Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In this guide, we review the prerequisites, architecture considerations, and key components for deploying and operating a highly available Apache Kafka cluster on Azure Kubernetes Service (AKS) using the Strimzi Operator.
Important
Open-source software is mentioned throughout AKS documentation and samples. Software that you deploy is excluded from AKS service-level agreements, limited warranty, and Azure support. As you use open-source technology alongside AKS, consult the support options available from the respective communities and project maintainers to develop a plan.
Microsoft takes responsibility for building the open-source packages that we deploy on AKS. That responsibility includes having complete ownership of the build, scan, sign, validate, and hotfix process, along with control over the binaries in container images. For more information, see Vulnerability management for AKS and AKS support coverage.
What is Apache Kafka and Strimzi?
Apache Kafka is an open-source distributed event streaming platform designed to handle high-volume, high-throughput, and real-time streaming data. As a result, it's used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. However, managing and scaling Kafka clusters can be challenging and often time-consuming.
Strimzi is an open-source project that simplifies the deployment, management, and operation of Apache Kafka on Kubernetes. It provides a set of Kubernetes Operators and container images that automate complex Kafka operational tasks through declarative configuration.
The Strimzi operators follow the Kubernetes operator pattern to automate Kafka operations. It continuously reconciles the declared state of Kafka components with their actual state, handling complex operational tasks automatically.
To learn more about Strimzi, review the Strimzi documentation.
Components
Strimzi Cluster Operator
The Strimzi Cluster Operator is the central component that manages the entire Kafka ecosystem. When deployed, it can also provision the Entity Operator, which consists of:
- Topic Operator: Automates the creation, modification, and deletion of Kafka topics based on
KafkaTopiccustom resources. - User Operator: Manages Kafka users and their Access Control Lists (ACLs) through
KafkaUsercustom resources.
Together, these operators create a fully declarative management system where your Kafka infrastructure is defined as Kubernetes resources that you can version control, audit, and consistently deploy across environments.
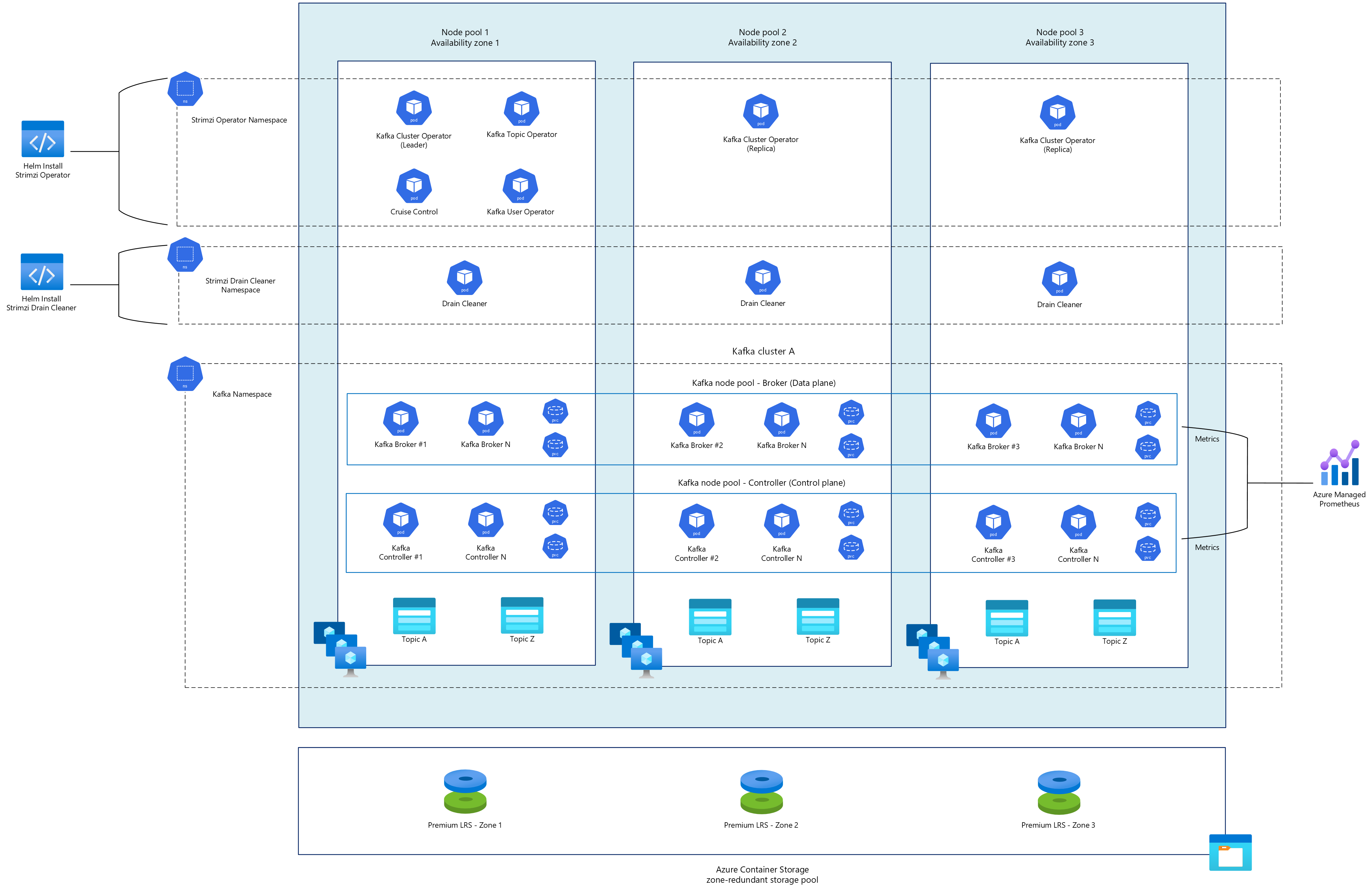
Kafka cluster
The Strimzi Cluster Operator manages Kafka clusters through specialized custom resources:
- KafkaNodePools: Define groups of Kafka nodes with specific roles (broker, controller, or both).
- Kafka: The main custom resource that ties everything together, defining cluster-wide configurations.
A typical deployment of KafkaNodePools and Kafka includes:
- Dedicated broker nodes that handle client traffic and data storage.
- Dedicated controller nodes that manage cluster metadata and coordination.
- Multiple replicas of each component distributed across availability zones.
Cruise Control
Cruise Control is an advanced component that provides automated workload balancing and monitoring for Kafka clusters. When deployed as part of a Strimzi-managed Kafka cluster, Cruise Control offers:
- Automated partition rebalancing: Redistributes partitions across brokers to optimize resource utilization.
- Anomaly detection: Identifies and alerts on abnormal cluster behavior.
- Self-healing capabilities: Automatically remedies common cluster imbalance issues.
- Workload analysis: Provides insights into cluster performance and resource usage.
Cruise Control helps maintain optimal performance as your workload changes over time, reducing the need for manual intervention during scaling events or following broker failures.
Drain Cleaner
Strimzi Drain Cleaner is a utility designed to help manage Kafka broker pods deployed by Strimzi during Kubernetes node draining. Strimzi Drain Cleaner intercepts Kubernetes node drain operations through its admission webhook to coordinate graceful maintenance of Kafka clusters. When an eviction request is made for Kafka broker pods, the request is detected and the Drain Cleaner annotates the pods to signal the Strimzi Cluster Operator to handle the restart, ensuring that the Kafka cluster remains in a healthy state. This process maintains cluster health and data reliability during routine maintenance operations or unexpected node failures.
When to use Kafka on AKS
Consider running Kafka on AKS when:
- You need complete control over Kafka configuration and operations.
- Your use case requires specific Kafka features not available in managed offerings.
- You want to integrate Kafka with other containerized applications running on AKS.
- You need to deploy in regions where managed Kafka services aren't available.
- Your organization has existing expertise in Kubernetes and container orchestration.
For simpler use cases or when operational overhead is a concern, consider fully managed services like Azure Event Hubs.
Key considerations for Kafka on AKS
Azure Disk Storage
For Kafka deployments on AKS, we use the Azure Disk CSI driver which provides persistent volumes backed by Azure managed disks. Strimzi leverages (Just a Bunch of Disks (JBOD) configuration to manage data persistence.
To ensure high availability across infrastructure failures, storage classes should be configured with Premium SSD v2 disks distributed across availability zones using the WaitForFirstConsumer volume binding mode. This ensures pods are scheduled in zones where their persistent volumes can be created. Premium SSD v2 can deliver the latency, high IOPS, and consistent throughput required by IO-intensive Kafka workloads at an optimized cost structure.
The following table provides starting points for Premium SSD v2 configurations across different Kafka cluster sizes:
| Kafka cluster size | Disk size | IOPS | Bandwidth |
|---|---|---|---|
| Small (3-9 brokers) |
1 TB | 5,000 | 250 MB/s |
| Medium (10-19 brokers) |
2 TB | 10,000 | 500 MB/s |
| Large (20+ brokers) |
4 TB | 20,000 | 1,000 MB/s |
The actual required IOPS, bandwidth, and disk size varies based on your specific Kafka workload characteristics. These properties can evolve over time as your application's throughput and retention requirements change.
Node pools
Selecting the appropriate node pools for your Kafka deployment on AKS is a critical architectural decision that directly impacts performance, availability, and cost efficiency. Kafka workloads have unique resource utilization patterns—characterized by high throughput demands, storage I/O intensity, and the need for consistent performance under varying loads. Kafka is typically more memory-intensive than CPU-intensive. However, CPU requirements can increase significantly with message compression/decompression, SSL/TLS encryption, or high-throughput scenarios with many small messages.
Considering Strimzi's Kubernetes-native architecture where each Kafka broker runs as an individual pod, your AKS node selection strategy should optimize for horizontal scaling rather than single-node vertical scaling. Proper node pool configuration on AKS ensures efficient resource utilization while maintaining the performance isolation that Kafka components require to operate reliably.
Kafka runs using a Java Virtual Machines (JVM). Tuning the JVM is critical for optimal Kafka performance, especially in production environments. LinkedIn, the creators of Kafka, shared the typical arguments for running Kafka on Java for one of LinkedIn's busiest clusters: Kafka Java Configuration.
For this guide, a memory heap of 6GB will be used as a baseline for brokers, with an additional 2GB allocated to accommodate off-heap memory usage. For controllers, a 3GB memory heap will be used as a baseline, with an additional 1GB as overhead.
When sizing VMs for your Kafka deployment, consider these workload-specific factors:
| Workload factor | Impact on sizing | Considerations |
|---|---|---|
| Message throughput | Higher throughput requires more CPU, memory, and network capacity. | - Monitor bytes in/out per second. - Consider peak vs. average throughput. - Account for future growth projections. |
| Message size | Message sizing has an impact on CPU, network, and disk requirements. | - Small messages (≤1KB) are more CPU-bound. - Large messages (>1MB) are more network-bound. - Very large messages might require specialized tuning. |
| Retention period | Longer retention increases storage requirements. | - Calculate total storage needs based on throughput × retention. |
| Consumer count | More consumers increase CPU and network load. | - Each consumer group adds overhead. - High fan-out patterns require additional resources. |
| Topic partitioning | Partition counts impact memory utilization. | - Each partition consumes memory resources. - Over-partitioning can degrade performance. |
| Infrastructure overhead | Additional system components impact available resources for Kafka. | - The Azure Disk CSI driver has minimal resource overhead. - Monitoring agents, logging components, network policies, and security tools add extra overhead. - Reserve an overhead for system components. |
Important
The following recommendations serve as starting guidance only. Your optimal VM SKU selection should be tailored to your specific Kafka workload characteristics, data patterns, and performance requirements. Each broker pod is estimated to have ~8GB of reserved memory. Each controller pod is estimated to have ~4GB of reserved memory. Your JVM and heap memory requirements might be larger or smaller.
Small to medium Kafka clusters
| VM SKU | vCPUs | RAM | Network | Broker density (Estimates) | Key benefits |
|---|---|---|---|---|---|
| Standard_D8ds | 8 | 32 GB | 12,500 Mbps | 1-3 per node | Cost-effective for horizontal scaling but might require more nodes as scale increases. |
| Standard_D16ds | 16 | 64 GB | 12,500 Mbps | 3-6 per node | More efficient resource utilization with additional vCPU and RAM, requiring less AKS nodes. |
Large Kafka clusters
| VM SKU | vCPUs | RAM | Network | Broker density (Estimates) | Key benefits |
|---|---|---|---|---|---|
| Standard_E16ds | 16 | 128 GB | 12,500 Mbps | 6+ per node | - Better performance for data-intensive, large-scale operations with increased high memory-to-core ratios. - Can support larger memory heaps or more horizontal scaling. |
Before finalizing your production environment, we recommend taking the following steps:
- Perform load testing with representative data volumes and patterns.
- Monitor CPU, memory, disk, and network utilization during peak loads.
- Adjust AKS node pool SKUs based on observed bottlenecks.
- Review cost of node pool SKUs.
High availability and resilience
To ensure the high availability of your Kafka deployment, you should:
- Deploy across multiple availability zones.
- Configure proper replica distribution constraints.
- Implement appropriate pod disruption budgets.
- Configure Cruise Control for topic partition rebalancing.
- Use Strimzi Drain Cleaner to handle node draining and maintenance operations.
Monitoring and operations
Effective monitoring of Kafka clusters includes:
- JMX metrics collection configuration.
- Consumer lag monitoring with Kafka Exporter.
- Integration with Azure Managed Prometheus and Azure Managed Grafana.
- Alerting on key performance indicators and health metrics.
Next step
Contributors
Microsoft maintains this article. The following contributors originally wrote it:
- Sergio Navar | Senior Customer Engineer
- Erin Schaffer | Content Developer 2