Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
适用于:![]() Azure SQL 数据库
Azure SQL 数据库
重要
SQL Data Sync 将于 2027 年 9 月 30 日停用。 请考虑迁移到备用数据复制/同步解决方案。
本教程将介绍如何创建包含 Azure SQL 数据库和 SQL Server 实例的同步组,从而设置 SQL 数据同步。 同步组进行了自定义配置,并根据设置的计划进行同步。
阅读本教程的前提是,至少具有 SQL 数据库和 SQL Server 领域的一些经验。
有关 SQL 数据同步的概述,请参阅什么是适用于 Azure 的 SQL 数据同步?
有关如何配置 SQL 数据同步的 PowerShell 示例,请参阅使用 PowerShell 在 SQL 数据库中的多个数据库之间同步数据或 在 Azure SQL 数据库和 SQL Server 中的数据库之间同步。
中心数据库是同步拓扑的中央终结点,同步组在其中具有多个数据库终结点。 同步组中具有终结点的所有其他成员数据库会与中心数据库进行同步。 SQL 数据同步仅在 Azure SQL 数据库上受支持。 中心数据库必须是 Azure SQL 数据库。
仅支持将 Azure SQL 数据库超大规模作为成员数据库,而不支持作为中心数据库。
创建同步组
转到 Azure 门户。 搜索并选择 SQL 数据库,以查找现有的 Azure SQL 数据库。
选择要用作数据同步的中心数据库的现有数据库。
在选定数据库的“SQL 数据库”资源菜单中的“数据管理”下,选择“同步到其他数据库”。
在“同步到其他数据库”页中,选择“新建同步组” 。 “创建数据同步组”页随即打开。
在“创建数据同步组”页中,配置以下设置:
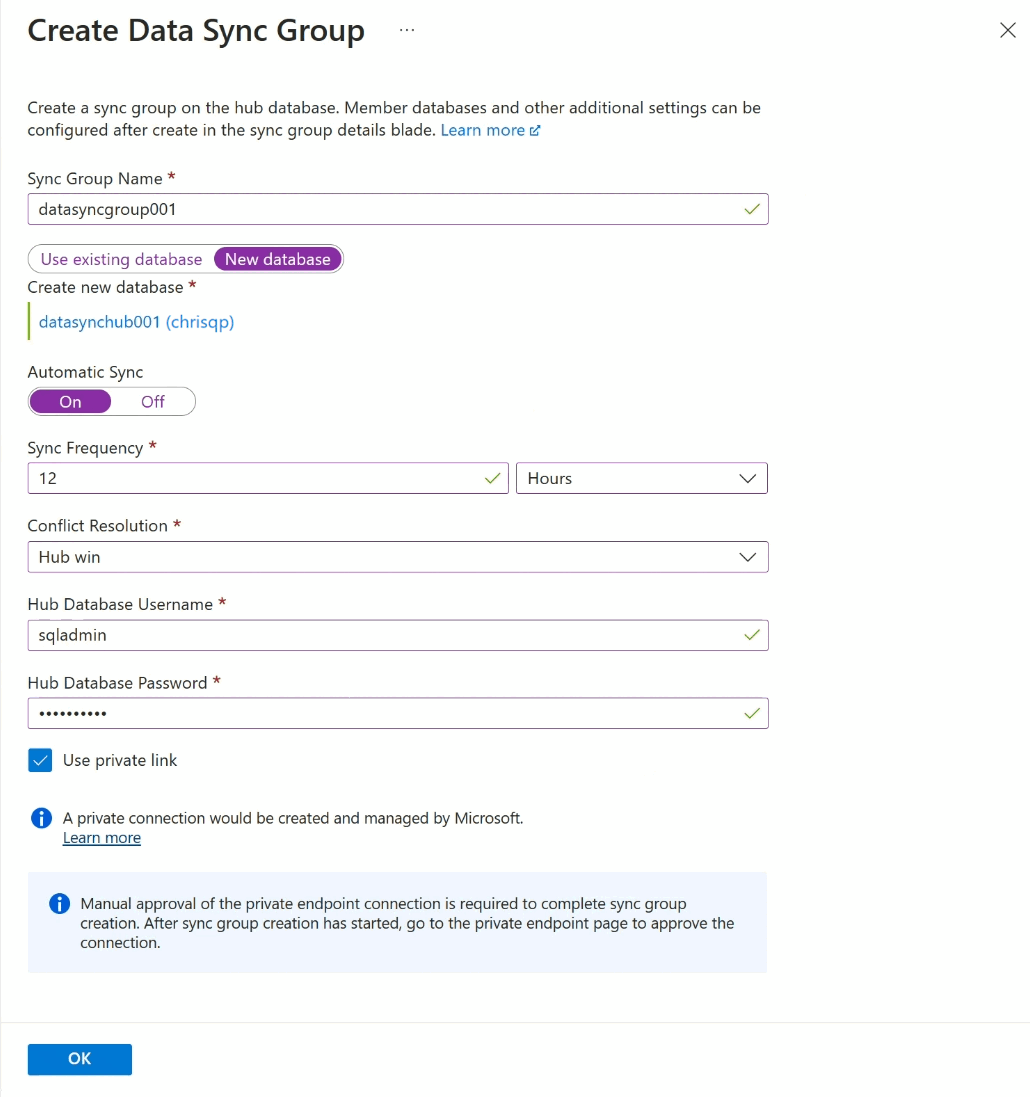
设置 说明 同步组名称 输入新同步组的名称。 此名称不同于数据库本身的名称。 同步元数据数据库 选择是新建数据库(推荐),还是使用现有数据库以用作同步元数据数据库。
Microsoft 建议创建新的空数据库,以将其用作同步元数据数据库。 SQL 数据同步在此数据库中创建表,并经常运行工作负载。 此数据库共享为选定区域和订阅中所有同步组的同步元数据数据库。 在未删除区域中所有同步组和同步代理的情况下,无法更改数据库或其名称。
如果选择新建数据库,请选择“新建数据库”。 选择“配置数据库设置”。 在“SQL 数据库”页面,命名并配置新的 Azure SQL 数据库,然后选择“确定”。
如果选择“使用现有数据库”,请从“同步元数据数据库”下拉列表中选择数据库。自动同步 选择“开”或“关” 。
如果选择“开”,请在“同步频率”部分中输入数字,然后选择“秒”、“分钟”、“小时”或“天”。
保存配置后,第一次同步将在经过所选间隔时间后开始。冲突解决方法 选择“中心胜出”或“成员胜出”。
“中心胜出”表示发生冲突时,中心数据库中的数据将覆盖成员数据库中的冲突数据。
“成员胜出”表示发生冲突时,成员数据库中的数据将覆盖中心数据库中的冲突数据。“中心数据库用户名”和“中心数据库密码” 为中心数据库的服务器管理员 SQL 身份验证登录名提供用户名和密码。 这是您开始使用的同一 Azure SQL 逻辑服务器的服务器管理员的用户名和密码。 不支持 Microsoft Entra(以前称为 Azure Active Directory)身份验证。 使用专用链接 选择服务管理的专用终结点,以在同步服务和中心数据库之间建立安全连接。 选择“确定”,并等待创建和部署同步组。
在“新建同步组”页上,如果你选择了“使用专用链接”,则需要批准专用终结点连接 。 信息消息中的链接会将你转到专用终结点连接体验,你可以在那里批准连接。
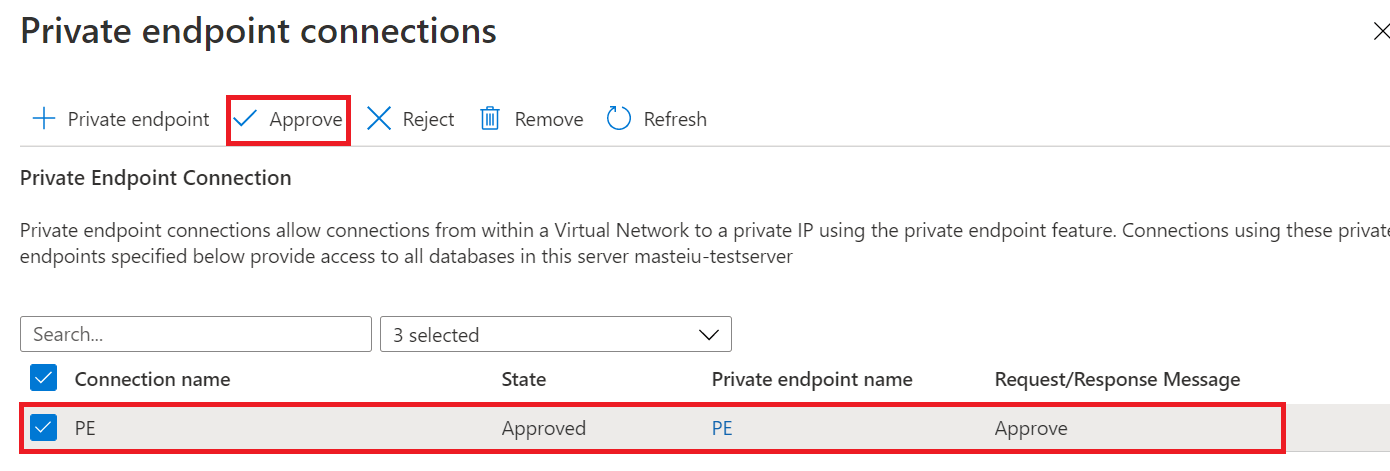
注意
同步组和同步成员的专用链接需单独创建、批准和禁用。


添加同步成员
创建并部署新的同步组后,打开该同步组并访问“数据库”页,你将在其中选择同步成员。
注意
要将用户名和密码更新或插入到中心数据库中,请转到“选择同步成员”页中的“中心数据库”部分 。
将 Azure SQL 数据库中的数据库作为成员添加到同步组中
在“选择同步成员”部分中,可视需要通过选择“添加 Azure 数据库”,将 Azure SQL 数据库中的数据库添加到同步组中 。 “配置 Azure 数据库”页随即打开。
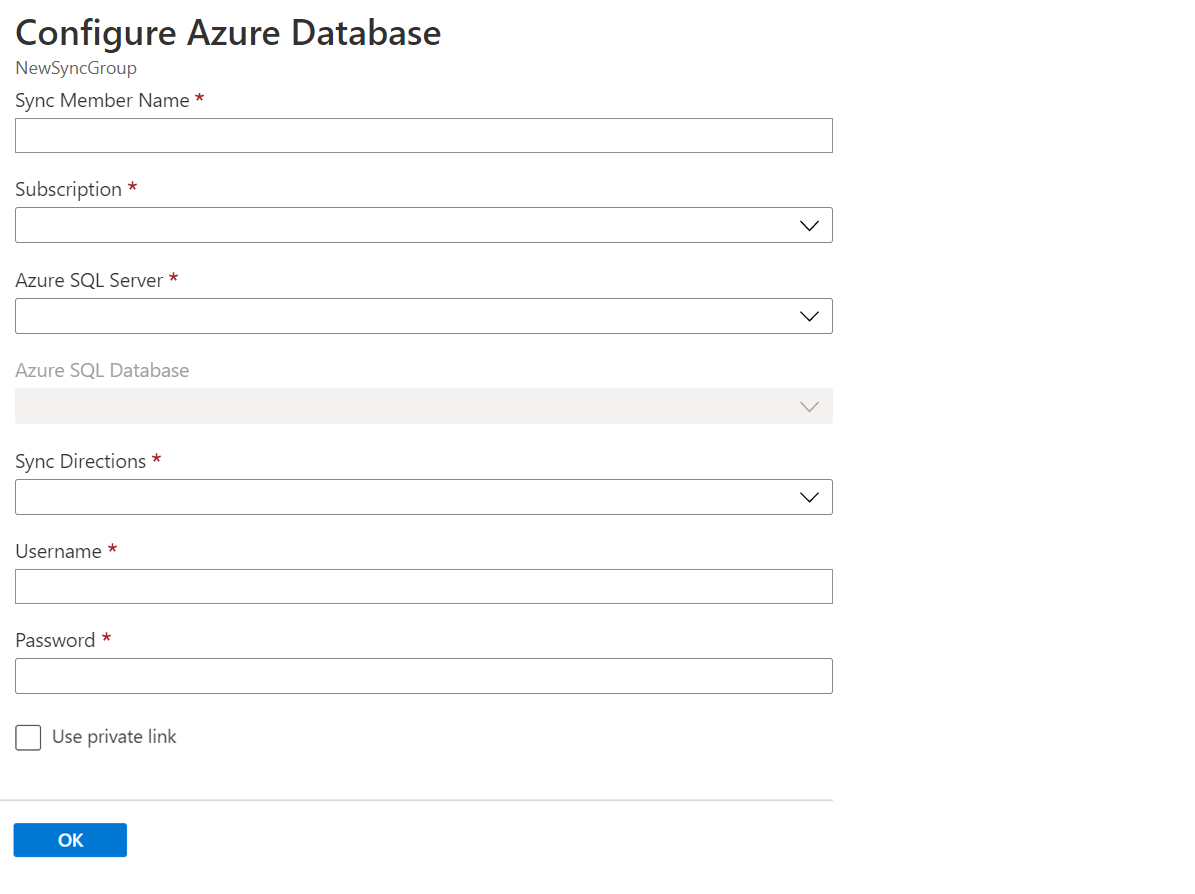
在“配置 Azure SQL 数据库”页中,更改以下设置:
设置 说明 同步成员名称 提供新同步成员的名称。 此名称不同于数据库本身的名称。 订阅 选择关联的 Azure 订阅,以用于计费。 Azure SQL Server 选择现有服务器。 Azure SQL 数据库 选择 SQL 数据库中的现有数据库。 同步方向 同步方向可以是“中心到成员”或“成员到中心”,或两者均可。 选择“从中心”、“到中心”或“双向同步”。有关详细信息,请参阅 工作原理。 “用户名”和“密码” 输入成员数据库所在的服务器的现有凭据。 请勿在此部分中输入新凭据。 使用专用链接 选择服务管理的专用终结点,以在同步服务和成员数据库之间建立安全连接。 选择“确定”,并等待新同步成员创建和部署完成。

将 SQL Server 实例上的数据库作为成员添加到同步组中
在“成员数据库”部分中,请根据需要选择“添加本地数据库”,从而将 SQL Server 实例添加到同步组。
随即打开“配置本地”页,可以在其中执行以下操作:
选择选择同步代理网关。 “选择同步代理”页随即打开。
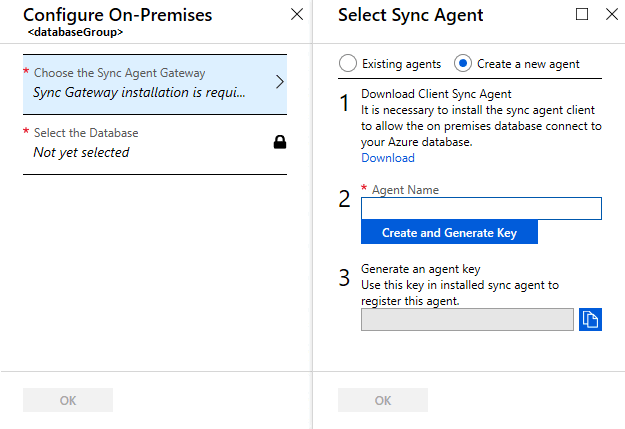
在“选择同步代理”页中,选择是使用现有代理还是创建代理。
如果选择“现有代理”,请从列表中选择现有代理。
如果选择“新建代理”,请执行以下操作:
从提供的链接下载数据同步代理,并将其安装在与 SQL Server 实例所在位置不同的服务器上。 还可以直接从 Azure SQL Data Sync Agent 下载代理。 有关同步客户端代理的最佳做法,请参阅 Azure SQL 数据同步最佳做法。
重要
必须在防火墙中打开出站 TCP 端口 1433,以便客户端代理能够与服务器进行通信。
输入代理名称。
选择“创建并生成密钥”并将代理密钥复制到剪贴板。
选择“确定”,关闭“选择同步代理”页。
在安装同步客户端代理的服务器上,定位并运行客户端同步代理应用。
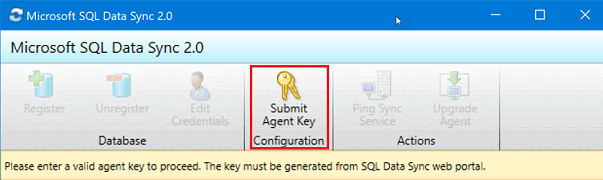
在同步代理应用程序中,选择“提交代理密钥”。 此时,“同步元数据数据库配置”对话框打开。
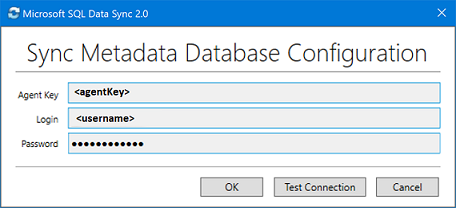
在“同步元数据数据库配置”对话框中,粘贴从 Azure 门户复制的代理密钥。 还需要输入同步元数据数据库数据库所在服务器的现有凭据。 选择“确定”,并等待配置完成。
注意
如果看到防火墙错误消息,请在 Azure 上创建防火墙规则,以允许来自 SQL Server 计算机的传入流量。 可以在门户中或在 SQL Server Management Studio (SSMS) 中手动创建规则。 在 SSMS 中,输入数据库名称
<hub_database_name>.database.chinacloudapi.cn,即可连接到 Azure 上的中心数据库。选择“注册”以向代理注册 SQL Server 数据库。 此时,“SQL Server 数据库配置”对话框打开。
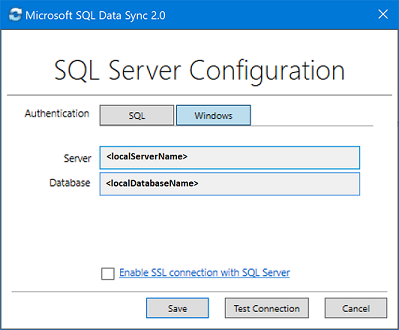
在“SQL Server 配置”对话框中,选择是使用 SQL Server 身份验证还是使用 Windows 身份验证进行连接。 如果选择 SQL Server 身份验证,请输入现有凭据。 提供 SQL Server 名称和要同步的数据库的名称,然后选择“测试连接”测试设置。 然后选择“保存”,注册的数据库将显示在列表中。
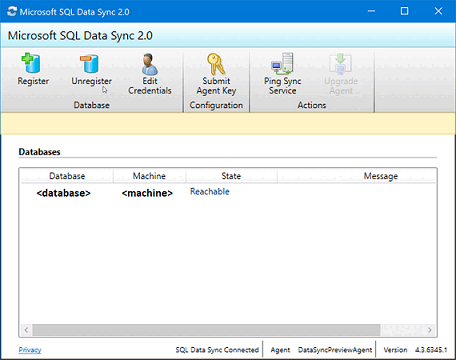
关闭客户端同步代理应用。
在 Azure 门户的“配置本地”页中,选择“选择数据库”。
在“选择数据库”页的“同步成员名称”字段中,输入新同步成员的名称。 此名称不同于数据库本身的名称。 从列表中选择数据库。 在“同步方向”字段中,选择“双向同步”、“向中心同步”或“从中心同步” 。
选择“确定”,关闭“选择数据库”页。 再选择“确定”,关闭“配置本地数据库”页,并等待新同步成员创建和部署完成。 最后,选择“确定”,关闭“选择同步成员”页 。
注意
要连接到 SQL 数据同步和本地代理,请将自己的用户名添加到角色 DataSync_Executor。 SQL 数据同步在 SQL Server 实例中创建此角色。
配置同步组
创建并部署新的同步组成员后,转到“数据库同步组”页中“表”部分 。

在“表”页中,依次选择同步组成员列表中的数据库和“刷新架构”。 刷新架构预计会延迟几分钟,如果使用专用链接,则该延迟可能会再延长几分钟。
从列表中,选择要同步的表。默认情况下,所有列都处于选中状态,因此请禁用不想同步的列的复选框。请务必保持主键列的选中状态不变。
选择“保存” 。
默认情况下,在计划或手动运行数据库之前,不会同步数据库。 若要运行手动同步,请在 Azure 门户中导航到 SQL 数据库中的数据库,选择“同步到其他数据库”,然后选择同步组。 “数据同步”页随即打开。 选择“同步”。
常见问题解答
本部分解答有关 Azure SQL 数据同步服务的常见问题。
SQL 数据同步是否能完全创建表?
如果目标数据库中缺少同步架构表,SQL 数据同步会根据您选择的列进行创建。 但是,由于以下原因,这不会导致完全保真架构:
- 仅在目标表中创建所选的列。 将忽略未选中的列。
- 仅在目标表中创建选定的列索引。 对于未选中的列,将忽略这些索引。
- 不会创建 XML 类型列的索引。
- 不会创建 CHECK 约束。
- 未在源表上创建触发器。
- 不会创建视图和存储过程。
考虑到这些限制,我们的建议如下:
- 对于生产环境,请自行创建完全保真架构。
- 在试验服务时,请使用自动预配功能。
为什么会看到没有创建的表?
数据同步在数据库中创建其他表用于跟踪更改。 请不要删除这些表,否则数据同步会停止运行。
同步后我的数据是否已对齐?
不一定。 具有一个中心和三个分支(A、B 和 C)的同步组,其中同步方向为从中心到 A、从中心到 B 和从中心到 C。如果在中心到 A 的同步完成后对数据库 A 进行了更改,则该更改不会在下一次同步任务之前写入数据库 B 或数据库 C。
如何将架构更改应用到同步组?
手动进行所有架构更改并对其进行传播。
- 将架构更改手动复制到中心以及所有同步成员。
- 更新同步架构。
添加新表和新列:
新表和新列在添加到同步架构之前不会影响当前同步,并且数据同步会将其忽略。 添加新的数据库对象时,请遵循以下顺序:
- 将新表或新列添加到中心,然后添加到所有同步成员。
- 将新表或新列添加到同步架构。
- 开始将值插入新表和新列中。
若要更改某列的数据类型:
更改现有列的数据类型时,数据同步会继续运行,前提是新值属于在同步架构中定义的原始数据类型。 例如,如果在源数据库中将类型从 int 更改为 bigint,除非插入的值对于 int 数据类型来说过大,否则数据同步会继续运行 。 要完成此更改,请将架构更改手动复制到中心以及所有同步成员,然后更新同步架构。
如何使用数据同步导出和导入数据库?
将数据库导出为 .bacpac 文件并导入该文件以创建数据库后,执行以下操作以在新数据库中使用数据同步:
- 使用数据同步完成 cleanup.sql 清理新数据库上的数据同步对象和其他表。 该脚本从数据库中删除所有必需的数据同步对象。
- 重新创建包含新数据库的同步组。 如果不再需要旧同步组,请删除它。
在哪里可以找到有关客户端代理的信息?
有关客户端代理的常见问题解答,请参阅代理常见问题解答。
是否需要手动批准该链接,然后才能开始使用它?
是的。 你必须在同步组部署期间或通过使用 PowerShell 在 Azure 门户的“专用终结点连接”页中手动批准服务管理的专用终结点。
为何在同步作业预配 Azure 数据库时出现防火墙错误?
这可能是因为不允许 Azure 资源访问服务器。 可运用以下两种解决方案:
- 确保 Azure 数据库上的防火墙将“允许 Azure 服务和资源访问此服务器”设置设为“是”。 有关详细信息,请参阅 Azure SQL 数据库和网络访问控制。
- 为数据同步配置专用链接,此链接不同于 Azure 专用链接。 专用链接用于使用与受防火墙保护的数据库的安全连接创建同步组。 SQL 数据同步专用链接是 Microsoft 托管的终结点,在现有虚拟网络内部创建子网,因此无需创建另一个虚拟网络或子网。