了解如何协调笔记本并在笔记本中模块化代码。 请参阅示例并了解何时使用笔记本编排的替代方法。
业务流程和代码模块化方法
下表比较了可用于在笔记本中编排笔记本和模块化代码的方法。
| 方法 | 用例 | 注释 |
|---|---|---|
| Lakeflow 作业 | 笔记本编排(建议) | 用于编排笔记本的建议方法。 支持具有任务依赖项、计划和触发器的复杂工作流。 为生产工作负荷提供可靠且可缩放的方法,但需要设置和配置。 |
| dbutils.notebook.run() | 笔记本编排 | 如果作业无法满足你的使用场景,例如无法根据元数据文件动态运行笔记本(元数据驱动的 ETL),请使用 dbutils.notebook.run()。为每次调用启动一个新的临时作业,这可能会增加开销,并且缺乏高级调度功能。 |
| 工作区文件 | 代码模块化(建议) | 用于模块化代码的建议方法。 将代码模块化为存储在工作区中的可重用代码文件。 支持使用存储库进行版本控制,并与 IDE 集成,以便进行更好的调试和单元测试。 需要其他设置才能管理文件路径和依赖项。 |
| %run | 代码模块化 | 如果无法访问工作区文件,请使用 %run 。通过内联方式从其他笔记本导入函数或变量。 适用于原型制作,但可能会导致紧密耦合的代码难以维护。 不支持参数传递或版本控制。 |
%run 与 dbutils.notebook.run()
使用 %run 命令,可在笔记本中包含另一个笔记本。 可以通过 %run 将支持函数放在单独的笔记本中来模块化代码。 你还可以使用它来连接用于实现分析中的步骤的笔记本。 使用 %run 时,被调用的笔记本会立即执行,其中定义的函数和变量在调用笔记本中变为可用。
dbutils.notebook API 补充了%run,因为它能够接受参数传入笔记本并返回结果。 这使你可以生成包含依赖项的复杂工作流和管道。 例如,你可以获取目录中的文件列表,并将名称传递给另一个笔记本,而这在%run中是不可能的。 还可以基于返回值创建 if-then-else 工作流。
与 %run 不同,dbutils.notebook.run() 方法会启动一个新作业来运行笔记本。
与所有 dbutils API 一样,这些方法仅在 Python 和 Scala 中可用。 但可使用 dbutils.notebook.run() 调用 R 笔记本。
使用 %run 导入笔记本
在此示例中,第一个笔记本定义了函数 reverse,该函数在你使用 %run magic 执行 shared-code-notebook 后将在第二个笔记本中可用。
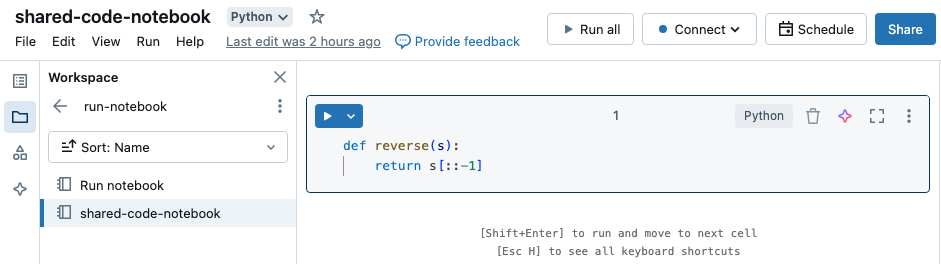
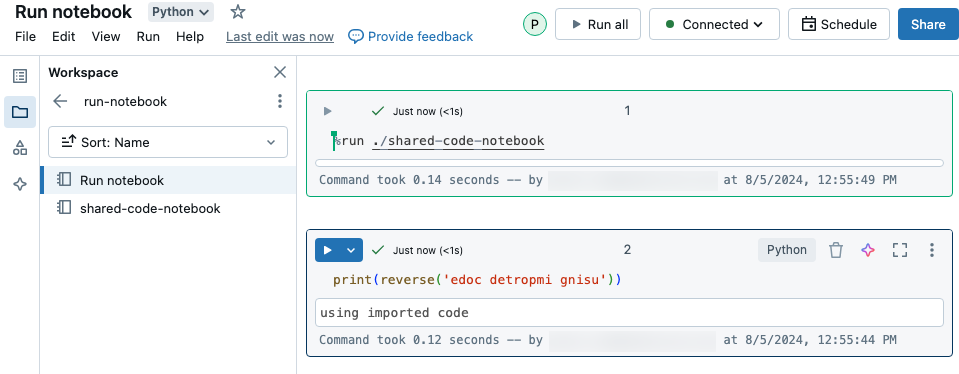
由于这两个笔记本都位于工作区中的同一目录中,因此请使用前缀././shared-code-notebook来指示路径应当按照当前正在运行的笔记本进行解析。 可以将笔记本组织到目录中,例如 %run ./dir/notebook,或使用 %run /Users/username@organization.com/directory/notebook 等绝对路径。
注意
-
%run必须独自位于某个单元格中,因为它会以内联方式运行整个笔记本。 - 不能使用 来运行 Python 文件并将该文件中定义的实体
%run到笔记本中。 若要从 Python 文件导入,请参阅使用文件将代码模块化。 或者,将文件打包到 Python 库,从该 Python 库创建 Azure Databricks 库,然后将库安装到用于运行笔记本的群集。 - 当使用
%run运行包含小部件的笔记本时,默认情况下,指定的笔记本会用小部件的默认值进行运行。 还可以将值传递给小组件;请参阅将 Databricks 小组件与 %run 配合使用。
使用 dbutils.notebook.run 启动新作业
运行笔记本并返回其退出值。 该方法会启动一个立即运行的临时作业。
在 dbutils.notebook API 中可用的方法为 run 和 exit。 参数和返回值都必须是字符串。
run(path: String, timeout_seconds: int, arguments: Map): String
参数 timeout_seconds 控制运行的超时(0 表示无超时)。 如果在指定时间内未完成,则调用 run 将引发异常。 如果 Azure Databricks 停机超过 10 分钟,无论 timeout_seconds 怎样,笔记本运行都会失败。
arguments 参数用于设置目标笔记本中小组件的值。 具体来说,如果您运行的笔记本中有一个名为 A 的小组件,并且您将键值对 ("A": "B") 作为参数的一部分传递给 run() 调用,那么检索小组件 A 的值时会返回 "B"。 可以在 Databricks 小组件 页中找到有关创建和使用小组件的说明。
注意
-
arguments参数只接受拉丁字符(ASCII 字符集)。 使用非 ASCII 字符会返回错误。 - 使用
dbutils.notebookAPI 创建的作业必须在 30 天或更短时间内完成。
run 使用
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala(编程语言)
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
在笔记本之间传递结构化数据
本部分说明如何在笔记本之间传递结构化数据。
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala(编程语言)
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
处理错误
本部分说明如何处理错误。
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala(编程语言)
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
同时运行多个笔记本
可使用标准 Scala 和 Python 构造同时运行多个笔记本,如 Thread(Scala 和 Python)和 Future(Scala 和 Python)。 示例笔记本演示了如何使用这些构造。
下载以下 4 个笔记本。 这些笔记本是以 Scala 编写的。
将笔记本导入工作区中的单个文件夹。
运行并行运行脚本。