Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
The Azure Databricks Job Activity in a pipeline runs Databricks jobs in your Azure Databricks workspace, including serverless jobs. This article builds on the data transformation activities article, which presents a general overview of data transformation and the supported transformation activities. Azure Databricks is a managed platform for running Apache Spark.
You can create a Databricks job directly through the Azure Data Factory Studio user interface.
Add a Job activity for Azure Databricks to a pipeline with UI
To use a Job activity for Azure Databricks in a pipeline, complete the following steps:
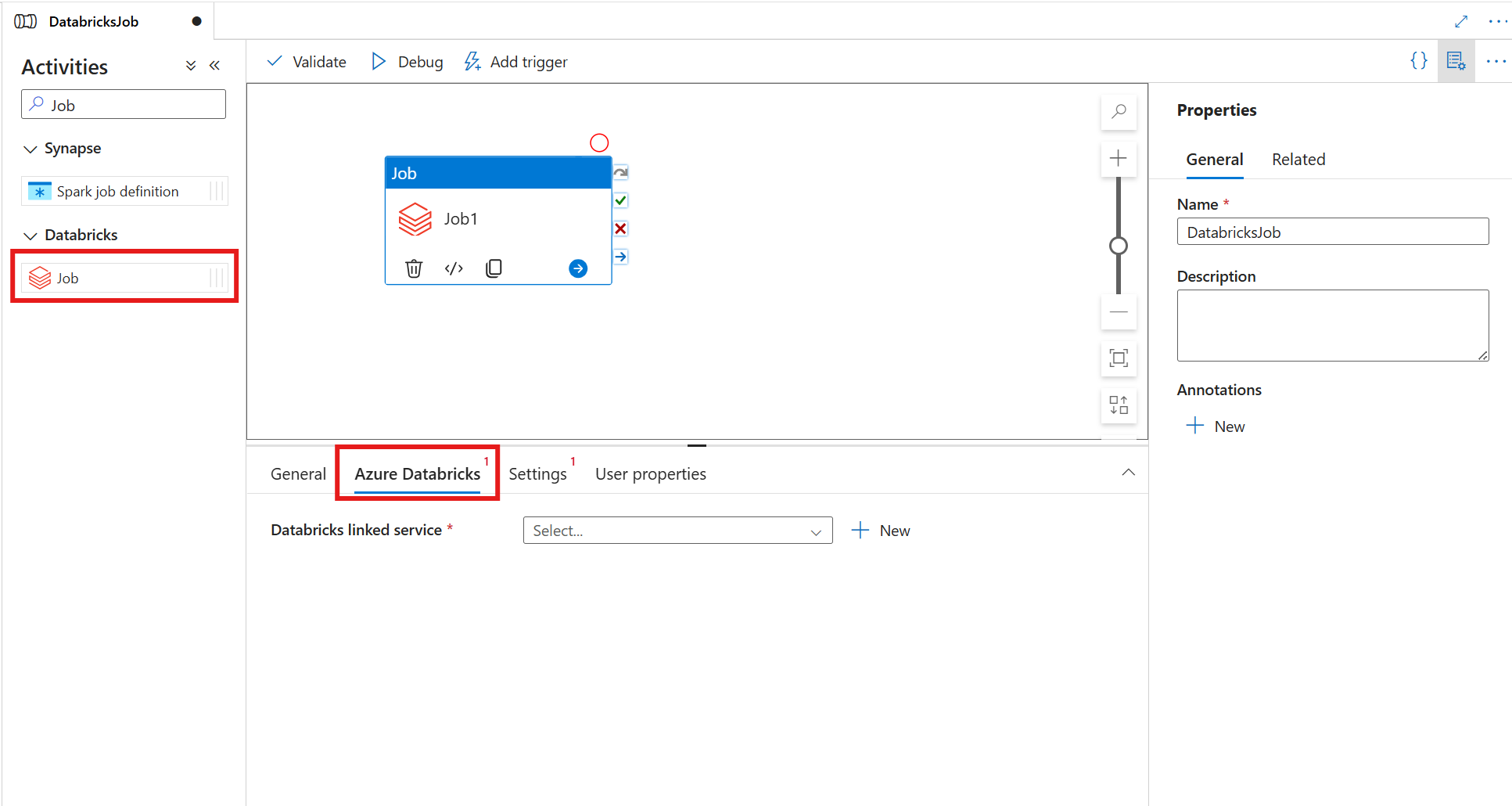
Search for Job in the pipeline Activities pane, and drag a Job activity to the pipeline canvas.
Select the new Job activity on the canvas if it isn't already selected.
Select the Azure Databricks tab to select or create a new Azure Databricks linked service.
Note
The Azure Databricks Job activity automatically runs on serverless clusters, so you don't need to specify a cluster in your linked service configuration. Instead, choose the Serverless option.
Select the Settings tab and specify the job to be executed on Azure Databricks, optional base parameters to be passed to the job, and any other libraries to be installed on the cluster to execute the job.



Databricks Job activity definition
Here's the sample JSON definition of a Databricks Job Activity:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksJob",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"jobID": "012345678910112",
"jobParameters": {
"testParameter": "testValue"
},
}
}
}
Databricks Job activity properties
The following table describes the JSON properties used in the JSON definition:
| Property | Description | Required |
|---|---|---|
| name | Name of the activity in the pipeline. | Yes |
| description | Text describing what the activity does. | No |
| type | For Databricks Job Activity, the activity type is DatabricksJob. | Yes |
| linkedServiceName | Name of the Databricks Linked Service on which the Databricks job runs. To learn about this linked service, see Compute linked services article. | Yes |
| jobId | The ID of the job to be run in the Databricks Workspace. | Yes |
| jobParameters | An array of Key-Value pairs. Job parameters can be used for each activity run. If the job takes a parameter that isn't specified, the default value from the job will be used. Find more on parameters in Databricks Jobs. | No |
Passing parameters between jobs and pipelines
You can pass parameters to jobs using jobParameters property in Databricks activity.
Note
Job parameters are only supported in Self-hosted IR version 5.52.0.0 or greater.