计分配置文件用于根据用户定义的条件提升或降低匹配文档的排名。 本文介绍如何指定和分配计分概要文件,以便根据提供的参数提升搜索分数。 可以根据以下内容创建计分概要文件:
加权字符串字段,其中提升基于指定字段中找到的匹配项。 例如,在“主题”字段中找到的匹配项被认为比“说明”字段中找到的匹配项更相关。
数值字段的函数,包括日期和地理坐标。 数值内容函数支持提升距离(适用于地理坐标)、新鲜度(适用于日期时间字段)、范围和数量级。
字符串集合的函数(标签)。 如果集合中的任何项都与查询匹配,标记函数将提升文档的搜索分数。
(预览版) 不同提升的聚合。 在单个计分配置文件中,可以指定多个评分函数,然后设置
"functionAggregation": "product"。 对所有函数进行高度评分的文档处于优先顺序,同时取消在一个或多个字段中评分较弱的文档。
可以通过在 Azure 门户中编辑其 JSON 定义或通过任何 Azure SDK 中的 创建或更新索引 REST 或等效索引更新 API 等 API 以编程方式将计分配置文件添加到索引。 没有索引重新生成要求,因此可以添加、修改或删除评分配置文件,而不会影响索引文档。
在本文结束时,您将能够创建和应用评分配置文件,以基于字段权重、新鲜度、距离或自定义条件提升搜索相关性。
先决条件
一份 Azure 订阅。
包含文本或数字(非函数)字段的搜索索引。
权限:需要 搜索索引数据参与者 来创建或更新包含计分配置文件的索引。 若要使用计分配置文件进行查询,需要 搜索索引数据读取器。 有关详细信息,请参阅使用角色进行连接。
SDK 安装(可选):
- Python:
pip install azure-search-documents - C#:
dotnet add package Azure.Search.Documents
- Python:
小窍门
对于即时代码示例,请跳到 评分配置文件定义。
计分概要文件的规则
可以在关键字搜索、矢量搜索、混合搜索和语义重排序中使用计分配置文件。 但是,计分配置文件仅适用于非函数字段,因此请确保索引具有可以提升或加权的文本或数值字段。
索引中最多可以有 100 个计分配置文件(请参阅 服务限制),但在任何给定查询中一次只能指定一个配置文件。
您可以将 语义排名 与计分配置文件结合使用,并在 语义排名发生后应用计分配置文件。 否则,当多个排名或相关性功能发挥作用时,语义排名是最后一步。 搜索评分的工作原理 提供了操作顺序的插图。
额外的规则 特别适用于函数。
评分模型定义
评分配置文件在索引架构中定义。 它由加权字段、函数和参数组成。
以下定义展示了一个名为“geo”的简单配置文件。 此示例用于提升在"hotelName"字段中包含搜索词的搜索结果。 它还使用 distance 函数优先考虑在当前位置 10 公里范围内的结果。 如果有人搜索“inn”,而“inn”一词恰好是某个酒店名称的一部分,那么在当前位置 10 公里半径范围内包含这些酒店的相关文档会在搜索结果中排名更高。
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
参考: scoringProfiles | scoringFunction | 距离函数
若要使用此计分概要文件,查询要表述为指定请求中的 scoringProfile 参数。 如果使用 REST API,则通过 GET 和 POST 请求指定查询。 在以下示例中,“currentLocation”具有一个短横线 (-) 作为分隔符。 它后面跟着经度和纬度坐标,其中经度为负值。
POST /indexes/hotels/docs/search?api-version=2026-04-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
参考: 搜索文档 (REST) | scoringProfile 参数 | scoringParameters
scoringParameters中介绍了查询参数(包括)。
有关更多方案,请参阅本文中 有关新鲜度、距离 和 加权文本和函数 的示例。
使用 SDK 和计分配置文件进行查询
import os
from azure.identity import DefaultAzureCredential
from azure.search.documents import SearchClient
# Set up the client
endpoint = os.environ["AZURE_SEARCH_ENDPOINT"]
index_name = "hotels"
credential = DefaultAzureCredential()
client = SearchClient(endpoint=endpoint, index_name=index_name, credential=credential)
# Execute search with scoring profile
results = client.search(
search_text="inn",
scoring_profile="geo",
scoring_parameters=["currentLocation--122.123,44.77233"],
select=["HotelName", "Description", "Rating"]
)
for result in results:
print(f"{result['HotelName']} (Score: {result['@search.score']})")
将评分概要文件添加到搜索索引
从索引定义开始。 可以在现有索引上添加和更新计分概要文件,而无需重新生成它。 使用 “获取索引 ”拉取现有索引,并使用 “创建”或“更新索引” 请求发布修订。
粘贴到本文中提供的模板中。
提供符合 命名约定的名称。
应使用有助于证明或反驳给定配置文件有效性的数据集来迭代工作。
可以在 Azure 门户中定义计分配置文件,如以下屏幕截图所示,也可以通过 REST API 或 Azure SDK 以编程方式定义,例如 .NET 或 Python 客户端库中的 ScoringProfile 类。

模板
本部分演示计分概要文件的语法和模板。 有关属性的描述,请参阅 REST API 参考。
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
使用文本加权字段
当字段上下文很重要且查询包含 searchable 字符串字段时,使用文本加权字段。 例如,如果查询包含“airport”一词,则您可能喜欢 HotelName 字段中的“airport”,而不是“说明”字段。
加权字段是由一个 searchable 字段和一个用作乘数的正数组成的名称-值对。 如果 HotelName 的原始字段分数为 3,该字段的提升分数将变为 6,从而提升父文档本身的总体分数。
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
使用函数
当简单的相对权重不足或不适用时,请使用函数,例如距离和新鲜度的情况(即对数值数据的计算)。 可以为每个评分配置文件指定多个函数。 有关 Azure AI 搜索中使用的 EDM 数据类型的详细信息,请参阅支持的数据类型。
| 函数 | 说明 | 用例 |
|---|---|---|
| 距离 | 按距离或地理位置提升。 此函数仅可与 Edm.GeographyPoint 字段结合使用。 |
用于“查找我附近的地点”场景。 |
| 新鲜 | 按照日期/时间字段 (Edm.DateTimeOffset) 中的值进行提升。
设置 boostingDuration 来指定表示发生提升的时间跨度的值。 |
在您想要强调近期(较新)日期时使用。 您还可以将日期更接近当前的日历事件等项目提升优先级,而不是那些日期更远的项目。 范围的一端固定为当前时间。 |
| 量级 | 数量级是文档值(如日期或位置)与引用点(如“now”或目标位置)之间的计算距离。 它是评分函数的输入,并确定应用的提升量。 根据数字字段的值范围改变排名。 该值必须是整数或浮点数。 对于星级评分 1 到 4,这里应为 1。 对于超过 50% 的利润率,这里应为 50。 此函数仅可与 Edm.Double 和 Edm.Int 字段结合使用。 对于 magnitude 函数,如果想要反转模式(例如,更偏向提升价格较低的商品而不是价格较高的商品),可以将范围从高到低进行反转。 假设价格范围从 100 美元到 1 美元,可以将 boostingRangeStart 设为 100、boostingRangeEnd 设为 1 以提升价格较低的项。 |
当想要提高利润率、评级、单击次数、下载次数、最高价格、最低价格或下载次数时使用。 当两个项目相关时,将首先显示具有较高分级的项目。 |
| 标签 | 通过搜索文档和查询字符串中共有的标签来增强。
tagsParameter 中提供了标记。 此函数仅可与类型为 Edm.String 和 Collection(Edm.String) 的搜索字段结合使用。 |
当有标签字段时使用。 如果列表中的给定标记本身是逗号分隔的列表,则可在查询时在字段上使用文本规范化器来去除逗号(将逗号字符映射到空格)。 此方法将列表展开,以使所有项成为一个以逗号分隔的长字符串。 |
新鲜度和距离评分是基于幅度评分的特殊情况,其中数量级是通过日期时间或地理字段自动计算的。
使用函数的规则
- 函数只能应用于被归为
filterable的字段。 - 函数类型(“freshness”、“magnitude”、“distance”、“tag”)必须为小写。
- 函数不能包含 null 值或空值。
- 函数的每个定义中只能包含一个字段。 若要在同一个配置文件中两次使用度量值,请为每个字段提供两个定义的度量值。
设置插值
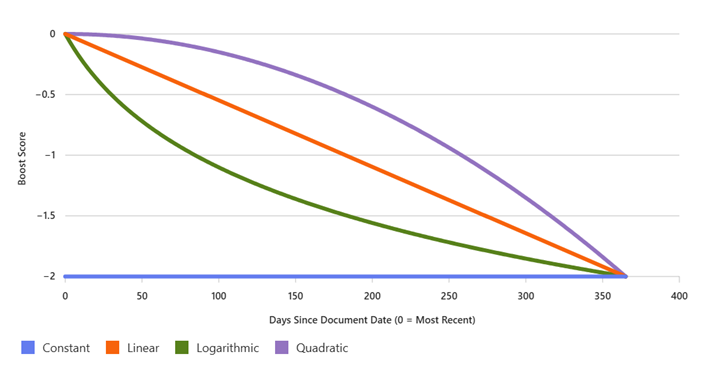
插值设定了用于提升新鲜度和距离的斜率形状。 由于评分从高到低,因此斜率总是减小,但插值决定了下降斜率的曲线形态,以及随着文档日期变老,提升分数变化的激烈程度。
| 插值 | 说明 |
|---|---|
linear |
对于在最大和最小范围内的项,将以持续递减的量进行提升。 建议在需要相关性逐渐减弱时使用。 线性是评分配置文件的默认插值方式。 |
constant |
对于在起始和结束范围内的项目,将对排名结果应用固定加权。 当你想要一个无论年龄的固定罚则时,使用该策略。 |
quadratic |
二次函数最初以较小的速度下降,然后在接近结束范围时加速,并在此时以更大的幅度下降。 如果需要特别偏向最新文档并大幅降低较旧文档的优先级,请使用此内插。 标记评分函数中不允许使用此内插选项。 |
logarithmic |
对数函数最初以较快的速度下降,而当接近末端时,下降的速度则显著减缓。 建议在您对最新内容有很强偏好的情况下使用,但对文档随着时间推移而老化的敏感度较低。 标记评分函数中不允许使用此内插选项。 |
设置 fresh 函数的 boost 持续时间
boostingDuration 是 freshness 函数的属性。 使用它来设置一个过期时间段,之后特定文档的提升将停止。 例如,要在 10 天促销期内提升某个产品系列或品牌,应针对这些文档将 10 天期限指定为 "P10D"。
boostingDuration 必须格式化为 XSD “dayTimeDuration” 值(ISO 8601 持续时间值的受限子集)。 它的模式为:“P[nD][T[nH][nM][nS]]”。
下表提供几个示例。
| 持续时间 | 提升时长 |
|---|---|
| 1 天 | “P1D” |
| 2 天 12 小时 | “P2DT12H” |
| 15 分钟 | “PT15M” |
| 30 天 5 小时 10 分钟 6.334 秒 | “P30DT5H10M6.334S” |
| 1 年 | “365D” |
有关更多示例,请参阅 XML 架构:数据类型(W3.org 网站)。
示例:通过新鲜度或距离提升
助推曲线的形状(常数型、线性型、对数型、二次型)会影响得分在整个分布范围内的变化速率。
使用新鲜度函数时,如果希望提升效果在最近的日期上产生更显著的影响,请选择二次内插。 在二次方方法中,近最近日期和更近位置的影响被增强,而在范围的远端会更慢地逐渐减弱。 相比之下,对数曲线在远端更急剧地移动。
下面是一个示例评分配置文件,展示如何通过提升新鲜度来增强效果。
{
"name": "docs-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "filterable": true },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "content", "type": "Edm.String", "searchable": true },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset", "filterable": true, "sortable": true }
],
"scoringProfiles": [
{
"name": "freshnessBoost",
"text": {
"weights": {
"content": 1.0
}
},
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 2.0,
"interpolation": "quadratic",
"parameters": {
"boostingDuration": "365D"
}
}
]
}
]
}
- 该
freshness函数计算从“现在”到lastUpdated的幅度。 - 使用二次插值法进行的正向提升,提高了最近日期的升力,并对较旧日期的效果快速减弱。
-
"boostingDuration": "365D"定义评估新鲜度的时间范围,例如提升去年内日期的文档。 -
"interpolation": "quadratic"这意味着,对于离当前日期更近的文档来说,提升效果更强,对于较旧的文档来说,效果会更加快速地减弱。
在下一个示例中,线性内插为 30 天时段内的最新内容提供了稳定的首选项。 如果信号需要战胜其他相关性因素,则提高增益。
{
"name": "freshness30_linear",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 3.0,
"interpolation": "linear",
"parameters": { "boostingDuration": "P30D" }
}
]
}
示例:通过加权文本和函数增强
下面的示例演示具有两个评分配置文件(boostGenre、newAndHighlyRated)的索引结构。 任何针对此索引的查询,如果将任一配置文件作为查询参数,则会使用该配置文件来对结果集进行评分。
boostGenre 配置文件使用加权文本字段,以增强在“albumTitle”、“genre”和“artistName”字段中找到的匹配项。 这些字段分别提升了 1.5、5 和 2。 为何“类别”被提升得比其他类别高得多? 如果对有点同质的数据进行搜索(与 musicstoreindex 中的“流派”一样),则可能需要相对权重的较大方差。 例如,在 musicstoreindex 中,“rock”既作为一种流派出现,又在描述流派时使用相同的表达方式。 如果希望流派超过流派描述,流派字段需要更高的相对权重。
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": -10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
]
}
示例:函数聚合
注释
此功能目前以预览版提供,可通过 latest preview REST API 和提供该功能的 Azure SDK 预览包提供。
在单个计分配置文件中,可以指定多个评分函数,然后设置 "functionAggregation": "product"。 对所有函数进行高度评分的文档处于优先顺序,同时取消在一个或多个字段中评分较弱的文档。
在此示例中,创建一个计分配置文件,其中包含两个提升函数,这些函数分别通过rating和baseRate进行提升,接着将functionAggregation设置为product。
### Create a new index
PUT {{url}}/indexes/hotels-scoring?api-version=2026-05-01-preview
Content-Type: application/json
api-key: {{key}}
{
"name": "hotels-scoring",
"fields": [
{"name": "HotelId", "type": "Edm.String", "key": true, "filterable": true, "facetable": true},
{"name": "HotelName", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": true, "facetable": true},
{"name": "Description", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": true, "analyzer": "en.lucene"},
{"name": "Category", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true},
{"name": "Tags", "type": "Collection(Edm.String)", "searchable": true, "filterable": true, "sortable": false, "facetable": true},
{"name": "ParkingIncluded", "type": "Edm.Boolean", "filterable": true, "sortable": true, "facetable": true},
{"name": "LastRenovationDate", "type": "Edm.DateTimeOffset", "filterable": true, "sortable": true, "facetable": true},
{"name": "Rating", "type": "Edm.Double", "filterable": true, "sortable": true, "facetable": true},
{"name": "BaseRate", "type": "Edm.Double", "filterable": true, "sortable": true, "facetable": true },
{"name": "Address", "type": "Edm.ComplexType",
"fields": [
{"name": "StreetAddress", "type": "Edm.String", "filterable": false, "sortable": false, "facetable": true, "searchable": true},
{"name": "City", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true},
{"name": "StateProvince", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true},
{"name": "PostalCode", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "facetable": true}
]
}
],
"scoringProfiles": [
{
"name": "productAggregationProfile",
"functions": [
{
"type": "magnitude",
"fieldName": "Rating",
"boost": 2.0,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1.0,
"boostingRangeEnd": 5.0,
"constantBoostBeyondRange": false
}
},
{
"type": "magnitude",
"fieldName": "BaseRate",
"boost": 1.5,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 50.0,
"boostingRangeEnd": 400.0,
"constantBoostBeyondRange": false
}
}
],
"functionAggregation": "product"
}
],
"defaultScoringProfile": "productAggregationProfile"
}
下一个请求将使用可搜索的内容加载索引,这些内容用于测试概况。
### Upload documents to the index
POST {{url}}/indexes/hotels-scoring/docs/index?api-version=2026-05-01-preview
Content-Type: application/json
api-key: {{key}}
{
"value": [
{
"@search.action": "upload",
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of Beijing. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make Beijing one of America's most attractive and cosmopolitan cities.",
"Category": "Boutique",
"Tags": [ "view", "air conditioning", "concierge" ],
"ParkingIncluded": false,
"LastRenovationDate": "2022-01-18T00:00:00Z",
"Rating": 3.60,
"BaseRate": 200.0,
"Address":
{
"StreetAddress": "677 5th Ave",
"City": "Beijing",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"@search.action": "upload",
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts. The hotel also regularly hosts events like wine tastings, beer dinners, and live music.",
"Category": "Boutique",
"Tags": [ "pool", "free wifi", "concierge" ],
"ParkingIncluded": false,
"LastRenovationDate": "2019-02-18T00:00:00Z",
"Rating": 3.60,
"BaseRate": 150.0,
"Address":
{
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"@search.action": "upload",
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Gastronomic Landscape Hotel stands out for its culinary excellence under the management of William Dough, who advises on and oversees all of the Hotel's restaurant services.",
"Category": "Suite",
"Tags": [ "restaurant", "bar", "continental breakfast" ],
"ParkingIncluded": true,
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.80,
"BaseRate": 350.0,
"Address":
{
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"@search.action": "upload",
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 19th century resort, updated for every modern convenience.",
"Tags": [ "concierge", "view", "air conditioning" ],
"ParkingIncluded": true,
"LastRenovationDate": "2020-02-06T00:00:00Z",
"Rating": 4.60,
"BaseRate": 275.0,
"Address":
{
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
运行使用计分配置文件中的条件的查询,以基于高评分和高基率提升结果。 聚合提升分数,以进一步增强在这两个功能中均获得高分的结果。
### Search with boost
POST {{url}}/indexes/hotels-scoring/docs/search?api-version=2026-05-01-preview
Content-Type: application/json
api-key: {{key}}
{
"search": "expensive and good hotels",
"count": true,
"select": "HotelId, HotelName, Description, Rating, BaseRate",
"scoringProfile": "productAggregationProfile"
}
此查询的最高响应是“文体景观酒店”,搜索分数几乎是下一个最接近的匹配项的两倍。 这家特别的酒店具有最高的评级和最高的基价,因此两个函数的复合将推动该匹配位居榜首。
{
"@odata.count": 4,
"value": [
{
"@search.score": 1.0541908,
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Gastronomic Hotel stands out for its culinary excellence under the management of William Dough, who advises on and oversees all of the Hotel\u2019s restaurant services.",
"Rating": 4.8,
"BaseRate": 350.0
},
{
"@search.score": 0.53451097,
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts. The hotel also regularly hosts events like wine tastings, beer dinners, and live music.",
"Rating": 3.6,
"BaseRate": 150.0
},
{
"@search.score": 0.53185254,
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of Beijing. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make Beijing one of America's most attractive and cosmopolitan cities.",
"Rating": 3.6,
"BaseRate": 200.0
},
{
"@search.score": 0.44853577,
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 19th century resort, updated for every modern convenience.",
"Rating": 4.6,
"BaseRate": 275.0
}
]
}
调优建议
从保守起步:将提升保持在1.25-2.0的范围内,只有当近因确实具有决定性时才增加。
窗口大小调整:将 P30D 用于热内容,将 P90D / P180D 用于中等最近度,将 P365D 用于长尾内容。
内插选项:
- 当你希望有一个强力促进以最近数据的二次方形式。
- 如果需要稳定渐变,则为线性。
- 需要温和效果时,使用对数曲线。
聚合:如果合并多个函数,则求和最简单;当希望单个信号主宰时切换到最大值