适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
在 pipeline 中,Azure Databricks 笔记本活动会在您的 Azure Databricks 工作区中运行一个 Databricks 笔记本。 本文基于数据转换活动一文,它概述了数据转换和受支持的转换活动。 Azure Databricks是用于运行 Apache Spark 的托管平台。
可以使用 JSON 或直接通过 Azure Data Factory Studio 用户界面通过 ARM 模板创建 Databricks 笔记本。 有关如何使用用户界面创建 Databricks 笔记本活动的分步演练,请参阅教程 使用 Azure Data Factory 中的 Databricks Notebook 活动运行 Databricks 笔记本。
使用 UI 将 Azure Databricks 的笔记本活动添加到管道中
若要在管道中使用 Azure Databricks 的笔记本活动,请完成以下步骤:
在“管道活动”窗格中搜索“Notebook”,然后将“Notebook”活动拖到管道画布上。
如果尚未选择,请在画布上选择新的笔记本任务。
选择 Azure Databricks 选项卡,以选择或创建将执行 Notebook 活动的新Azure Databricks链接服务。
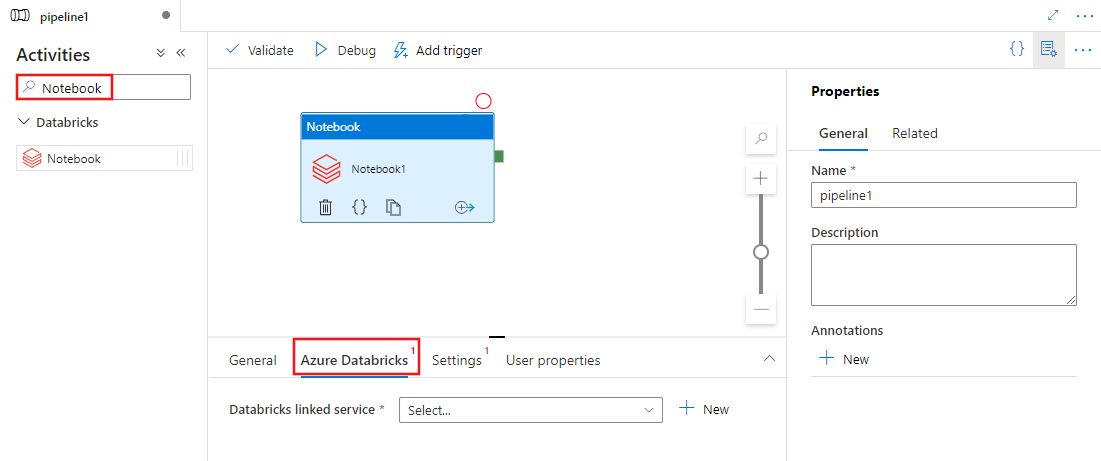
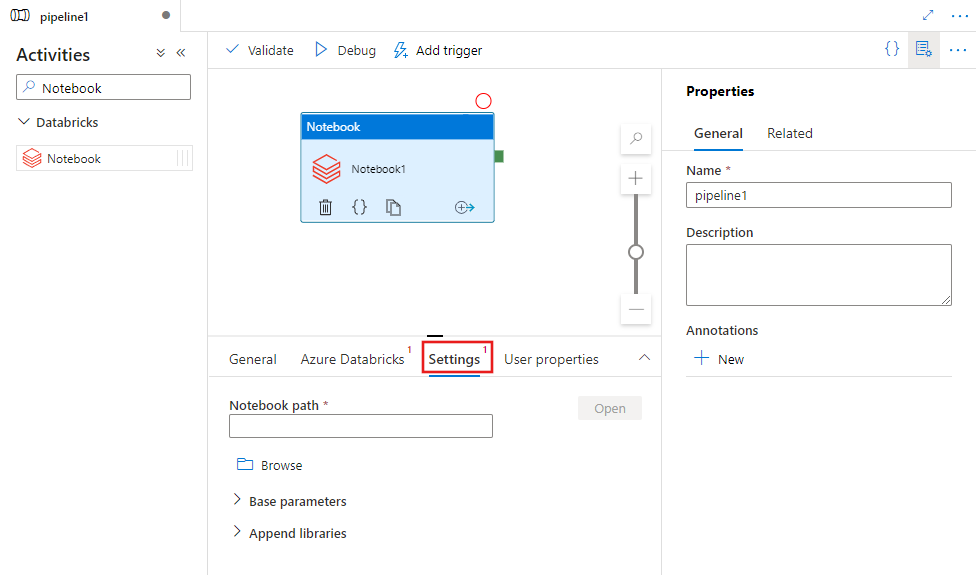
选择 Settings 选项卡,并指定要在 Azure Databricks 上执行的笔记本路径、要传递给笔记本的可选基参数,以及群集上安装的任何其他库来执行作业。
Databricks Notebook 活动定义
下面是 Databricks 笔记本活动的示例 JSON 定义:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Databricks Notebook 活动属性
下表描述了 JSON 定义中使用的 JSON 属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 名称 | 管道中活动的名称。 | 是 |
| 描述 | 描述活动用途的文本。 | 否 |
| 类型 | 对于 Databricks Notebook 活动,活动类型是 DatabricksNotebook。 | 是 |
| linkedServiceName | Databricks 链接服务的名称,Databricks Notebook 在其上运行。 若要了解此链接服务,请参阅计算链接服务一文。 | 是 |
| 笔记本路径 | 要在 Databricks 工作区中运行的 Notebook 的绝对路径。 此路径必须以斜杠开头。 | 是 |
| 基础参数 | 一个键/值对的数组。 基参数可用于运行每个活动。 如果笔记本采用的参数未指定,则使用笔记本中的默认值。 有关参数的更多信息,请参阅 Databricks Notebook。 | 否 |
| 库 | 要安装在将执行作业的群集上的库列表。 它可以是 <字符串、对象> 数组。 | 否 |
Databricks 活动所支持的库
在以上 Databricks 活动定义中,指定这些库类型:jar、egg、whl、maven、pypi、cran 。
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
有关详细信息,请参阅针对库类型的 Databricks 文档。
在笔记本和管道之间传递参数
可以使用 Databricks 活动中的 baseParameters 属性将参数传递给笔记本。
在某些情况下,你可能需要将某些值从笔记本传回服务,这些值可用于服务中的控制流(条件检查)或由下游活动使用(大小限制为 2 MB)。
在笔记本中,可以调用 dbutils.notebook.exit("returnValue"),相应的“returnValue”会返回到服务。
可以在服务中使用表达式(如
@{activity('databricks notebook activity name').output.runOutput})来获取该输出。重要
如果要传递 JSON 对象,可以通过追加属性名称来检索值。 示例:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
如何上传 Databricks 中的库
您可以使用工作区 UI:
若要获取使用 UI 添加的库的 dbfs 路径,可以使用 Databricks CLI。
使用 UI 时,Jar 库通常存储在 dbfs:/FileStore/jars 下。 可以通过 CLI 列出所有项目:databricks fs ls dbfs:/FileStore/job-jars
或者,可以使用 Databricks CLI:
遵循以下步骤进行使用 Databricks CLI 复制库操作
使用 Databricks CLI(安装步骤)
例如,将 JAR 复制到 dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar