适用于: Azure CLI ml 扩展 v2 (当前版本)Python SDK azure-ai-ml v2 (当前版本)
Azure CLI ml 扩展 v2 (当前版本)Python SDK azure-ai-ml v2 (当前版本)
本文介绍如何在生产环境中部署新版本的 machine learning 模型,而不会造成任何中断。 使用蓝绿部署策略(也称为安全推出策略)将新版本的 Web 服务引入生产环境。 使用此策略时,在完全推出 Web 服务之前,请将新版本的 Web 服务推广到一小部分用户或请求。
本文假定你使用联机终结点或用于联机(实时)推理的终结点。 存在两种类型的联机终结点: 托管联机终结点 和 Kubernetes 联机终结点。 有关终结点的详细信息以及终结点类型之间的差异,请参阅 托管联机终结点与 Kubernetes 联机终结点。
本文使用托管联机终结点进行部署。 但它还包括注释,说明如何利用 Kubernetes 终结点而不是托管联机终结点。
在这篇文章中,你将学会如何:
- 定义一个在线终结点,并使用名为
blue的部署来服务于模型的第一个版本。
- 扩展
blue部署,使其能够处理更多请求。
- 将第二个版本的模型(称为
green 部署)部署到终结点,但不向该部署发送实时流量。
- 在隔离环境中测试
green 部署。
- 将一部分实时流量镜像到
green 部署以验证部署。
- 将一小部分实时流量发送到
green 部署。
- 将所有实时流量发送到
green 部署。
- 删除未使用的
blue 部署。
先决条件
至少具有以下Azure基于角色的访问控制(Azure RBAC)角色之一的用户帐户:
- Azure Machine Learning工作区的所有者角色
- Azure Machine Learning工作区的参与者角色
- 具有
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* 权限的自定义角色
有关详细信息,请参阅 管理访问 Azure 机器学习工作区。
(可选)在本地安装并运行 Docker 引擎。 强烈建议使用此先决条件。 您需要它来在本地部署模型,它还有助于调试。
适用于:Python SDK azure-ai-ml v2(当前)
Azure Machine Learning工作区。 有关创建工作区的步骤,请参阅 “创建工作区”。
适用于 Python v2 的 Azure Machine Learning SDK。 若要安装 SDK,请使用以下命令:
pip install azure-ai-ml azure-identity
要将 SDK 的现有安装更新到最新版本,请使用以下命令:
pip install --upgrade azure-ai-ml azure-identity
有关详细信息,请参阅 Azure Machine Learning 包的 Python 客户端库。
Python 3.10 或更高版本。
至少具有以下Azure基于角色的访问控制(Azure RBAC)角色之一的用户帐户:
- Azure Machine Learning工作区的所有者角色
- Azure Machine Learning工作区的参与者角色
- 具有
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* 权限的自定义角色
有关详细信息,请参阅 管理访问 Azure 机器学习工作区。
(可选)在本地安装并运行 Docker 引擎。 强烈建议使用此先决条件。 您需要它来在本地部署模型,它还有助于调试。
一个 Azure 订阅。 如果没有Azure订阅,请在开始前创建 Trial。
Azure Machine Learning工作区。 有关创建工作区的说明,请参阅 “创建工作区”。
至少具有以下Azure基于角色的访问控制(Azure RBAC)角色之一的用户帐户:
- Azure Machine Learning工作区的所有者角色
- Azure Machine Learning工作区的参与者角色
- 具有
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* 权限的自定义角色
有关详细信息,请参阅 管理访问 Azure 机器学习工作区。
准备好您的系统
设置环境变量。
可以将默认值配置为与Azure CLI一起使用。 若要避免多次传递订阅、工作区和资源组的值,请运行以下代码:
az account set --subscription <subscription-ID>
az configure --defaults workspace=<Azure-Machine-Learning-workspace-name> group=<resource-group-name>
克隆示例存储库
若要遵循本文,请先克隆 examples 存储库(azureml-examples)。 然后转到存储库的 cli/ 目录:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
cd cli
提示
使用 --depth 1 仅克隆存储库中最新的提交,从而减少完成操作所需的时间。
本教程中的命令位于 deploy-safe-rollout-online-endpoints.sh 目录中的 cli 文件中。 YAML 配置文件位于 endpoints/online/managed/sample/ 子目录中。
注意事项
Kubernetes 联机终结点的 YAML 配置文件位于 endpoints/online/kubernetes/ 子目录中。
克隆示例存储库
若要运行训练示例,请先克隆 examples 存储库(azureml-examples)。 然后转到 azureml-examples/sdk/python/endpoints/online/managed 目录:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
提示
使用 --depth 1 仅克隆存储库中最新的提交,从而减少完成操作所需的时间。
本文基于 online-endpoints-safe-rollout.ipynb 笔记本。 本文包含与笔记本相同的内容,但代码块的顺序在两个文档之间略有不同。
连接到Azure Machine Learning工作区
workspace 是Azure Machine Learning的顶级资源。 工作区提供一个集中位置,用于处理使用Azure Machine Learning时创建的所有项目。 本节中,你将连接到工作区,执行部署任务。 若要继续学习该内容,请打开 online-endpoints-safe-rollout.ipynb 笔记本。
导入所需的库:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration,
)
from azure.identity import DefaultAzureCredential
注意事项
如果使用 Kubernetes 联机终结点,请从 KubernetesOnlineEndpoint 库导入 KubernetesOnlineDeployment 和 azure.ai.ml.entities 类。
配置工作区设置并获取工作区的控制权。
若要连接到工作区,需要标识符参数 - 订阅、资源组和工作区名称。 在 MLClient 模块的 azure.ai.ml 类中使用此信息获取所需 Azure Machine Learning 工作区的句柄。 此示例使用 default Azure 身份验证。
# enter details of your AML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
如果在本地计算机上安装了 Git,则可以按照说明克隆示例存储库。 否则,请按照说明从示例存储库下载文件。
克隆示例存储库
若要遵循本文,请克隆 azureml-examples 存储库。 然后,转到 azureml-examples/cli/endpoints/online/model-1 文件夹。
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
提示
使用 --depth 1 仅克隆存储库中最新的提交,从而减少完成操作所需的时间。
从示例存储库下载文件
可以将存储库下载到本地计算机,而不是克隆示例存储库:
- 转到 https://github.com/Azure/azureml-examples/。
- 选择 <> 代码。 转到 “本地 ”选项卡,然后选择“ 下载 ZIP”。
定义终结点和部署
使用联机终结点进行联机(实时)推理。 在线终结点包含一些部署,它们已准备好随时接收来自客户端的数据,并能够实时发回响应。
定义终结点
下表列出了定义终结点时要指定的关键属性。
| 属性 |
必需还是可选 |
描述 |
| 名称 |
必选 |
终结点的名称。 它在Azure所属区域内必须是唯一的。 有关命名规则的详细信息,请参阅Azure Machine Learning联机终结点和批处理终结点。 |
| 身份验证模式 |
可选 |
终结点的身份验证方法。 在基于密钥的身份验证key、Azure Machine Learning 基于令牌的身份验证aml_token和 Microsoft Entra 基于令牌的身份验证aad_token之间进行选择。 密钥不会过期,但令牌会过期。 有关身份验证的详细信息,请参阅 对联机终结点的客户端进行身份验证。 |
| 描述 |
可选 |
终结点的说明。 |
| 标签 |
可选 |
终结点的标记字典。 |
| 交通 |
可选 |
有关如何跨部署路由流量的规则。 将流量表示为键值对的字典,其中键表示部署名称,值表示该部署的流量百分比。 只有在终结点下创建部署后,才能设置流量。 创建部署后,还可以更新联机终结点的流量。 有关如何使用镜像流量的详细信息,请参阅 将少量实时流量分配给新部署。 |
| 镜像流量 |
可选 |
要镜像到部署的实时流量的百分比。 有关如何使用镜像流量的详细信息,请参阅 使用镜像流量测试部署。 |
若要查看可以在创建终结点时指定的属性的完整列表,请参阅 CLI (v2) 联机终结点 YAML 架构。 有关适用于 Python 的 Azure Machine Learning SDK 版本 2,请参阅 ManagedOnlineEndpoint 类。
定义部署
部署是托管模型并执行实际推理的一组资源。 下表描述了定义部署时要指定的关键属性。
| 属性 |
必需还是可选 |
描述 |
| 名称 |
必选 |
部署的名称。 |
| 终结点名称 |
必选 |
用于创建部署的终结点名称。 |
| 型号 |
可选 |
要用于部署的模型。 此值可以是对工作区中现有版本化模型的引用,也可以是对内联模型规范的引用。 在本文的示例中, scikit-learn 模型确实会回归。 |
| 代码路径 |
可选 |
本地开发环境中文件夹的路径,其中包含用于评分模型的所有Python源代码。 可以使用嵌套目录和包。 |
| 评分脚本 |
可选 |
Python在给定输入请求上执行模型的代码。 此值可以是源代码文件夹中评分文件的相对路径。
评分脚本接收提交到已部署的 Web 服务的数据,并将此数据传递给模型。 然后,该脚本执行模型并将其响应返回给客户端。 评分脚本特定于你的模型,必须理解模型期望作为输入和作为输出返回的数据。
本文的示例使用 score.py 文件。 此Python代码必须具有 init 函数和 run 函数。
init在创建或更新模型后调用该函数。 例如,可以使用它在内存中缓存模型。 每次调用终结点时都会调用 run 函数,执行实际的评分和预测。 |
| 环境 |
必选 |
用于承载模型和代码的环境。 此值可以是对工作区中现有已版本化环境的引用,也可以是嵌入式环境规范。 环境可以是带有 Conda 依赖项的 Docker 映像、一个 Dockerfile 或一个已注册环境。 |
| 实例类型 |
必选 |
要用于部署的虚拟机大小。 有关支持的大小列表,请参阅托管联机终结点 SKU 列表。 |
| 实例计数 |
必选 |
用于部署的实例数。 请根据预期的工作负载确定值。 若要实现高可用性,请使用至少三个实例。 Azure Machine Learning额外保留 20% 来执行升级。 有关详细信息,请参阅 Azure Machine Learning 联机终结点和批处理终结点。 |
若要查看可以在创建部署时指定的属性的完整列表,请参阅 CLI (v2) 托管联机部署 YAML 架构。 有关 Python SDK 版本 2,请参阅 ManagedOnlineDeployment 类。
创建联机终结点
首先,设置终结点名称。 然后,配置终结点。 在本文中,将使用 endpoints/online/managed/sample/endpoint.yml 该文件来配置终结点。 该文件包含以下行:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
下表描述了终结点 YAML 格式使用的密钥。 若要了解如何指定这些属性,请参阅 CLI (v2) 联机终结点 YAML 架构。 有关与托管联机终结点相关的限制的信息,请参阅 Azure Machine Learning 联机终结点和批处理终结点。
| 密钥 |
描述 |
$schema |
(可选)YAML 架构。 若要查看 YAML 文件中的所有可用选项,可以在浏览器中查看上述代码块中的架构。 |
name |
终结点的名称。 |
auth_mode |
身份验证模式。 使用 key 可执行基于密钥的身份验证。 使用 aml_token 进行基于令牌的Azure Machine Learning身份验证。 使用 aad_token 进行基于令牌的Microsoft Entra身份验证。 若要获取最新的令牌,请使用 az ml online-endpoint get-credentials 命令。 |
若要创建联机终结点,请执行以下操作:
通过运行以下 Unix 命令设置终结点名称。 将 YOUR_ENDPOINT_NAME 替换为唯一名称。
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
重要
终结点名称在Azure区域中必须唯一。 例如,在 Azure chinanorth2 区域中,只能有一个名称为 my-endpoint的终结点。
通过运行以下代码在云中创建终结点。 此代码使用 endpoint.yml 文件配置终结点:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
创建 blue 部署
可以使用 endpoints/online/managed/sample/blue-deployment.yml 文件来配置名为 blue 的部署的关键方面。 该文件包含以下行:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
若要为终结点创建 blue 部署,请使用该 blue-deployment.yml 文件,然后运行以下命令:
az ml online-deployment create --name blue --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml --all-traffic
重要
在 --all-traffic 命令中,az ml online-deployment create 标志将 100% 的端点流量分配给新创建的 blue 部署。
blue-deployment.yaml在文件中,行path指定从何处上传文件。 Azure Machine Learning CLI 使用此信息上传文件并注册模型和环境。 作为生产最佳做法,请注册模型和环境,并在 YAML 代码中单独指定已注册的名称和版本。 使用模型的格式 model: azureml:<model-name>:<model-version> ,例如 model: azureml:my-model:1。 对于环境,请使用格式 environment: azureml:<environment-name>:<environment-version>,例如 environment: azureml:my-env:1。
若要执行注册,可以将 model 和 environment 的 YAML 定义提取到单独的 YAML 文件中,并使用命令 az ml model create 和 az ml environment create。 若要了解有关这些命令的详细信息,请运行 az ml model create -h 和 az ml environment create -h。
有关将模型注册为资产的详细信息,请参阅使用 Azure CLI 或 Python SDK 注册模型。 有关创建环境的详细信息,请参阅 “创建自定义环境”。
创建联机终结点
使用 ManagedOnlineEndpoint 类创建管理的在线终结点。 此编程类可帮助你配置终结点的关键要素。
配置终结点:
# Creating a unique endpoint name with current datetime to avoid conflicts
import datetime
online_endpoint_name = "endpoint-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is a sample online endpoint",
auth_mode="key",
tags={"foo": "bar"},
)
注意事项
若要创建 Kubernetes 联机终结点,请使用 KubernetesOnlineEndpoint 类。
创建终结点:
ml_client.begin_create_or_update(endpoint).result()
创建 blue 部署
若要为托管联机终结点创建部署,请使用 ManagedOnlineDeployment 类。 此类提供了一种方法来配置部署的关键方面。
配置 blue 部署:
# create blue deployment
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS2_v2",
instance_count=1,
)
在此示例中,参数 path 指定要从何处上传文件。 Python SDK 使用此信息上传文件并注册模型和环境。 作为生产最佳做法,请注册模型和环境,并在代码中单独指定已注册的名称和版本。
有关将模型注册为资产的详细信息,请参阅使用 Azure CLI 或 Python SDK 注册模型。
有关创建环境的详细信息,请参阅 “创建自定义环境”。
注意事项
若要为 Kubernetes 联机终结点创建部署,请使用 KubernetesOnlineDeployment 类。
创建部署:
ml_client.begin_create_or_update(blue_deployment).result()
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.begin_create_or_update(endpoint).result()
在 Azure Machine Learning studio 中创建托管联机终结点时,必须为终结点定义初始部署。 在定义部署之前,请在工作区中注册模型。 以下部分演示如何注册用于部署的模型。
注册模型
模型注册是工作区中的一个逻辑实体。 此实体可以包含单个模型文件或具有多个文件的目录。 作为生产最佳做法,请注册模型和环境。
若要注册示例模型,请按照以下部分中的步骤作。
上传模型文件
转到 Azure Machine Learning studio。
选择 模型。
选择“注册”,然后选择“来自本地文件”。
在 “模型类型”下,选择 “未指定类型”。
选择 “浏览”,然后选择“ 浏览”文件夹。

转到之前克隆或下载的存储库的本地副本,然后选择 \azureml-examples\cli\endpoints\online\model-1\model。 出现提示时,选择“ 上传 ”并等待上传完成。
选择“下一步”。
在 “模型设置” 页上的“ 名称”下,输入模型的友好名称。 本文中的步骤假定模型已命名为 model-1。
选择“ 下一步”,然后选择“ 注册 ”以完成注册。
对于本文后面的示例,还需要从存储库的本地副本中的 \azureml-examples\cli\endpoints\online\model-2\model 文件夹中注册模型。 若要注册该模型,请重复前两节中的步骤,但将该模型命名为该模型 model-2。
有关使用已注册模型的详细信息,请参阅 使用 Azure Machine Learning 中注册的模型。
有关在工作室中创建环境的信息,请参阅 “创建环境”。
创建托管联机终结点和 blue 部署
可以使用Azure Machine Learning studio直接在浏览器中创建托管联机终结点。 在工作室中创建托管的在线端点时,必须定义一个初始部署。 不能创建空的托管的在线端点。
在平台中创建托管在线端点的一种方法是从“模型”页面创建。 此方法也提供将模型添加到现有托管联机部署的简单方法。 若要部署之前在“model-1”部分中注册的模型,请执行以下步骤。
选择模型
转到 Azure Machine Learning studio,然后选择 Models。
在列表中,选择 model-1 模型。
选择部署>实时终结点。

此时会打开一个窗口,可用于指定有关终结点的详细信息。

在 “终结点名称”下,输入终结点的名称。
在 “计算类型”下,保留 “托管”的默认值。
在 “身份验证类型”下,保留 基于密钥的身份验证的默认值。
选择 “下一步”,然后在“ 模型 ”页上,选择“ 下一步”。
配置剩余设置并创建部署
在 “部署 ”页上,执行以下步骤:
- 在 “部署名称”下,输入 蓝色。
- 如果以后想要在工作室中查看终结点活动的图表:
- 在 推理数据收集下,打开开关。
- 在 Application Insights 诊断下,打开开关。
- 选择“下一步”。
在 用于推理的代码和环境 页上,执行以下步骤:
- 在 “选择用于推理的评分脚本”下,选择“ 浏览”,然后从之前克隆或下载的存储库中选择 \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py 文件。
- 在环境列表上方的搜索框中,开始输入 sklearn,然后选择 sklearn-1.5:19 特选环境。
- 选择“下一步”。
在 “计算 ”页上,执行以下步骤:
- 在 “虚拟机”下,保留默认值。
- 在 “实例计数”下,将默认值替换为 1。
- 选择“下一步”。
在实时流量页面上,选择下一步以接受100%到blue部署的默认流量分配。
在 “查看”时,查看部署设置,然后选择“ 创建”。

从“终结点”页创建终结点
或者,也可以通过平台中的“终结点”页面创建托管在线终结点。
转到 Azure Machine Learning studio。
选择 终结点。
选择 创建。

此时会打开一个窗口,可在其中指定有关终结点和部署的详细信息。
选择模型,然后选择 “选择”。
请根据前面两个部分中的描述,输入终结点和部署的设置。 在每个步骤中,使用默认值。 在最后一步中,选择“ 创建” 以创建部署。
确认现有部署
确认现有部署的一种方法是调用终结点,以便它可以就给定输入请求为你的模型评分。 通过 Azure CLI 或 Python SDK 调用终结点时,可以选择指定要接收传入流量的部署的名称。
注意事项
与Azure CLI或Python SDK 不同,Azure Machine Learning studio要求在调用终结点时指定部署。
使用部署名称调用终结点
调用终结点时,可以指定要接收流量的部署的名称。 在这种情况下,Azure Machine Learning将终结点流量直接路由到指定的部署并返回其输出。 可以使用 --deployment-name 选项 Azure Machine Learning CLI v2或 deployment_name 选项 Python SDK v2指定部署。
在不指定部署的情况下调用终结点
如果调用终结点时未指定要接收流量的部署,Azure Machine Learning 会根据流量控制设置将终结点的传入流量路由到终结点中的各个部署。
流量控制设置会将指定百分比的传入流量分配给终结点中的各个部署。 例如,若流量规则指定终结点中的某特定部署应在 40% 的时间里接收传入流量,Azure Machine Learning 将 40% 的终结点流量路由到该部署。
若要查看现有终结点和部署的状态,请运行以下命令:
az ml online-endpoint show --name $ENDPOINT_NAME
az ml online-deployment show --name blue --endpoint $ENDPOINT_NAME
输出列出了有关 $ENDPOINT_NAME 终结点和 blue 部署的信息。
使用示例数据测试终结点
可以使用命令调用终结点 invoke 。 以下命令使用 sample-request.json JSON 文件发送示例请求:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
使用以下代码检查模型部署的状态:
ml_client.online_endpoints.get(name=online_endpoint_name)
使用示例数据测试终结点
您可以使用之前创建的 MLClient 实例来获取终结点的句柄。 若要调用终结点,请使用 invoke 具有以下参数的命令:
-
endpoint_name:终结点的名称。
-
request_file:包含请求数据的文件。
-
deployment_name:要在终结点中测试的部署的名称。
以下代码使用 sample-request.json JSON 文件发送示例请求。
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
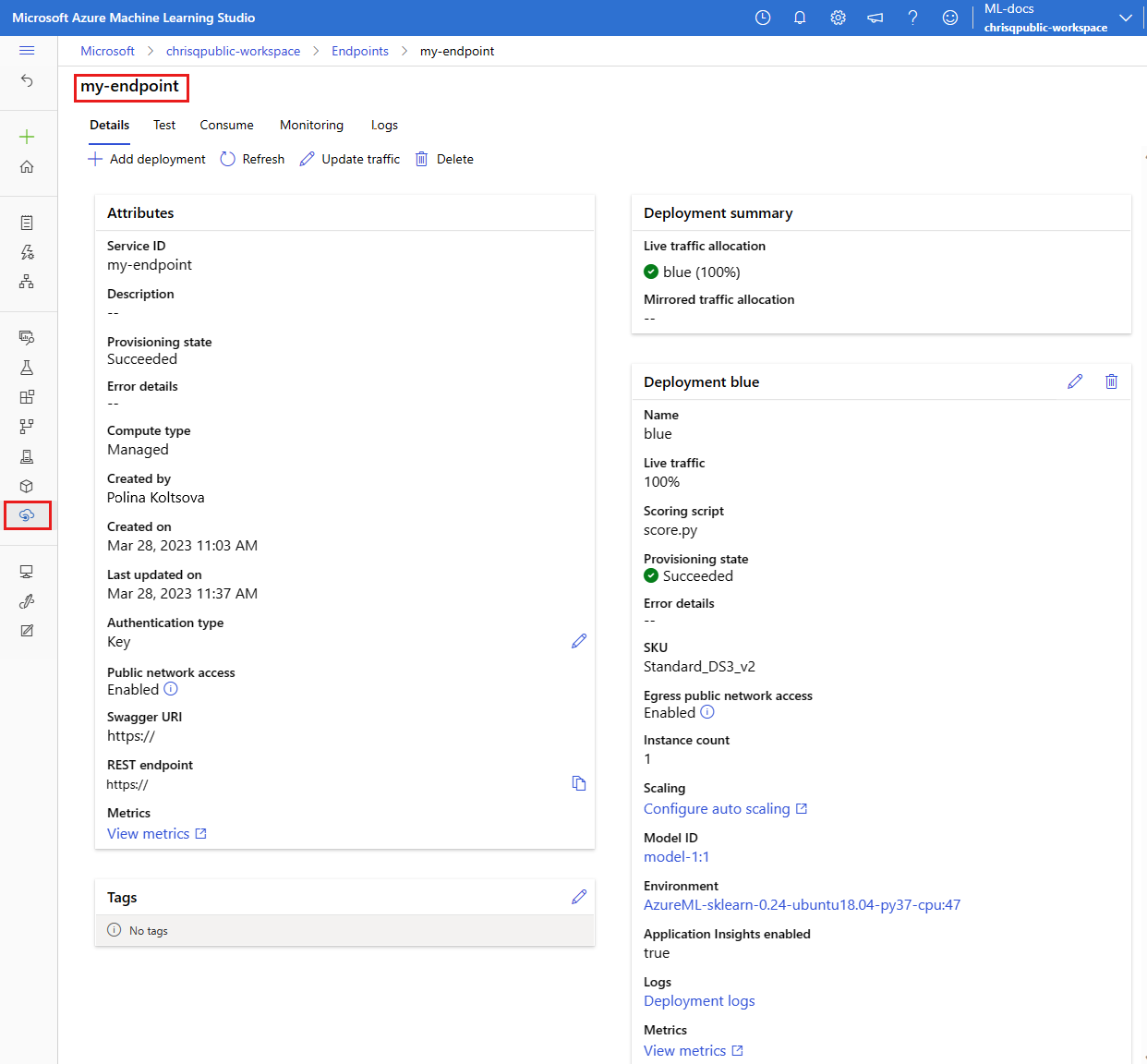
查看托管在线终结点
可以在“工作室终结点”页中查看所有托管联机终结点。 每个终结点页面的“ 详细信息 ”选项卡显示关键信息,例如终结点 URI、状态、测试工具、活动监视器、部署日志和示例使用代码。 若要查看此信息,请执行以下步骤:
在工作室中,选择“终结点”。 将显示工作区中所有终结点的列表。
(可选)在计算实例类型上创建筛选器,以仅显示托管类型。
选择一个终结点名称以查看该终结点的“详细信息”页。
使用示例数据测试终结点
在终结点页上,使用“ 测试 ”选项卡测试托管联机部署。 若要输入示例输入并查看结果,请执行以下步骤:
在终结点页上,转到“ 测试 ”选项卡。在 “部署 ”列表中, blue 已选择部署。
转到 sample-request.json 文件并复制其示例输入。
在工作室中,将示例输入粘贴到 “输入 ”框中。
选择测试。

扩展现有部署以处理更多流量
在通过在线终结点部署和评分机器学习模型的部署中,将部署 YAML 文件中的instance_count 值设置为1。 使用 update 命令进行Scale out(扩展):
az ml online-deployment update --name blue --endpoint-name $ENDPOINT_NAME --set instance_count=2
注意事项
在上一个命令中, --set 该选项将替代部署配置。 你也可以更新 YAML 文件,并使用 update 选项将它作为输入传递给 --file 命令。
MLClient使用之前创建的实例获取部署的句柄。 若要调整部署的规模,请增加或减小 instance_count 的值。
# scale the deployment
blue_deployment = ml_client.online_deployments.get(
name="blue", endpoint_name=online_endpoint_name
)
blue_deployment.instance_count = 2
ml_client.online_deployments.begin_create_or_update(blue_deployment).result()
# Get the details for online endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
若要通过调整实例数来纵向扩展或缩减部署,请执行以下步骤:
在终结点页上,转到“ 详细信息 ”选项卡,找到部署卡 blue 。
在部署卡的 blue 标头上,选择编辑图标。
在 “实例计数”下,输入 2。
选择“更新”。

部署新模型,但不向其发送流量
创建名为 green 的新部署:
az ml online-deployment create --name green --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/green-deployment.yml
因为没有显式地为 green 部署分配任何流量,所以它没有分配任何流量。 可以使用以下命令验证事实:
az ml online-endpoint show -n $ENDPOINT_NAME --query traffic
测试新部署
虽然 green 部署分配了 0% 的流量,但可以使用 --deployment 选项直接调用:
az ml online-endpoint invoke --name $ENDPOINT_NAME --deployment-name green --request-file endpoints/online/model-2/sample-request.json
如果要使用 REST 客户端直接调用部署而不经历流量规则处理过程,请设置以下 HTTP 头:azureml-model-deployment: <deployment-name>。 以下代码使用客户端进行 URL (cURL) 直接调用部署。 可以在 Unix 或 Windows Subsystem for Linux (WSL) 环境中运行代码。 有关检索 $ENDPOINT_KEY 值的说明,请参阅 获取数据平面密钥或令牌。
# get the scoring uri
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
# use curl to invoke the endpoint
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --header "azureml-model-deployment: green" --data @endpoints/online/model-2/sample-request.json
为托管在线终结点创建新的部署,并将其命名为 green:
# create green deployment
model2 = Model(path="../model-2/model/sklearn_regression_model.pkl")
env2 = Environment(
conda_file="../model-2/environment/conda.yml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
)
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model2,
environment=env2,
code_configuration=CodeConfiguration(
code="../model-2/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS2_v2",
instance_count=1,
)
# use MLClient to create green deployment
ml_client.begin_create_or_update(green_deployment).result()
测试新部署
尽管 green 部署分配了 0% 的流量,但仍可以调用终结点和部署。 以下代码使用 sample-request.json JSON 文件发送示例请求。
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="green",
request_file="../model-2/sample-request.json",
)
可以创建要添加到托管联机终结点的新部署。 若要创建名为 green的部署,请按照以下部分中的步骤作。
在终结点页上,转到“ 详细信息 ”选项卡,然后选择“ 添加部署”。
在 “选择模型 ”页上,选择 model-2,然后选择“ 选择”。
在 “终结点 ”页和“ 模型 ”页上,选择“ 下一步”。
在 “部署 ”页上,执行以下步骤:
- 在 “部署名称”下,输入 绿色。
- 在 推理数据收集下,打开开关。
- 在 Application Insights 诊断下,打开开关。
- 选择“下一步”。
在 用于推理的代码和环境 页上,执行以下步骤:
- 在 “选择用于推理的评分脚本”下,选择“ 浏览”,然后从之前克隆或下载的存储库中选择 \azureml-examples\cli\endpoints\online\model-2\onlinescoring\score.py 文件。
- 在环境列表上方的搜索框中,开始输入 sklearn,然后选择 sklearn-1.5:19 特选环境。
- 选择“下一步”。
在 “计算 ”页上,执行以下步骤:
- 在 “虚拟机”下,保留默认值。
- 在 “实例计数”下,将默认值替换为 1。
- 选择“下一步”。
配置剩余设置并创建部署
在 实时流量中,选择 “下一步” 以接受 100% 到 blue 部署的默认流量分配,0% 到 green。
在 “查看”时,查看部署设置,然后选择“ 创建”。

从“模型”页面添加部署
或者,您可以使用“模型”页面来添加部署:
在工作室中,选择 “模型”。
在列表中选择一个模型。
选择部署>实时终结点。
在“终结点”下,选择“现有”。
在终结点列表中,选择要将模型部署到的托管联机终结点,然后选择“ 下一步”。

在 “模型 ”页上,选择“ 下一步”。
若要完成部署创建 green ,请遵循 “配置初始设置 ”部分中的步骤 4 到 6,以及 “配置剩余设置”中的所有步骤并创建部署 部分。
注意事项
向终结点添加新部署时,可以使用 “更新流量分配 ”页来调整部署之间的流量平衡。 若要遵循本文的其余过程,请暂时将默认流量分配 100% 保留到 blue 部署,并将 0% 保留到 green 部署。
测试新部署
即使 0% 的流量流向 green 部署,仍然可以调用终结点和该部署。 在终结点页上,使用“ 测试 ”选项卡测试托管联机部署。 若要输入示例输入并查看结果,请执行以下步骤:
在终结点页上,转到“ 测试 ”选项卡。
在 “部署 ”列表中,选择 绿色。
转到 sample-request.json 文件并复制其示例输入。
在工作室中,将示例输入粘贴到 “输入 ”框中。
选择测试。
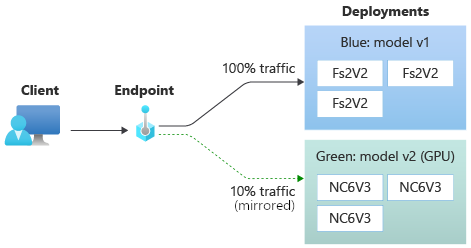
使用镜像流量测试部署
测试 green 部署后,可以将一定百分比的实时流量复制并发送到 green 部署上,以将其镜像到终结点。 流量镜像(也称为 阴影)不会更改返回给客户端的结果。 所有请求仍会流向 blue 部署。 流量的镜像百分比将被复制并提交到 green 部署,以便可以收集指标和日志记录,而不会影响客户端。
如果要验证新部署而不影响客户端,则可使用镜像。 例如,可以使用镜像来检查延迟是否在可接受的范围内,或者检查是否存在 HTTP 错误。 使用流量镜像(又称影子)来测试新部署也称为影子测试。 在这种情况下,接收镜像流量的 green 部署也可以称为 影子部署。
镜像具有以下限制:
- Azure Machine Learning CLI 2.4.0 及更高版本以及 Python SDK 版本 1.0.0 及更高版本支持镜像。 如果使用旧版的 Azure Machine Learning CLI 或 Python SDK 更新终结点,则会丢失镜像流量设置。
- Kubernetes 联机终结点目前不支持镜像。
- 只能将流量镜像到终结点中的一个部署。
- 可以镜像的最大流量百分比为 50%。 此上限限制对 endpoint 带宽配额的影响,默认值为 5 MBps。 如果超出分配的配额,则终结点带宽会受到限制。 有关监视带宽限制的信息,请参阅 带宽限制。
另请注意以下行为:
- 可以将部署配置为仅接收实时流量或镜像流量,而不是同时接收这两者。
- 调用终结点时,可以指定其任何部署的名称(甚至影子部署)以返回预测。
- 调用终结点并指定要接收传入流量的部署的名称时,Azure Machine Learning不会将流量镜像到影子部署。 当未指定部署时,Azure 机器学习将发送到终结点的流量复制到影子部署。
即使将 green 部署设置为接收 10% 的镜像流量,客户端依然仅接收来自 blue 部署的预测。
使用以下命令镜像 10% 的流量并将其发送到 green 部署:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=10"
若要测试镜像流量,请多次调用终结点,而无需指定部署。 终结点路由传入流量:
for i in {1..20} ; do
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
done
您可以通过检查部署中的日志来确认将指定百分比的流量发送到 green 部署。
az ml online-deployment get-logs --name green --endpoint $ENDPOINT_NAME
测试后,将镜像流量设置为零以禁用镜像:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=0"
使用以下代码复制 10% 的流量并将其发送到 green 部署:
endpoint.mirror_traffic = {"green": 10}
ml_client.begin_create_or_update(endpoint).result()
可以通过多次调用终结点来测试镜像流量,而无需指定用于接收传入流量的部署:
# You can test mirror traffic by invoking the endpoint several times
for i in range(20):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="../model-1/sample-request.json",
)
您可以通过检查部署中的日志来确认将指定百分比的流量发送到 green 部署。
ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
测试后,将镜像流量设置为零以禁用镜像:
ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
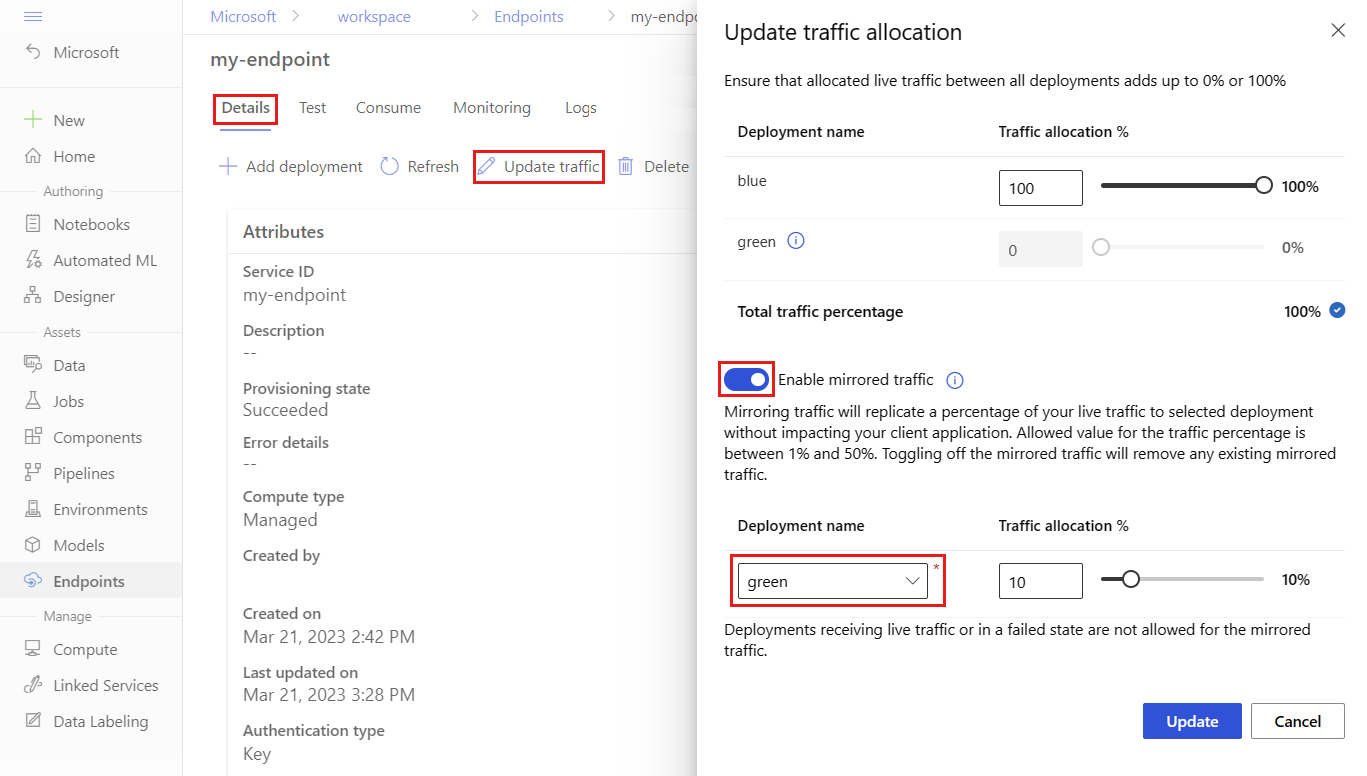
若要镜像 10% 流量并将其发送到 green 部署,请执行以下步骤:
在终结点页上,转到“ 详细信息 ”选项卡,然后选择“ 更新流量”。
打开“启用镜像流量”的开关。
在 “部署名称 ”列表中,选择 绿色。
在 流量分配 %下,保留默认值 10%。
选择“更新”。
终结点详细信息页现在显示一个到 green 部署的 10% 镜像流量分配。
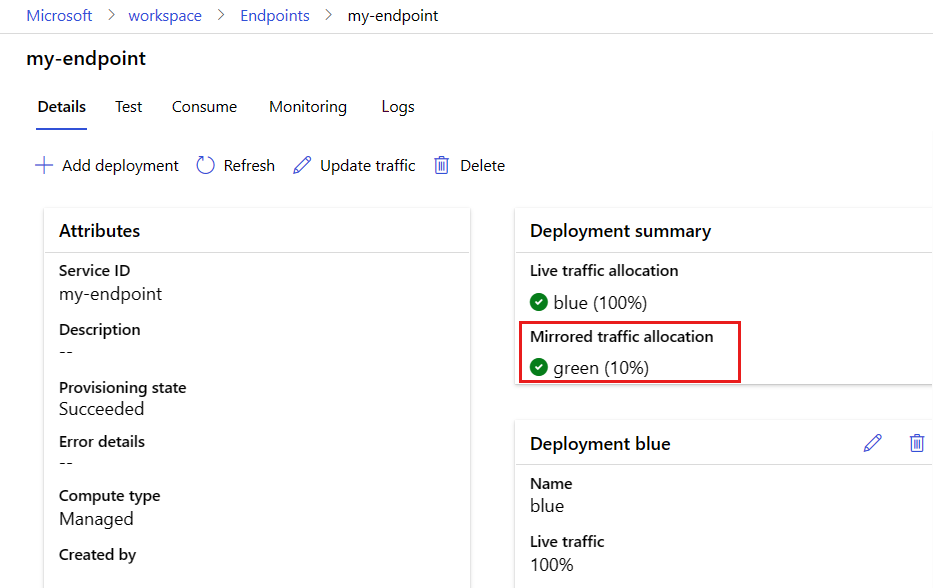
若要测试镜像流量,请参见Azure CLI或Python标签,并多次调用终结点。 通过查看部署的日志,来确认将多少特定比例的流量发送到了 green 部署。 可以在终结点页面的Logs选项卡中访问部署日志。
还可以使用指标和日志来监视镜像流量的性能。 有关更多信息,请参阅在线端点监控。
测试后,可以通过执行以下步骤来禁用镜像:
在终结点页上,转到“ 详细信息 ”选项卡,然后选择“ 更新流量”。
关闭“启用镜像流量”的开关。
选择“更新”。
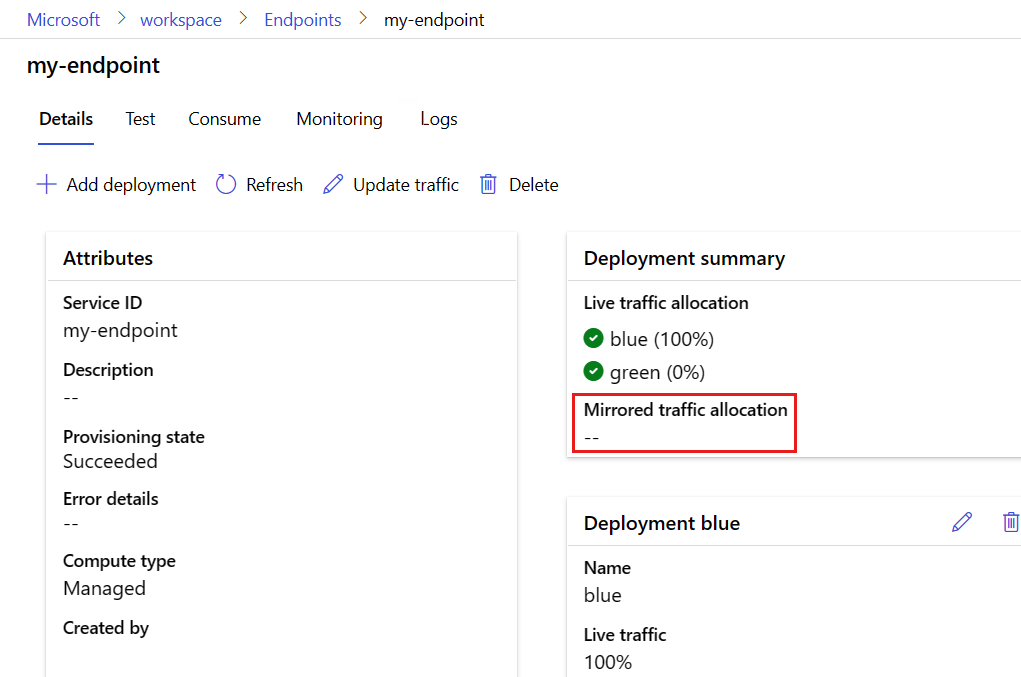
将一小部分实时流量分配给新部署
测试 green 部署后,为其分配一小部分流量:
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=90 green=10"
测试完您的 green 部署后,请为其分配一定比例的流量。
endpoint.traffic = {"blue": 90, "green": 10}
ml_client.begin_create_or_update(endpoint).result()
在终结点页上,转到“ 详细信息 ”选项卡,然后选择“ 更新流量”。
通过将部署流量的 10% 分配给 green 部署,并将 90% 分配到 blue 部署来进行调整。
选择“更新”。
提示
总流量百分比必须是 0% 才能禁用流量,或 100% 才能启用流量。
部署 green 现在接收 10% 的实时总流量。 客户端从 blue 和 green 部署接收预测。
将所有流量发送到新部署
对 green 部署完全满意后,将所有流量切换至该部署。
对 green 部署完全满意后,将所有流量切换到该部署。
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=0 green=100"
对 green 部署完全满意后,将所有流量切换到该部署。
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
在终结点页上,转到“ 详细信息 ”选项卡,然后选择“ 更新流量”。
通过将 100% 的流量分配给 green 部署,以及将 0% 的流量分配给 blue 部署来调整部署流量。
选择“更新”。
删除旧部署
使用以下步骤从托管在线端点中删除某个特定部署。 删除单个部署不会影响托管联机终结点中的其他部署:
az ml online-deployment delete --name blue --endpoint $ENDPOINT_NAME --yes --no-wait
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
注意事项
无法删除已分配了实时流量的部署。 在删除部署之前,请将部署的 流量分配设置为 0%。
在终结点页上,转到“ 详细信息 ”选项卡,然后转到 blue 部署卡。
在部署名称旁边,选择删除图标。
删除终结点和部署
如果不打算使用终结点和部署,请删除它们。 删除终结点时,还会删除其所有基础部署。
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
相关内容












