Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article discusses how to update your Apache HBase cluster on Azure HDInsight to a newer version with a different Azure Storage account.
This article applies only if you need to use different Storage accounts for your source and destination clusters. To upgrade versions with the same Storage account for your source and destination clusters, see Migrate Apache HBase to a new version.
The downtime while upgrading can be more than 20 minutes. This downtime caused by the steps to flush all in-memory data, and wait for all procedure to complete and the time to configure and restart the services on the new cluster. Your results vary, depending on the number of nodes, amount of data, and other variables.
Review Apache HBase compatibility
Before upgrading Apache HBase, ensure the HBase versions on the source and destination clusters are compatible. Review the HBase version compatibility matrix and release notes in the HBase Reference Guide to make sure your application is compatible with the new version.
Here's an example compatibility matrix. Y indicates compatibility and N indicates a potential incompatibility:
| Compatibility type | Major version | Minor version | Patch |
|---|---|---|---|
| Client-Server wire compatibility | N | Y | Y |
| Server-Server compatibility | N | Y | Y |
| File format compatibility | N | Y | Y |
| Client API compatibility | N | Y | Y |
| Client binary compatibility | N | N | Y |
| Server-side limited API compatibility | |||
| Stable | N | Y | Y |
| Evolving | N | N | Y |
| Unstable | N | N | N |
| Dependency compatibility | N | Y | Y |
| Operational compatibility | N | N | Y |
The HBase version release notes should describe any breaking incompatibilities. Test your application in a cluster running the target version of HDInsight and HBase.
For more information about HDInsight versions and compatibility, see Azure HDInsight versions.
Apache HBase cluster migration overview
To upgrade and migrate your Apache HBase cluster on Azure HDInsight to a new storage account, you complete the following basic steps. For detailed instructions, see the detailed steps and commands.
Prepare the source cluster:
- Stop data ingestion.
- Check cluster health
- Stop replication if needed
- Flush
memstoredata. - Stop HBase.
- For clusters with accelerated writes, back up the Write Ahead Log (WAL) directory.
Prepare the destination cluster:
- Create the destination cluster.
- Stop HBase from Ambari.
- Clean Zookeeper data.
- Switch user to HBase.
Complete the migration:
- Clean the destination file system, migrate the data, and remove
/hbase/hbase.id. - Clean and migrate the WAL.
- Start all services from the Ambari destination cluster.
- Verify HBase.
- Delete the source cluster.
Detailed migration steps and commands
Use these detailed steps and commands to migrate your Apache HBase cluster with a new storage account.
Prepare the source cluster
Stop ingestion to the source HBase cluster.
Check Hbase hbck to verify cluster health
Verify HBCK Report page on HBase UI. Healthy cluster does not show any inconsistencies
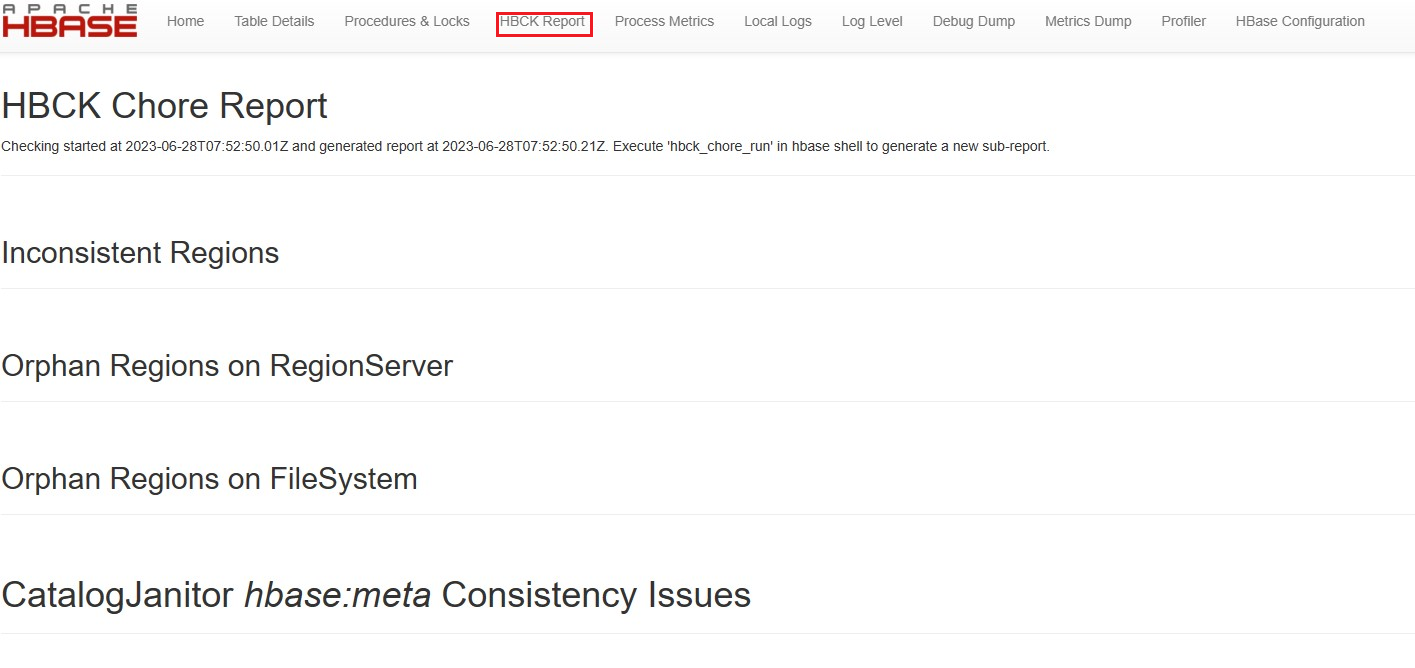
If any inconsistencies exist, please fix inconsistencies using hbase hbck2
Note down number of regions in online at source cluster, so that the number can be referred at destination cluster after the migration.
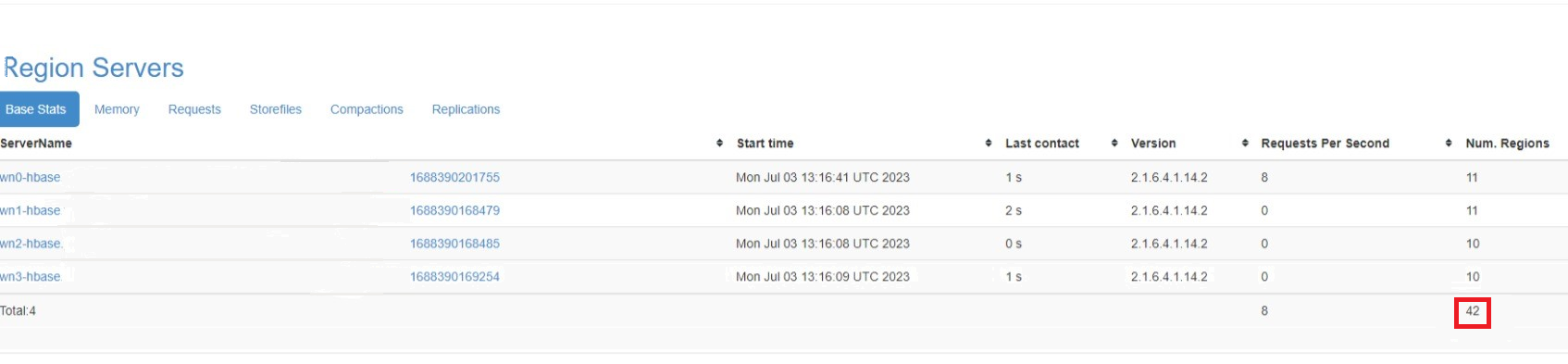
If replication enabled on the cluster, please stop it and reenable the replication on destination cluster after migration. Refer HBase replication guide
Flush the source HBase cluster you're upgrading.
HBase writes incoming data to an in-memory store called a
memstore. After thememstorereaches a certain size, HBase flushes it to disk for long-term storage in the cluster's storage account. Deleting the source cluster after an upgrade also deletes any data in thememstores. To retain the data, manually flush each table'smemstoreto disk before upgrading.You can flush the
memstoredata by running the flush_all_tables.sh script from the hbase-utils GitHub repository.You can also flush the
memstoredata by running the following HBase shell command from inside the HDInsight cluster:hbase shell flush "<table-name>"Wait for 15 mins and verify that all the procedures are completed, and masterProcWal files doesn't have any pending procedures.
Verify the Procedures page to confirm that there are no pending procedures.
STOP HBase
Sign in to Apache Ambari on the source cluster with
https://<OLDCLUSTERNAME>.azurehdinsight.cnTurn on maintenance mode for HBase.
Stop HBase Masters only first. First stop standby masters, in last stop Active HBase master.
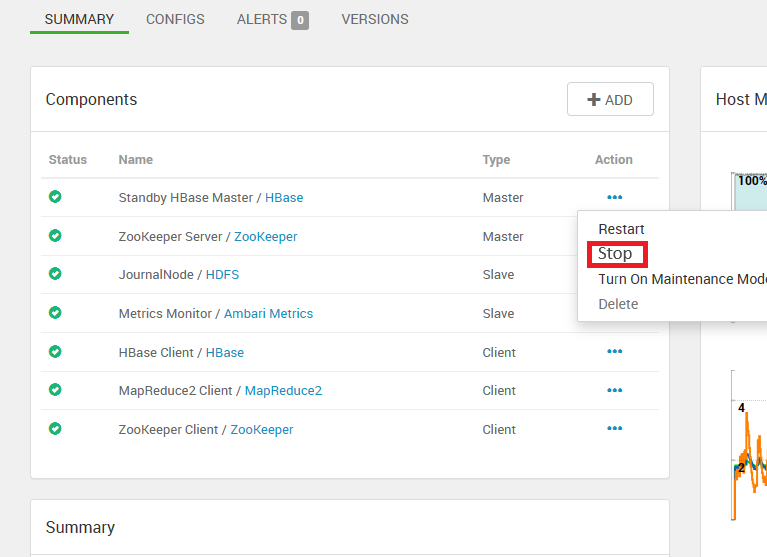
Stop the HBase service, it stops remaining servers.
Note
HBase 2.4.11 does not support some of the old Procedures.
For more information on connecting to and using Ambari, see Manage HDInsight clusters by using the Ambari Web UI.
Stopping HBase in the previous steps mentioned how Hbase avoids creating new master proc WALs.
If your source HBase cluster doesn't have the Accelerated Writes feature, skip this step. For source HBase clusters with Accelerated Writes, back up the WAL directory under HDFS by running the following commands from an SSH session on any source cluster Zookeeper node or worker node.
hdfs dfs -mkdir /hbase-wal-backup hdfs dfs -cp hdfs://mycluster/hbasewal /hbase-wal-backup




Prepare the destination cluster
In the Azure portal, set up a new destination HDInsight cluster that uses a different storage account than your source cluster.
Sign in to Apache Ambari on the new cluster at
https://<NEWCLUSTERNAME>.azurehdinsight.cn, and stop the HBase services.Clean the Zookeeper data on the destination cluster by running the following commands in any Zookeeper node or worker node:
hbase zkcli rmr /hbase-unsecure quitSwitch the user to HBase by running
sudo su hbase.
Clean and migrate the file system and WAL
Run the following commands, depending on your source HDInsight version and whether the source and destination clusters have Accelerated Writes. The destination cluster is always HDInsight version 4.0, since HDInsight 3.6 is in Basic support and isn't recommended for new clusters.
- The source cluster is HDInsight 4.0 with Accelerated Writes, and the destination cluster has Accelerated Writes.
- The source cluster is HDInsight 4.0 without Accelerated Writes, and the destination cluster has Accelerated Writes.
- The source cluster is HDInsight 4.0 without Accelerated Writes, and the destination cluster doesn't have Accelerated Writes.
The <container-endpoint-url> for the storage account is https://<storageaccount>.blob.core.chinacloudapi.cn/<container-name>. Pass the SAS token for the storage account at the very end of the URL.
- The
<container-fullpath>for storage type WASB iswasbs://<container-name>@<storageaccount>.blob.core.chinacloudapi.cn - The
<container-fullpath>for storage type Azure Data Lake Storage Gen2 isabfs://<container-name>@<storageaccount>.dfs.core.chinacloudapi.cn.
Copy commands
The HDFS copy command is hdfs dfs <copy properties starting with -D> -cp
Use hadoop distcp for better performance when copying files not in a page blob: hadoop distcp <copy properties starting with -D>
To pass the key of the storage account, use:
-Dfs.azure.account.key.<storageaccount>.blob.core.chinacloudapi.cn='<storage account key>'-Dfs.azure.account.keyprovider.<storageaccount>.blob.core.chinacloudapi.cn=org.apache.hadoop.fs.azure.SimpleKeyProvider
You can also use AzCopy for better performance when copying HBase data files.
Run the AzCopy command:
azcopy cp "<source-container-endpoint-url>/hbase" "<target-container-endpoint-url>" --recursiveIf the destination storage account is Azure Blob storage, do this step after the copy. If the destination storage account is Data Lake Storage Gen2, skip this step.
The Hadoop WASB driver uses special zero sized blobs corresponding to every directory. AzCopy skips these files when doing the copy. Some WASB operations use these blobs, so you must create them in the destination cluster. To create the blobs, run the following Hadoop command from any node in the destination cluster:
sudo -u hbase hadoop fs -chmod -R 0755 /hbase
You can download AzCopy from Get started with AzCopy. For more information about using AzCopy, see azcopy copy.
The source cluster is HDInsight 4.0 without Accelerated Writes, and the destination cluster has Accelerated Writes
To clean the file system and migrate data, run the following commands:
hdfs dfs -rm -r /hbase hadoop distcp <source-container-fullpath>/hbase /Remove
hbase.idby runninghdfs dfs -rm /hbase/hbase.idTo clean and migrate the WAL, run the following commands:
hdfs dfs -rm -r hdfs://<destination-cluster>/hbasewal hdfs dfs -Dfs.azure.page.blob.dir="/hbase-wals" -cp <source-container-fullpath>/hbase-wals hdfs://<destination-cluster>/hbasewal
The source cluster is HDInsight 4.0 without Accelerated Writes, and the destination cluster doesn't have Accelerated Writes
To clean the file system and migrate data, run the following commands:
hdfs dfs -rm -r /hbase hadoop distcp <source-container-fullpath>/hbase /Remove
hbase.idby runninghdfs dfs -rm /hbase/hbase.idTo clean and migrate the WAL, run the following commands:
hdfs dfs -rm -r /hbase-wals/* hdfs dfs -Dfs.azure.page.blob.dir="/hbase-wals" -cp <source-container-fullpath>/hbase-wals /
Complete the migration
On the destination cluster, save your changes and restart all required services as indicated by Ambari.
Point your application to the destination cluster.
Note
The static DNS name for your application changes when you upgrade. Rather than hard-coding this DNS name, you can configure a CNAME in your domain name's DNS settings that points to the cluster's name. Another option is to use a configuration file for your application that you can update without redeploying.
Start the ingestion.
Verify HBase consistency and simple Data Definition Language (DDL) and Data Manipulation Language (DML) operations.
If the destination cluster is satisfactory, delete the source cluster.
Troubleshooting
Use case 1:
If Hbase masters and region servers up and regions stuck in transition, or only one region i.e. hbase:meta region is assigned, and waiting for other regions to assign
Solution:
ssh into any ZooKeeper node of original cluster and run
kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<zk FQDN>if this is ESP clusterRun
echo scan hbase:meta| hbase shell > meta.outto read thehbase:metainto a fileRun
grep "info:sn" meta.out | awk '{print $4}' | sort | uniqto get all RS instance names where the regions were present in old cluster. Output should be likevalue=<wn FQDN>,16020,........Create a dummy WAL dir with that
wnvalueIf the cluster is accelerated write cluster
hdfs dfs -mkdir hdfs://mycluster/hbasewal/WALs/<wn FQDN>,16020,.........If the cluster is nonaccelarated Write cluster
hdfs dfs -mkdir /hbase-wals/WALs/<wn FQDN>,16020,.........Restart Active
Hmaster
Next steps
To learn more about Apache HBase and upgrading HDInsight clusters, see the following articles: