE 权限,并且有权访问正在运行的 SQL 仓库。
选择一个或多个文件或一个目录。 文件应该具有相同的数据布局。
单击“创建表”。 此时会显示“从卷创建表”对话框。
使用提供的对话框查看数据预览并完成以下配置:
- 选择“创建新表”或“覆盖现有表”
- 选择目标目录和架构。
- 指定表名称。
- (可选)替代默认列名和类型,或选择排除列。
注释
单击“高级属性”可查看其他选项。
单击“创建表”以创建具有指定属性的表。 完成后,目录资源管理器会显示表详细信息。
以编程方式处理卷中的文件
使用以下格式从所有受支持的语言和工作区编辑器中读取和写入卷中的文件:
/Volumes/catalog_name/schema_name/volume_name/path/to/files
您与卷中的文件交互的方式与在任何云对象存储位置交互文件的方式相同。 这意味着,如果当前管理使用云 URI、DBFS 装载路径或 DBFS 根路径来与数据或文件交互的代码,则可以更新代码以改用卷。
注释
卷仅用于非表格数据。 Databricks 建议使用 Unity Catalog 表注册表格数据,然后使用表名读取和写入数据。
在卷中读取和写入数据
使用 Apache Spark、pandas、Spark SQL 和其他 OSS 库来读取和写入大量数据文件。
以下示例演示如何读取存储在卷中的 CSV 文件:
Python
df = spark.read.format("csv").load("/Volumes/catalog_name/schema_name/volume_name/data.csv")
display(df)
Pandas
import pandas as pd
df = pd.read_csv('/Volumes/catalog_name/schema_name/volume_name/data.csv')
display(df)
SQL
SELECT * FROM csv.`/Volumes/catalog_name/schema_name/volume_name/data.csv`
针对卷中文件的实用程序命令
Databricks 提供了以下工具来管理磁盘卷中的文件:
- Databricks 实用程序中的
dbutils.fs子模块。 请参阅文件系统实用工具 (dbutils.fs)。 -
%fsmagic 是dbutils.fs的别名。 -
%shmagic,它允许针对卷执行 bash 命令。
有关使用这些工具从 Internet 下载文件、解压缩文件和将文件从临时块存储移动到卷的示例,请参阅从 Internet 下载数据。
还可以对文件实用工具命令(如 Python os 模块)使用 OSS 包,如以下示例所示:
import os
os.mkdir('/Volumes/catalog_name/schema_name/volume_name/directory_name')
使用外部工具管理卷内的文件
Databricks 提供了一套工具,用于从本地环境或集成系统以编程方式管理卷中的文件。
卷中文件的 SQL 命令
Azure Databricks 支持以下 SQL 关键字用于与卷中的文件交互:
在 Azure Databricks 笔记本和 SQL 查询编辑器中,仅 LIST 支持该命令。 其他 SQL 命令(PUT INTO和GETREMOVE)可通过以下 Databricks SQL 连接器和驱动程序获得,这些连接器和驱动程序支持管理卷中的文件:
- 适用于 Python 的 Databricks SQL 连接器
- 用于 Go 的 Databricks SQL 驱动程序
- 用于 Node.js的 Databricks SQL 驱动程序
- Databricks JDBC 驱动程序
- Databricks ODBC 驱动程序
使用 Databricks CLI 管理数据卷中的文件
使用 databricks fs 子命令。 请参阅 fs 命令组。
注释
Databricks CLI 要求方案 dbfs:/ 位于所有卷路径之前。 例如,dbfs:/Volumes/catalog_name/schema_name/volume_name/path/to/data。
使用 SDK 管理卷中的文件
以下 SDK 支持管理卷中的文件:
- 适用于 Python 的 Databricks SDK。 使用 WorkspaceClient.files 中的可用方法。 有关示例,请参阅管理 Unity Catalog 卷中的文件。
- 适用于 Java 的 Databricks SDK。 使用 WorkspaceClient.files 中的可用方法。 有关示例,请参阅管理 Unity Catalog 卷中的文件。
- 适用于 Go 的 Databricks SDK。 使用 WorkspaceClient.files 中的可用方法。 有关示例,请参阅管理 Unity Catalog 卷中的文件。
使用 REST API 管理卷中的文件
使用文件 API 管理卷中的文件。
卷中文件的 REST API 示例
以下示例使用 curl 和 Databricks REST API 在卷中执行文件管理任务。
以下示例在指定卷中创建名为 my-folder 的空文件夹。
curl --request PUT "https://${DATABRICKS_HOST}/api/2.0/fs/directories/Volumes/main/default/my-volume/my-folder/" \
--header "Authorization: Bearer ${DATABRICKS_TOKEN}"
以下示例创建一个名为 data.csv 的文件,其中包含卷中指定路径中的指定数据。
curl --request PUT "https://${DATABRICKS_HOST}/api/2.0/fs/files/Volumes/main/default/my-volume/my-folder/data.csv?overwrite=true" \
--header "Authorization: Bearer ${DATABRICKS_TOKEN}" \
--header "Content-Type: application/octet-stream" \
--data-binary $'id,Text\n1,Hello World!'
以下示例列出指定路径中卷的内容。 此示例使用 jq 设置响应正文 JSON 的格式,以便于阅读。
curl --request GET "https://${DATABRICKS_HOST}/api/2.0/fs/directories/Volumes/main/default/my-volume/" \
--header "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq .
以下示例列出指定路径中一个卷上的文件夹内容。 此示例使用 jq 设置响应正文 JSON 的格式,以便于阅读。
curl --request GET "https://${DATABRICKS_HOST}/api/2.0/fs/directories/Volumes/main/default/my-volume/my-folder" \
--header "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq .
以下示例显示存储卷中指定路径下文件的内容。
curl --request GET "https://${DATABRICKS_HOST}/api/2.0/fs/files/Volumes/main/default/my-volume/my-folder/data.csv" \
--header "Authorization: Bearer ${DATABRICKS_TOKEN}"
以下示例从卷中删除指定路径中的文件。
curl --request DELETE "https://${DATABRICKS_HOST}/api/2.0/fs/files/Volumes/main/default/my-volume/my-folder/data.csv" \
--header "Authorization: Bearer ${DATABRICKS_TOKEN}"
以下示例删除指定卷中的文件夹。
curl --request DELETE "https://${DATABRICKS_HOST}/api/2.0/fs/directories/Volumes/main/default/my-volume/my-folder/" \
--header "Authorization: Bearer ${DATABRICKS_TOKEN}"
在卷中操作或使用文件的限制
在处理卷内的文件之前,请考虑以下限制:
不支持直接追加或非顺序(随机)写入。 这会影响写入 Zip 和 Excel 文件等操作。 对于这些工作负载:
- 首先对本地磁盘执行操作
- 将结果复制到该卷
例如:
# python import xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/Volumes/my_catalog/my_schema/my_volume/excel.xlsx')不支持稀疏文件。 若要复制稀疏文件,请使用
cp --sparse=never:$ cp sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file error writing '/dbfs/sparse.file': Operation not supported $ cp --sparse=never sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file