Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Switch services using the Version drop-down list. Learn more about navigation.
Applies to: ✅ Microsoft Sentinel
Kusto Query Language (KQL) is a powerful tool for querying and analyzing data in Microsoft Sentinel. As a security analyst, mastering KQL can significantly enhance your ability to detect threats and respond to incidents effectively. This article provides a comprehensive guide to performing common tasks with KQL, helping you manipulate and analyze data efficiently.
In this tutorial, you learn the basics of KQL, including understanding query structure, getting, limiting, sorting, and filtering data, summarizing data, and joining tables. Additionally, you explore advanced concepts such as using the evaluate operator and let statements to create more complex and maintainable queries.
Prerequisites
Before reading this article, make sure that you're familiar with the basics of Kusto Query Language (KQL). If you're new to KQL, see:
- Kusto Query Language (KQL) overview
- Syntax conventions for reference documentation
- Scalar data types
- Demo environment
Understanding query structure basics
A good place to start learning Kusto Query Language is to understand the overall query structure. The first thing you notice when looking at a Kusto query is the use of the pipe symbol (|). The structure of a Kusto query starts with getting your data from a data source and then passing the data across a pipeline. Each step provides some level of processing and then passes the data to the next step. At the end of the pipeline, you get your final result. In effect, this pipeline looks like:
Get Data | Filter | Summarize | Sort | Select
This concept of passing data down the pipeline makes for an intuitive structure, as it's easy to create a mental picture of your data at each step.
To illustrate this concept, take a look at the following query, which looks at Microsoft Entra sign-in logs. As you read through each line, you can see the keywords that indicate what's happening to the data. The relevant stage in the pipeline is included as a comment in each line.
Note
You can add comments to any line in a query by preceding them with a double slash (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Because the output of every step serves as the input for the following step, the order of the steps can determine the query's results and affect its performance. It's crucial that you order the steps according to what you want to get out of the query.
A good rule of thumb is to filter your data early, so you pass only relevant data down the pipeline. This approach greatly increases performance and ensures that you don't accidentally include irrelevant data in summarization steps. For more information, see Best practices for Kusto Query Language queries.
Hopefully, you now have appreciation for the overall structure of a query in Kusto Query Language. Now let's look at the actual query operators themselves, which you use to create a query.
Getting, limiting, sorting, and filtering data
The core vocabulary of Kusto Query Language - the foundation that allows you to accomplish most of your tasks - is a collection of operators for filtering, sorting, and selecting your data. The remaining tasks require you to stretch your knowledge of the language to meet your more advanced needs. Let's expand a bit on some of the commands used in our earlier example and look at take, sort, and where.
For each of these operators, examine its use in the previous SigninLogs example, and learn either a useful tip or a best practice.
Getting data
The first line of any basic query specifies which table you want to work with. In the case of Microsoft Sentinel, this table is likely to be the name of a log type in your workspace, such as SigninLogs, SecurityAlert, or CommonSecurityLog. For example:
SigninLogs
In Kusto Query Language, log names are case sensitive, so SigninLogs and signinLogs are interpreted differently. Take care when choosing names for your custom logs, so they're easily identifiable and not too similar to another log.
Limiting data: take / limit
Use the take operator (or the identical limit operator) to limit your results by returning only a specific number of rows. Follow it with an integer that specifies the number of rows to return. Typically, use it at the end of a query after you determine your sort order. In this case, it returns the specified number of rows at the top of the sorted order.
Using take earlier in the query can be useful for testing a query when you don't want to return large datasets. However, if you place the take operation before any sort operations, take returns rows selected at random - and possibly a different set of rows every time you run the query. Here's an example of using take:
SigninLogs
| take 5

Tip
When working on a brand-new query where you might not know what the query looks like, it can be useful to put a take statement at the beginning to artificially limit your dataset for faster processing and experimentation. Once you're happy with the full query, remove the initial take step.
Sorting data: sort / order
Use the sort operator (and the identical order operator) to sort your data by a specified column. In the following example, the query orders the results by TimeGenerated and sets the order direction to descending with the desc parameter, placing the highest values first. For ascending order, use asc.
Note
The default direction for sorts is descending, so technically you only need to specify if you want to sort in ascending order. However, specifying the sort direction in any case makes your query more readable.
SigninLogs
| sort by TimeGenerated desc
| take 5
As mentioned earlier, place the sort operator before the take operator. You need to sort first to make sure you get the appropriate five records.

Top
The top operator combines the sort and take operations into a single operator:
SigninLogs
| top 5 by TimeGenerated desc
In cases where two or more records have the same value in the column you're sorting by, add more columns to sort by. Add extra sorting columns in a comma-separated list, located after the first sorting column, but before the sort order keyword. For example:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Now, if TimeGenerated is the same between multiple records, the query tries to sort by the value in the Identity column.
Note
When to use sort and take, and when to use top
If you're only sorting on one field, use
top, as it provides better performance than the combination ofsortandtake.If you need to sort on more than one field (like in the last example),
topcan't do that, so you must usesortandtake.
Filtering data: where
The where operator is the most important operator because it's the key to making sure you're only working with the subset of data that's relevant to your scenario. Filter your data as early in the query as possible because it improves query performance by reducing the amount of data that needs to be processed in subsequent steps. It also ensures that you're only performing calculations on the desired data. See this example:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
The where operator specifies a variable, a comparison (scalar) operator, and a value. In this example, use >= to denote that the value in the TimeGenerated column needs to be greater than (that is, later than) or equal to seven days ago.
There are two types of comparison operators in Kusto Query Language: string and numerical. String operators support permutations for case sensitivity, substring locations, prefixes, suffixes, and much more.
The == operator is both a numeric and string operator, meaning it can be used for both numbers and text. For example, both of the following statements are valid where statements:
| where ResultType == 0| where Category == 'SignInLogs'
For more information, see Numerical operators and String operators.
Best Practice: In most cases, filter your data by more than one column, or filter the same column in more than one way. In these instances, keep these two best practices in mind.
Combine multiple where statements into a single step by using the keyword and. For example:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
When you have multiple filters joined into a single where statement by using the keyword and, you get better performance by putting filters that only reference a single column first. So, a better way to write the previous query is:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
In this example, the first filter mentions a single column (TimeGenerated), while the second filter references two columns (Resource and ResourceGroup).
Summarizing data
Summarize is one of the most important tabular operators in Kusto Query Language. It's also one of the more complex operators to learn if you're new to query languages in general. The job of summarize is to take in a table of data and output a new table that's aggregated by one or more columns.
Structure of the summarize statement
The basic structure of a summarize statement is as follows:
| summarize <aggregation> by <column>
For example, the following query returns the count of records for each CounterName value in the Perf table:
Perf
| summarize count() by CounterName

Because the output of summarize is a new table, the query doesn't pass any columns that aren't explicitly specified in the summarize statement down the pipeline. To illustrate this concept, consider this example:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
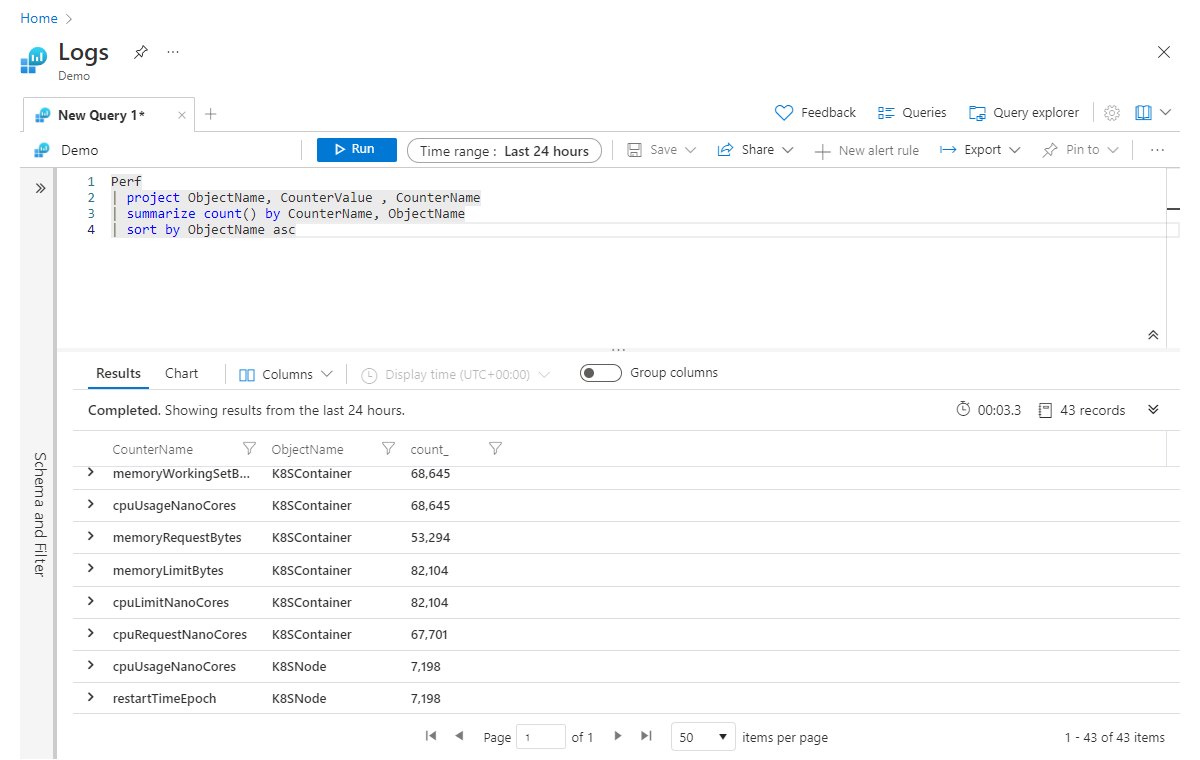
On the second line, you specify that you only care about the columns ObjectName, CounterValue, and CounterName. You then summarize to get the record count by CounterName and finally, you attempt to sort the data in ascending order based on the ObjectName column. Unfortunately, this query fails with an error (indicating that the ObjectName is unknown) because when you summarized, you only included the Count and CounterName columns in your new table. To avoid this error, add ObjectName to the end of your summarize step, like this:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
The way to read the summarize line in your head is: "summarize the count of records by CounterName, and group by ObjectName." You can continue adding columns, separated by commas, to the end of the summarize statement.
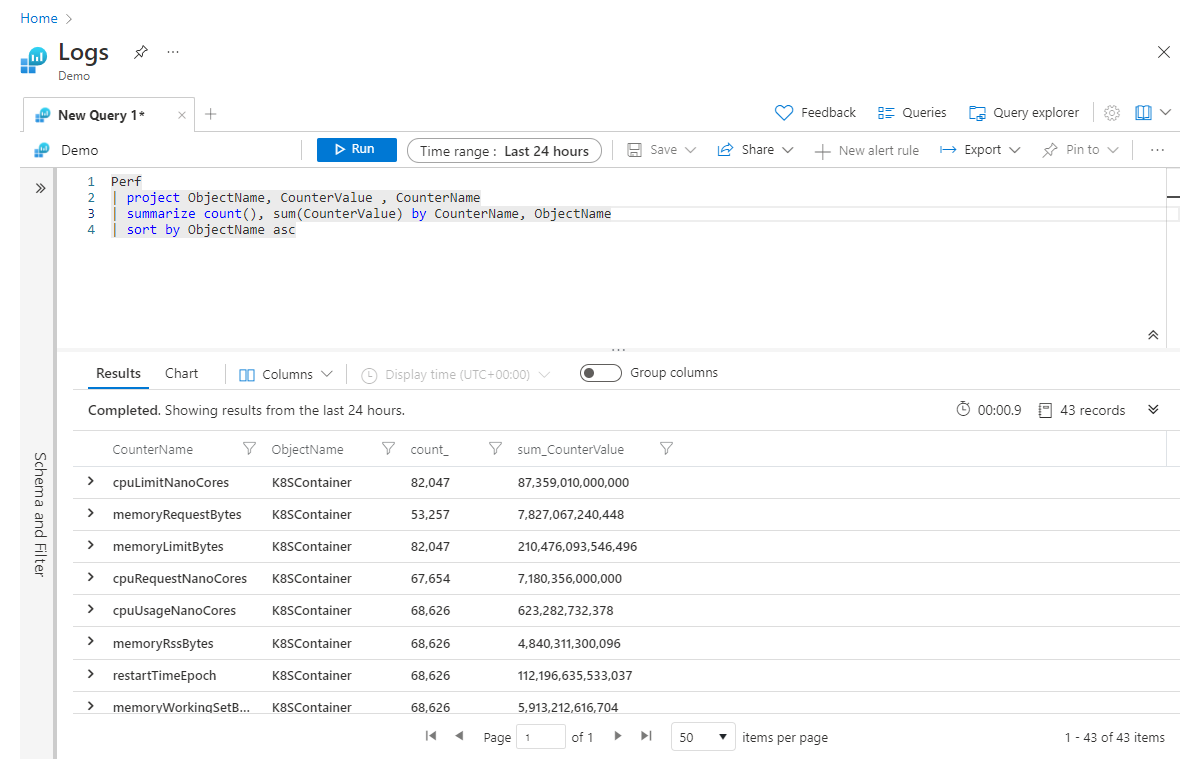
Building on the previous example, if you want to aggregate multiple columns at the same time, add aggregations to the summarize operator, separated by commas. In the example below, you get not only a count of all the records but also a sum of the values in the CounterValue column across all records (that match any filters in the query):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Renaming aggregated columns
This section explains column names for these aggregated columns. At the start of this section, you learned that the summarize operator takes in a table of data and produces a new table, and only the columns you specify in the summarize statement continue down the pipeline. Therefore, if you run the preceding example, the resulting columns for your aggregation are count_ and sum_CounterValue.
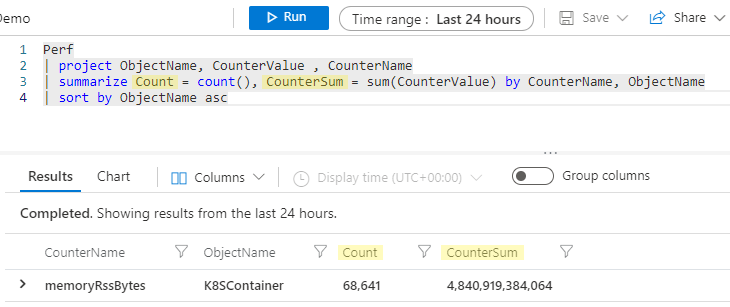
The Kusto engine automatically creates a column name without you having to be explicit, but often, you prefer your new column to have a friendlier name. You can easily rename your column in the summarize statement by specifying a new name, followed by = and the aggregation, like so:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Now, your summarized columns are named Count and CounterSum.
There's more to the summarize operator than this article can cover, but you should invest the time to learn it because it's a key component to any data analysis you plan to perform on your Microsoft Sentinel data.
Aggregation reference
Many aggregation functions are available, but some of the most commonly used ones are sum(), count(), and avg(). For more information, see Aggregation function types at a glance.
Selecting: adding and removing columns
As you work more with queries, you might find that you have more information than you need on your subjects (that is, too many columns in your table). Or you might need more information than you have (that is, you need to add a new column that contains the results of analysis of other columns). Let's look at a few of the key operators for column manipulation.
Project and project-away
Project is roughly equivalent to many languages' select statements. It allows you to choose which columns to keep. The order of the columns returned matches the order of the columns you list in your project statement, as shown in this example:
Perf
| project ObjectName, CounterValue, CounterName

As you can imagine, when you're working with wide datasets, you might have lots of columns you want to keep, and specifying them all by name requires much typing. For those cases, you have project-away, which lets you specify which columns to remove, rather than which ones to keep, like so:
Perf
| project-away MG, _ResourceId, Type
Tip
It can be useful to use project in two locations in your queries, at the beginning and again at the end. Using project early in your query can help improve performance by stripping away large chunks of data you don't need to pass down the pipeline. Using it again at the end lets you get rid of any columns that previous steps created and aren't needed in your final output.
Extend
Use Extend to create a new calculated column. This approach is helpful when you want to perform a calculation against existing columns and see the output for every row. Let's look at a simple example where you calculate a new column called Kbytes, which you calculate by multiplying the MB value (in the existing Quantity column) by 1,024.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project DataType, MBytes=Quantity, KBytes
On the final line in the project statement, you rename the Quantity column to Mbytes, so you can easily tell which unit of measure is relevant to each column.

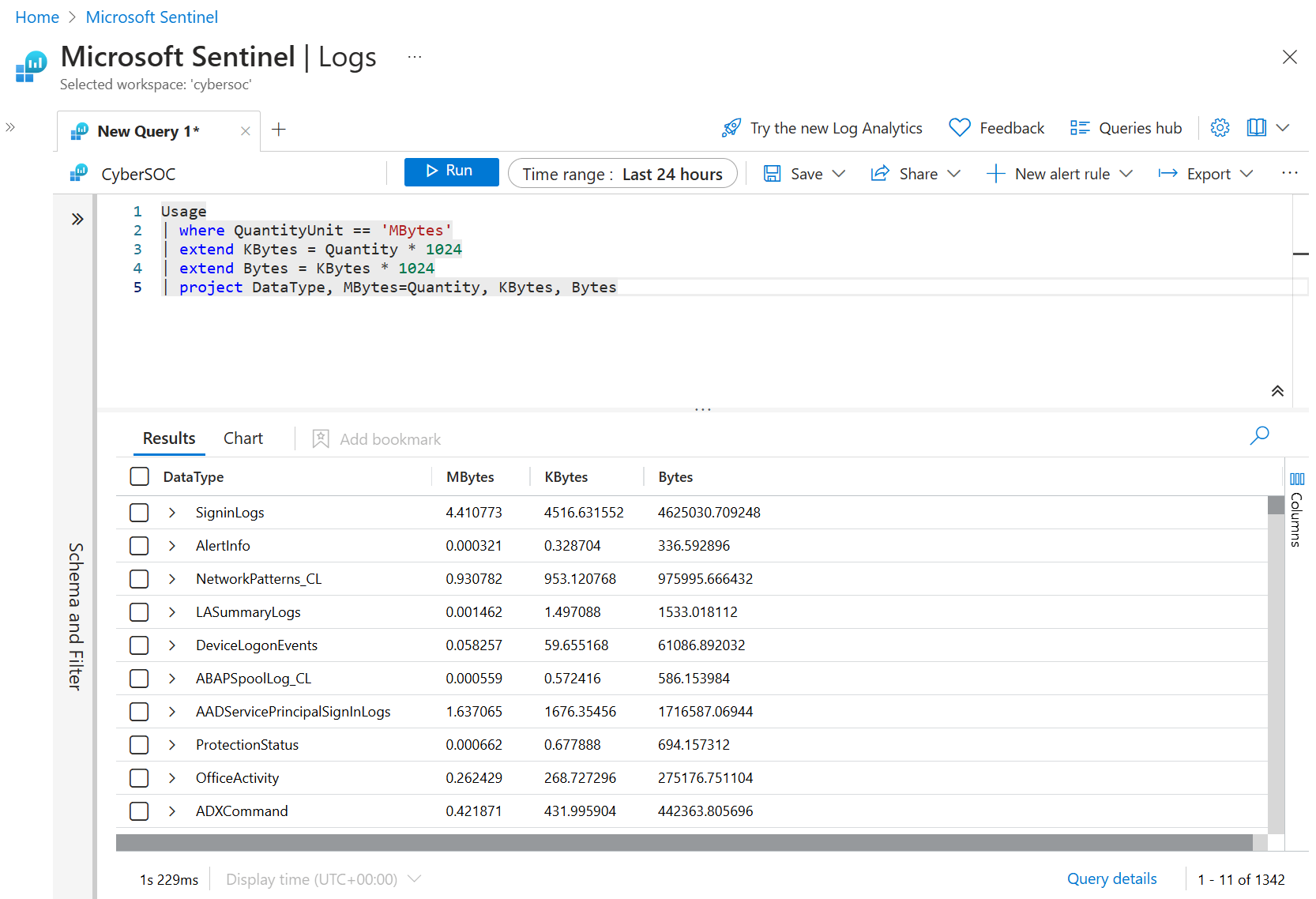
It's worth noting that extend also works with already calculated columns. For example, you can add one more column called Bytes that is calculated from Kbytes:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project DataType, MBytes=Quantity, KBytes, Bytes
Joining tables
You can carry out much of your work in Microsoft Sentinel by using a single log type, but there are times when you want to correlate data together or perform a lookup against another set of data. Like most query languages, Kusto Query Language offers a few operators that you can use to perform various types of joins. In this section, you look at the most-used operators, union and join.
Union
Union takes two or more tables and returns all the rows. For example:
OfficeActivity
| union SecurityEvent
This query returns all rows from both the OfficeActivity and SecurityEvent tables. Union offers a few parameters that you can use to adjust how the union behaves. Two of the most useful parameters are withsource and kind:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
Use the withsource parameter to specify the name of a new column whose value in a given row is the name of the table from which the row came. In the example, you name the column SourceTable, and depending on the row, the value is either OfficeActivity or SecurityEvent.
The other parameter you specify is kind, which has two options: inner or outer. In the example, you specify inner, which means the only columns that are kept during the union are those that exist in both tables. Alternatively, if you specify outer (which is the default value), then the query returns all columns from both tables.
Join
Join works similarly to union, except instead of joining tables to make a new table, it joins rows to make a new table. Like most database languages, you can perform multiple types of joins. The general syntax for a join is:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
After the join operator, specify the kind of join you want to perform followed by an open parenthesis. Within the parentheses, specify the table you want to join, and add any other query statements on that table. After the closing parenthesis, use the on keyword followed by your left ($left.<columnName> keyword) and right ($right.<columnName>) columns separated by using the == operator. Here's an example of an inner join:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Note
If both tables have the same name for the columns on which you're performing a join, you don't need to use $left and $right. Instead, just specify the column name. However, using $left and $right is more explicit and generally considered to be a good practice.
Tip
It's a best practice to have your smallest table on the left. In some cases, following this rule can give you huge performance benefits, depending on the types of joins you're performing and the size of the tables.
For more information, see join operator.
Evaluate
You might remember that back in the first example, you saw the evaluate operator on one of the lines. The evaluate operator is less commonly used than the ones discussed previously. However, knowing how the evaluate operator works is well worth your time. Once more, here's that first query, where you see evaluate on the second line.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
This operator invokes available plugins (built-in functions). Many of these plugins focus on data science, such as autocluster, diffpatterns, and sequence_detect. By using these plugins, you can perform advanced analysis and discover statistical anomalies and outliers.
The plugin used in the example is called bag_unpack. It makes it simple to take a chunk of dynamic data and convert it to columns. Remember, dynamic data is a data type that looks similar to JSON, as shown in this example:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
In this case, you want to summarize the data by city, but city is contained as a property within the LocationDetails column. To use the city property in your query, you need to first convert it to a column by using bag_unpack.
Going back to the original pipeline steps, you saw this:
Get Data | Filter | Summarize | Sort | Select
Now that you considered the evaluate operator, you can see that it represents a new stage in the pipeline, which now looks like this:
Get Data | Parse | Filter | Summarize | Sort | Select
Many other examples of operators and functions exist that you can use to parse data sources into a more readable and manipulable format. Learn about them - and the rest of the Kusto Query Language - in Kusto Query Language learning resources and in the workbook.
Let statements
Now that we've covered many of the major operators and data types, let's wrap up with the let statement, which is a great way to make your queries easier to read, edit, and maintain.
Let allows you to create and set a variable, or to assign a name to an expression. This expression could be a single value, but it could also be a whole query. Here's a simple example:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Here, we specified a name of aWeekAgo and set it to be equal to the output of a timespan function, which returns a datetime value. We then terminate the let statement with a semicolon. Now we have a new variable called aWeekAgo that can be used anywhere in our query.
As we mentioned, you can use a let statement take a whole query and give the result a name. Since query results, being tabular expressions, can be used as the inputs of queries, you can treat this named result as a table for the purposes of running another query on it. Here's a slight modification to the previous example:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
In this case, we created a second let statement, where we wrapped our whole query into a new variable called getSignins. Just like before, we terminate the second let statement with a semicolon. Then we call the variable on the final line, which runs the query. Notice that we were able to use aWeekAgo in the second let statement. This is because we specified it on the previous line; if we were to swap the let statements so that getSignins came first, we would get an error.
Now we can use getSignins as the basis of another query (in the same window):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Let statements give you more power and flexibility in helping to organize your queries. Let can define scalar and tabular values as well as create user-defined functions. They truly come in handy when you're organizing more complex queries that might be doing multiple joins.
Next step
Take advantage of a Kusto Query Language workbook right in Microsoft Sentinel itself - the Advanced KQL for Microsoft Sentinel workbook. It gives you step-by-step help and examples for many of the situations you're likely to encounter during your day-to-day security operations, and also points you to lots of ready-made, out-of-the-box examples of analytics rules, workbooks, hunting rules, and more elements that use Kusto queries. Launch this workbook from the Workbooks page in Microsoft Sentinel.
For more information, see: