Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
The Azure Databricks Jar Activity in a pipeline runs a Spark Jar in your Azure Databricks cluster. This article builds on the data transformation activities article, which presents a general overview of data transformation and the supported transformation activities. Azure Databricks is a managed platform for running Apache Spark.
Add a Jar activity for Azure Databricks to a pipeline with UI
To use a Jar activity for Azure Databricks in a pipeline, complete the following steps:
Search for Jar in the pipeline Activities pane, and drag a Jar activity to the pipeline canvas.
Select the new Jar activity on the canvas if it is not already selected.
Select the Azure Databricks tab to select or create a new Azure Databricks linked service that will execute the Jar activity.
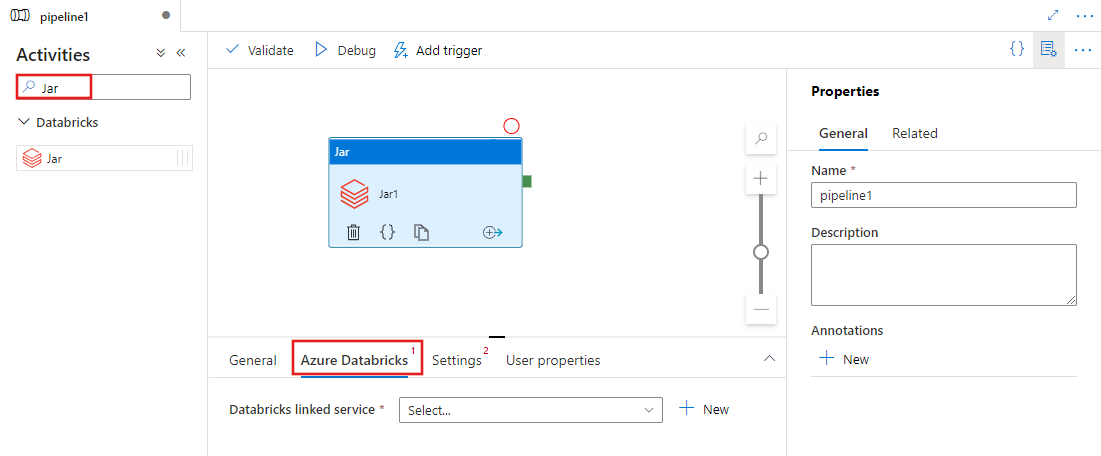
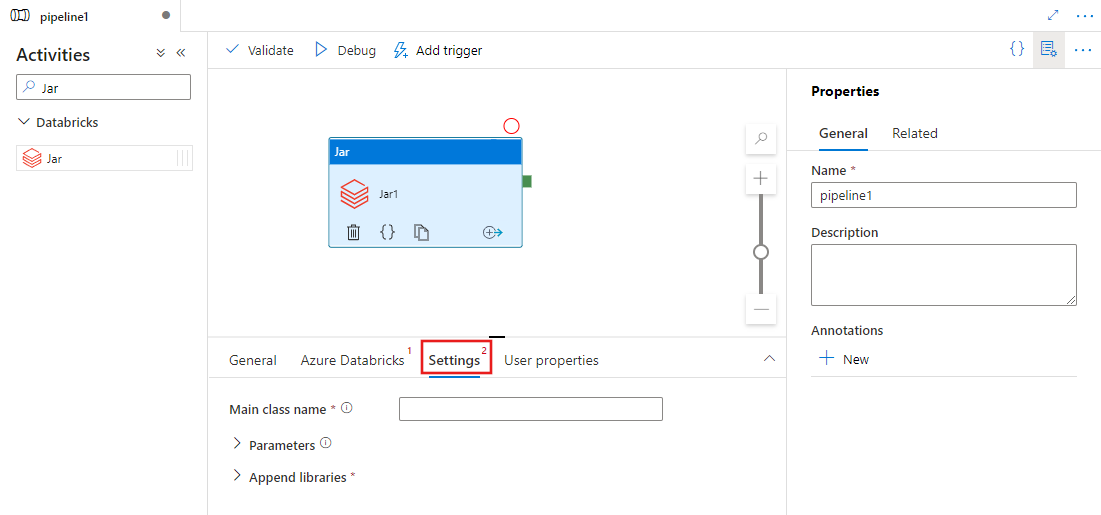
Select the Settings tab and specify a class name to be executed on Azure Databricks, optional parameters to be passed to the Jar, and libraries to be installed on the cluster to execute the job.
Databricks Jar activity definition
Here's the sample JSON definition of a Databricks Jar Activity:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Databricks Jar activity properties
The following table describes the JSON properties used in the JSON definition:
| Property | Description | Required |
|---|---|---|
| name | Name of the activity in the pipeline. | Yes |
| description | Text describing what the activity does. | No |
| type | For Databricks Jar Activity, the activity type is DatabricksSparkJar. | Yes |
| linkedServiceName | Name of the Databricks Linked Service on which the Jar activity runs. To learn about this linked service, see Compute linked services article. | Yes |
| mainClassName | The full name of the class containing the main method to be executed. This class must be contained in a JAR provided as a library. A JAR file can contain multiple classes. Each of the classes can contain a main method. | Yes |
| parameters | Parameters that will be passed to the main method. This property is an array of strings. | No |
| libraries | A list of libraries to be installed on the cluster that will execute the job. It can be an array of <string, object> | Yes (at least one containing the mainClassName method) |
Note
Known Issue - When using the same Interactive cluster for running concurrent Databricks Jar activities (without cluster restart), there is a known issue in Databricks where in parameters of the 1st activity will be used by following activities as well. Hence resulting to incorrect parameters being passed to the subsequent jobs. To mitigate this use a Job cluster instead.
Supported libraries for databricks activities
In the previous Databricks activity definition, you specified these library types: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
For more information, see the Databricks documentation for library types.
How to upload a library in Databricks
You can use the Workspace UI:
To obtain the dbfs path of the library added using UI, you can use Databricks CLI.
Typically the Jar libraries are stored under dbfs:/FileStore/jars while using the UI. You can list all through the CLI: databricks fs ls dbfs:/FileStore/job-jars
Or you can use the Databricks CLI:
Use Databricks CLI (installation steps)
As an example, to copy a JAR to dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar