Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
If you're new to Azure Data Factory, see Introduction to Azure Data Factory.
In this tutorial, you'll learn best practices that can be applied when writing files to ADLS Gen2 or Azure Blob Storage using data flows. You'll need access to an Azure Blob Storage Account or Azure Data Lake Store Gen2 account for reading a parquet file and then storing the results in folders.
Prerequisites
- Azure subscription. If you don't have an Azure subscription, create a trial Azure account before you begin.
- Azure storage account. You use ADLS storage as a source and sink data stores. If you don't have a storage account, see Create an Azure storage account for steps to create one.
The steps in this tutorial will assume that you have
Create a data factory
In this step, you create a data factory and open the Data Factory UX to create a pipeline in the data factory.
Open Microsoft Edge or Google Chrome. Currently, Data Factory UI is supported only in the Microsoft Edge and Google Chrome web browsers.
On the left menu, select Create a resource > Integration > Data Factory
On the New data factory page, under Name, enter ADFTutorialDataFactory
Select the Azure subscription in which you want to create the data factory.
For Resource Group, take one of the following steps:
a. Select Use existing, and select an existing resource group from the drop-down list.
b. Select Create new, and enter the name of a resource group. To learn about resource groups, see Use resource groups to manage your Azure resources.
Under Location, select a location for the data factory. Only locations that are supported are displayed in the drop-down list. Data stores (for example, Azure Storage and SQL Database) and computes (for example, Azure HDInsight) used by the data factory can be in other regions.
Select Create.
After the creation is finished, you see the notice in Notifications center. Select Go to resource to navigate to the Data factory page.
Select Author & Monitor to launch the Data Factory UI in a separate tab.
Create a pipeline with a data flow activity
In this step, you'll create a pipeline that contains a data flow activity.
On the home page of Azure Data Factory, select Orchestrate.
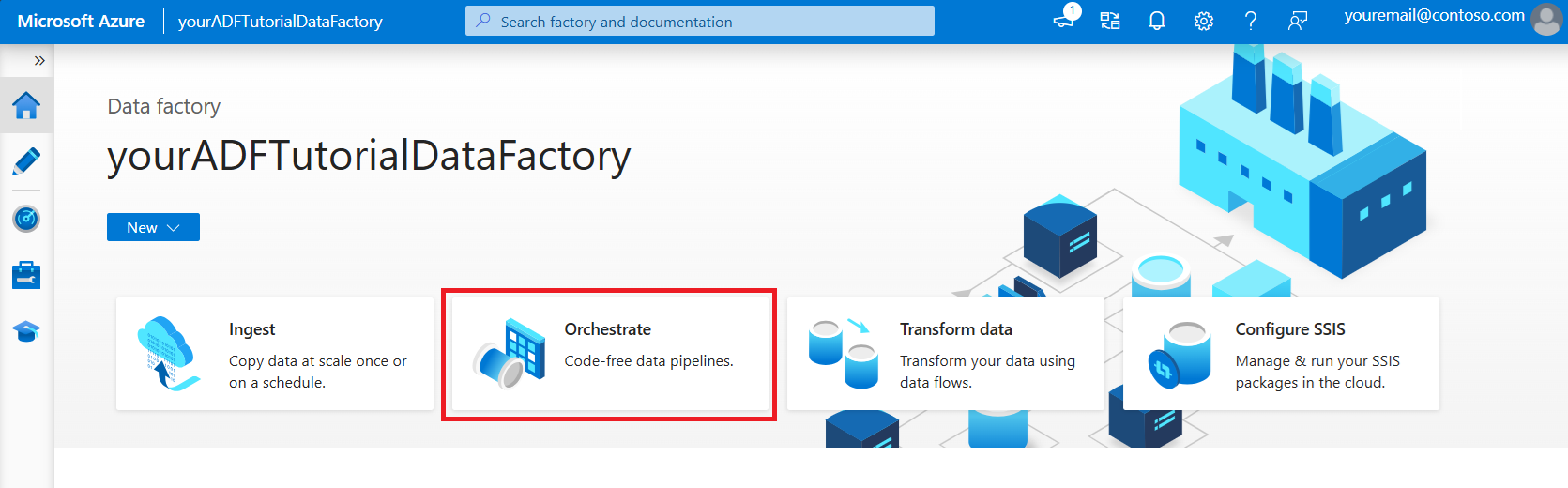
In the General tab for the pipeline, enter DeltaLake for Name of the pipeline.
In the factory top bar, slide the Data Flow debug slider on. Debug mode allows for interactive testing of transformation logic against a live Spark cluster. Data Flow clusters take 5-7 minutes to warm up and users are recommended to turn on debug first if they plan to do Data Flow development. For more information, see Debug Mode.

In the Activities pane, expand the Move and Transform accordion. Drag and drop the Data Flow activity from the pane to the pipeline canvas.
Build transformation logic in the data flow canvas
You will take any source data (in this tutorial, we'll use a Parquet file source) and use a sink transformation to land the data in Parquet format using the most effective mechanisms for data lake ETL.

Tutorial objectives
- Choose any of your source datasets in a new data flow 1. Use data flows to effectively partition your sink dataset
- Land your partitioned data in ADLS Gen2 lake folders
Start from a blank data flow canvas
First, let's set up the data flow environment for each of the mechanisms described below for landing data in ADLS Gen2
- Click on the source transformation.
- Click the new button next to dataset in the bottom panel.
- Choose a dataset or create a new one. For this demo, we'll use a Parquet dataset called User Data.
- Add a Derived Column transformation. We'll use this as a way to set your desired folder names dynamically.
- Add a sink transformation.
Hierarchical folder output
It is very common to use unique values in your data to create folder hierarchies to partition your data in the lake. This is a very optimal way to organize and process data in the lake and in Spark (the compute engine behind data flows). However, there will be a small performance cost to organize your output in this way. Expect to see a small decrease in overall pipeline performance using this mechanism in the sink.
- Go back to the data flow designer and edit the data flow create above. Click on the sink transformation.
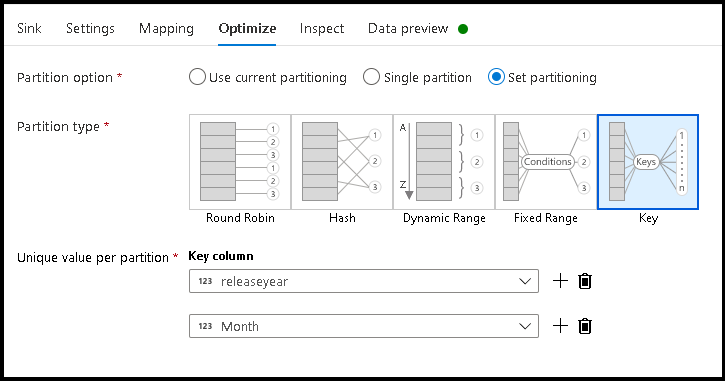
- Click Optimize > Set partitioning > Key
- Pick the column(s) you wish to use to set your hierarchical folder structure.
- Note the example below uses year and month as the columns for folder naming. The results will be folders of the form
releaseyear=1990/month=8. - When accessing the data partitions in a data flow source, you will point to just the top-level folder above
releaseyearand use a wildcard pattern for each subsequent folder, ex:**/**/*.parquet - To manipulate the data values, or even if need to generate synthetic values for folder names, use the Derived Column transformation to create the values you wish to use in your folder names.
Name folder as data values
A slightly better performing sink technique for lake data using ADLS Gen2 that does not offer the same benefit as key/value partitioning, is Name folder as column data. Whereas the key partitioning style of hierarchical structure will allow you to process data slices easier, this technique is a flattened folder structure that can write data quicker.
- Go back to the data flow designer and edit the data flow create above. Click on the sink transformation.
- Click Optimize > Set partitioning > Use current partitioning.
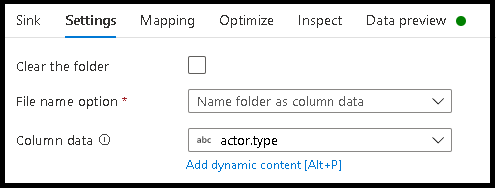
- Click Settings > Name folder as column data.
- Pick the column that you wish to use for generating folder names.
- To manipulate the data values, or even if need to generate synthetic values for folder names, use the Derived Column transformation to create the values you wish to use in your folder names.
Name file as data values
The techniques listed in the above tutorials are good use cases for creating folder categories in your data lake. The default file naming scheme being employed by those techniques is to use the Spark executor job ID. Sometimes you may wish to set the name of the output file in a data flow text sink. This technique is only suggested for use with small files. The process of merging partition files into a single output file is a long-running process.
- Go back to the data flow designer and edit the data flow create above. Click on the sink transformation.
- Click Optimize > Set partitioning > Single partition. It is this single partition requirement that creates a bottleneck in the execution process as files are merged. This option is only recommended for small files.
- Click Settings > Name file as column data.
- Pick the column that you wish to use for generating file names.
- To manipulate the data values, or even if need to generate synthetic values for file names, use the Derived Column transformation to create the values you wish to use in your file names.
Related content
Learn more about data flow sinks.