APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
In this article, you learn to manage resource usage in a deployment by configuring autoscaling based on metrics and schedules. The autoscale process lets you automatically run the right amount of resources to handle the load on your application.
Online endpoints in Azure Machine Learning support autoscaling through integration with the autoscale feature in Azure Monitor. For more information on autoscale settings from Azure Monitor, see Microsoft.Insights autoscalesettings.
Azure Monitor autoscale allows you to set rules that trigger one or more autoscale actions when conditions of the rules are met. You can base scaling on metrics such as CPU utilization, schedule such as peak business hours, or a combination of the two. For more information, see Overview of autoscale in Azure.

You can manage autoscaling by using REST APIs, Azure Resource Manager, Azure CLI v2, Python SDK v2, or the Azure portal via Azure Machine Learning studio.
Prerequisites
- An Azure Machine Learning workspace with a deployed endpoint. For more information, see Deploy and score a machine learning model by using an online endpoint.
- The Python SDK
azure-mgmt-monitor package installed by using pip install azure-mgmt-monitor.
- The
microsoft.insights/autoscalesettings/write permission assigned to the identity that manages autoscale, through any built-in or custom role that allow this action. For more information, see Manage users and roles.
Define an autoscale profile
To implement autoscale for an online endpoint, you enable autoscale settings and then define a default autoscale profile that specifies the minimum, maximum, and default scale set capacity. The following procedure enables autoscaling and sets the number of virtual machine (VM) instances for minimum, maximum, and default scale capacity.
If you didn't already set defaults for Azure CLI, run the following commands to avoid repeatedly specifying values for your subscription, workspace, and resource group.
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Set the endpoint and deployment names:
# set your existing endpoint name
ENDPOINT_NAME=your-endpoint-name
DEPLOYMENT_NAME=blue
- Get the Azure Resource Manager ID of the deployment and endpoint:
# ARM id of the deployment
DEPLOYMENT_RESOURCE_ID=$(az ml online-deployment show -e $ENDPOINT_NAME -n $DEPLOYMENT_NAME -o tsv --query "id")
# ARM id of the deployment. todo: change to --query "id"
ENDPOINT_RESOURCE_ID=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query "properties.\"azureml.onlineendpointid\"")
# set a unique name for autoscale settings for this deployment. The below will append a random number to make the name unique.
AUTOSCALE_SETTINGS_NAME=autoscale-$ENDPOINT_NAME-$DEPLOYMENT_NAME-`echo $RANDOM
- Create the autoscale profile:
az monitor autoscale create --name $AUTOSCALE_SETTINGS_NAME --resource $DEPLOYMENT_RESOURCE_ID --min-count 2 --max-count 5 --count 2
For more information, see the az monitor autoscale reference.
Import the necessary modules:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
from azure.mgmt.monitor import MonitorManagementClient
from azure.mgmt.monitor.models import AutoscaleProfile, ScaleRule, MetricTrigger, ScaleAction, Recurrence, RecurrentSchedule
import random
import datetime
Define variables for the workspace, endpoint, and deployment:
subscription_id = "<YOUR-SUBSCRIPTION-ID>"
resource_group = "<YOUR-RESOURCE-GROUP>"
workspace = "<YOUR-WORKSPACE>"
endpoint_name = "<YOUR-ENDPOINT-NAME>"
deployment_name = "blue"
Get Azure Machine Learning and Azure Monitor clients:
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.chinacloudapi.cn/.default")
except Exception:
credential = InteractiveBrowserCredential()
ml_client = MLClient(
credential, subscription_id, resource_group, workspace
)
mon_client = MonitorManagementClient(
credential, subscription_id
)
Get the endpoint and deployment objects:
deployment = ml_client.online_deployments.get(
deployment_name, endpoint_name
)
endpoint = ml_client.online_endpoints.get(
endpoint_name
)
Create the autoscale settings and a profile named my_scale_settings:
# Set a unique name for autoscale settings for this deployment. The following code appends a random number to create a unique name.
autoscale_settings_name = f"autoscale-{endpoint_name}-{deployment_name}-{random.randint(0,1000)}"
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = []
)
]
}
)
In your workspace in Azure Machine Learning studio, select Endpoints from the left menu.
Select the endpoint to configure from the list of available endpoints.
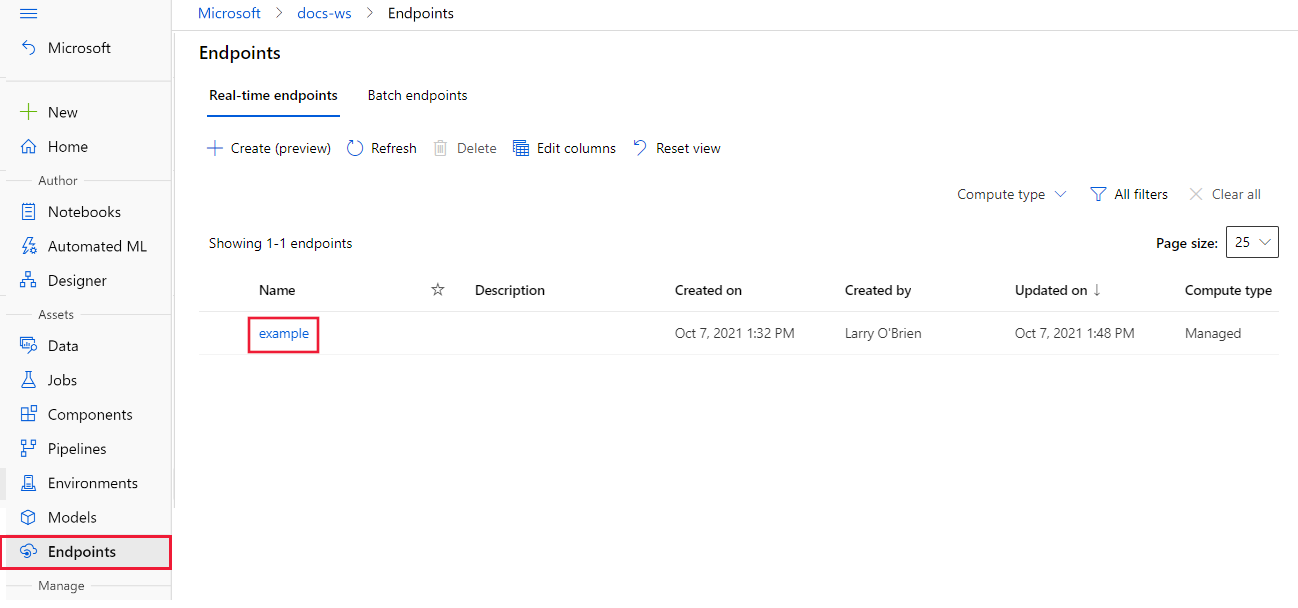
On the Details tab for the selected endpoint, scroll down and select the Configure auto scaling link under Scaling.
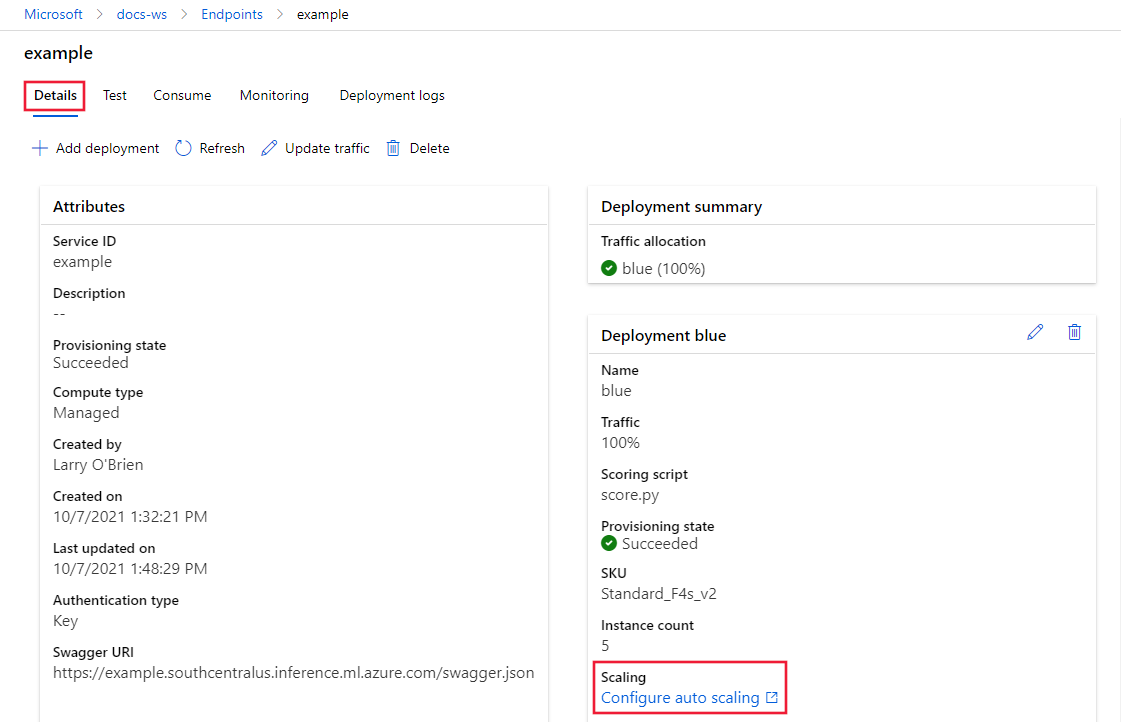
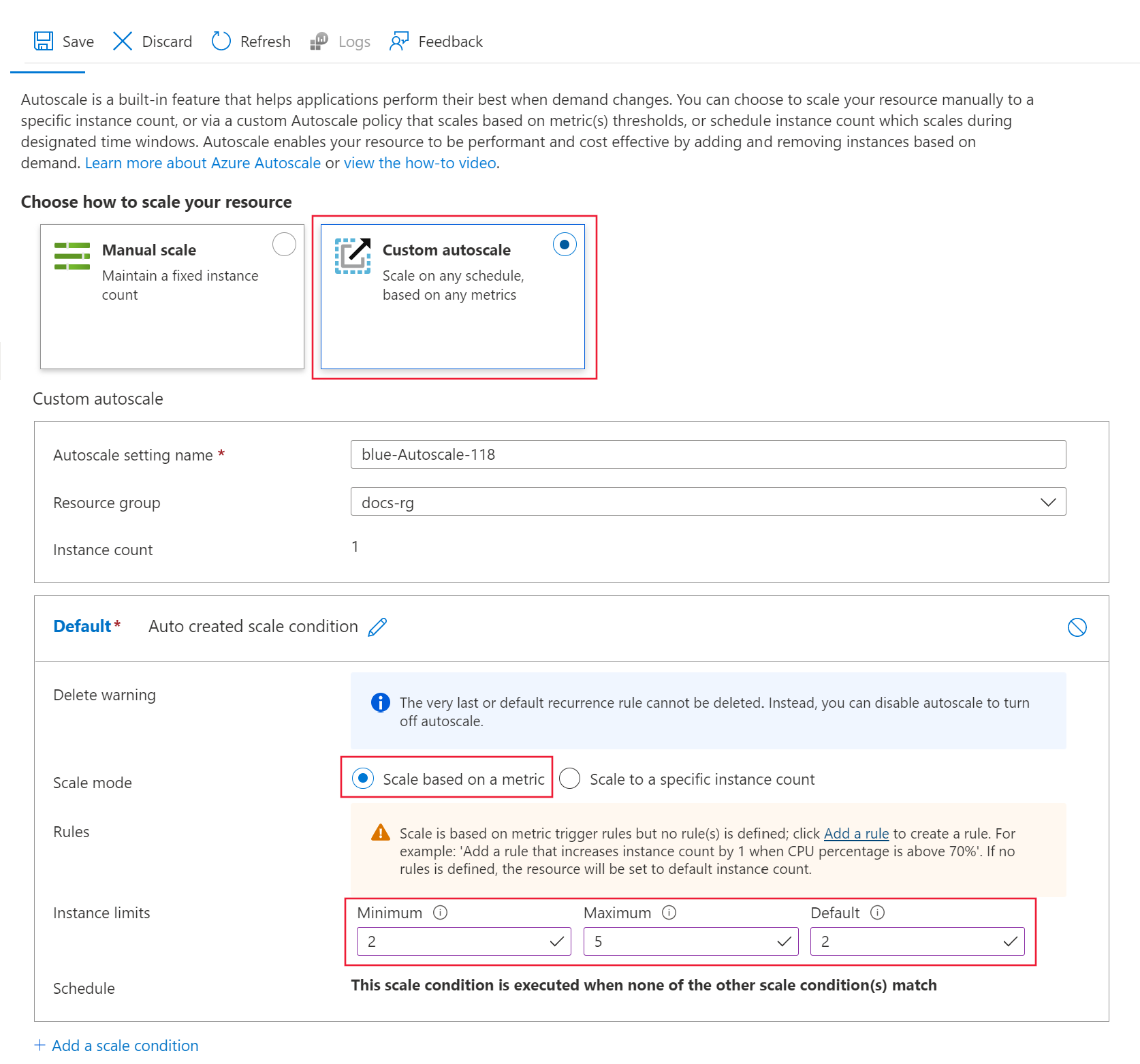
The Azure portal Scaling page for the deployment opens. On this page, select Custom autoscale under Choose how to scale your resources.
In the Default profile pane, select Scale based on a metric.
Under Instance limits, set Minimum to 2, Maximum to 5, and Default to 2.
Select Save at the top of the page.
Create a scale-out rule based on deployment metrics
A common scale-out rule increases the number of VM instances when the average CPU load is high. The following example shows how to allocate two more nodes, up to the maximum, if the CPU average load is greater than 70% for five minutes.
az monitor autoscale rule create --autoscale-name $AUTOSCALE_SETTINGS_NAME --condition "CpuUtilizationPercentage > 70 avg 5m" --scale out 2
The rule is part of the my-scale-settings profile, where autoscale-name matches the name portion of the profile. The value of the condition argument indicates that the rule triggers when the average CPU consumption among the VM instances exceeds 70% for five minutes. Autoscaling allocates two more VM instances when the condition is satisfied.
For more information, see the az monitor autoscale Azure CLI syntax reference.
Create the rule definition:
rule_scale_out = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="CpuUtilizationPercentage",
metric_resource_uri = deployment.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "GreaterThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 70
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 2,
cooldown = datetime.timedelta(hours = 1)
)
)
This rule refers to the last 5-minute average of the CPUUtilizationpercentage value from the arguments metric_name, time_window, and time_aggregation. When the value of the metric is greater than the threshold of 70, the deployment allocates two more VM instances.
Update the my-scale-settings profile to include this rule.
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out
]
)
]
}
)
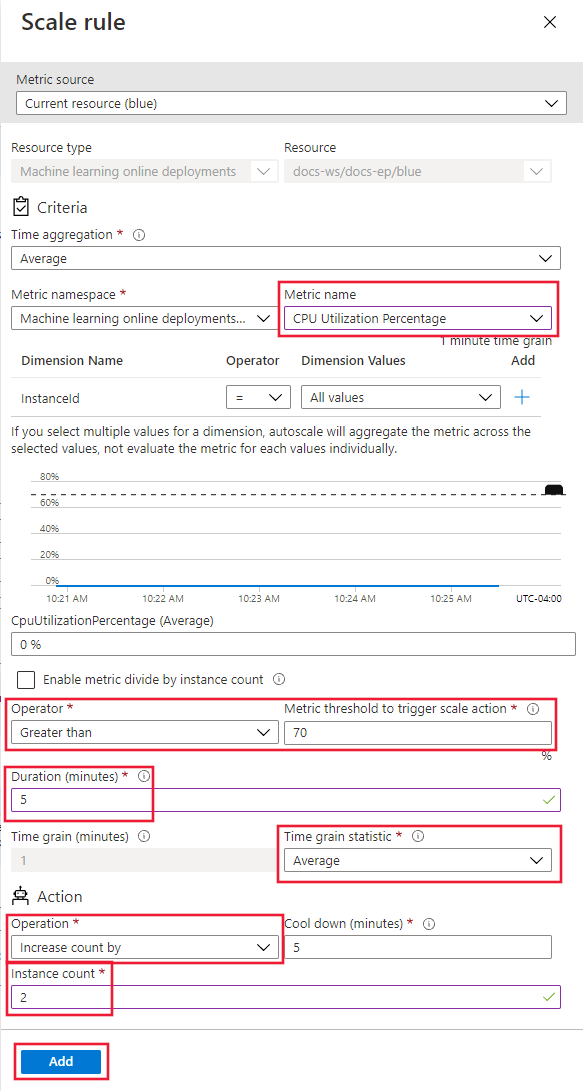
On the Scaling page Default profile, select the Add a rule link in the Rules section.
On the Scale rule page, configure the following values:
- Metric name: Select CPU Utilization Percentage.
- Operator: Select Greater than.
- Metric threshold: Set to 70.
- Duration (minutes): Set to 5.
- Time grain statistic: Select Average.
- Operation: Select Increase count by.
- Instance count: Set to 2.
Select Add.
On the Scaling page, select Save.
Create a scale-in rule based on deployment metrics
A scale-in rule can reduce the number of VM instances when the average CPU load is light. The following example shows how to release a single node, down to a minimum of two, if the CPU load is less than 30% for five minutes.
az monitor autoscale rule create --autoscale-name $AUTOSCALE_SETTINGS_NAME --condition "CpuUtilizationPercentage < 25 avg 5m" --scale in 1
Create the rule definition.
rule_scale_in = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="CpuUtilizationPercentage",
metric_resource_uri = deployment.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "LessThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 30
),
scale_action = ScaleAction(
direction = "Decrease",
type = "ChangeCount",
value = 1,
cooldown = datetime.timedelta(hours = 1)
)
)
Update the my-scale-settings profile to include this rule.
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out,
rule_scale_in
]
)
]
}
)
The following steps adjust the Rules configuration to support a scale in rule.
On the Azure portal Scaling page with Custom autoscale selected, select Scale based on a metric, and then select the Add a rule link.
On the Scale rule page, configure the following values:
- Metric name: Select CPU Utilization Percentage.
- Operator: Set to Less than.
- Metric threshold: Set to 30.
- Duration (minutes): Set to 5.
- Time grain statistic: Select Average.
- Operation: Select Decrease count by.
- Instance count: Set to 1.
Select Add.
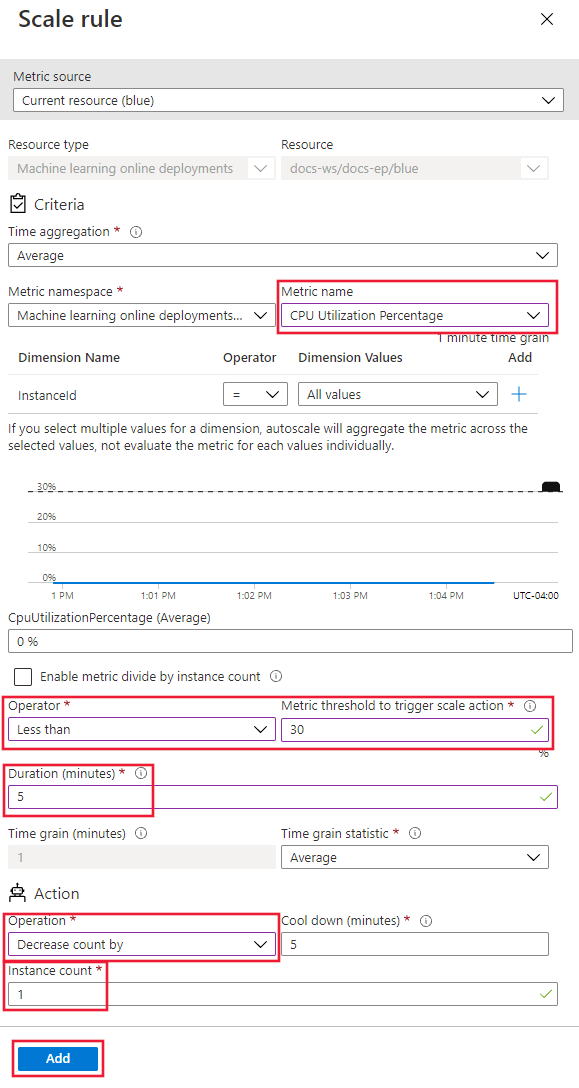
On the Scaling page, select Save.
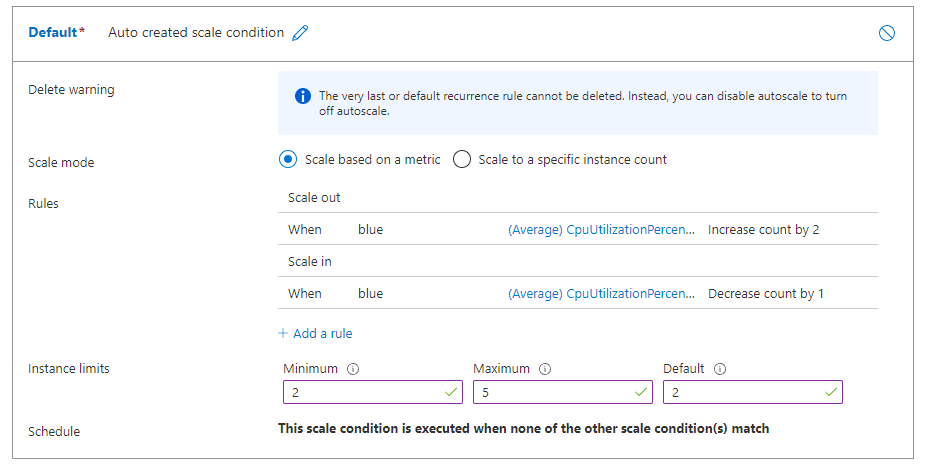
If you configure both scale-out and scale-in rules, your Rules for the Default profile look similar to the following screenshot. The rules specify that if average CPU load exceeds 70% for 5 minutes, two more nodes should be allocated, up to the limit of five. If CPU load is less than 30% for 5 minutes, a single node should be released, down to the minimum of two.
Create a scale rule based on endpoint metrics
In the preceding sections, you created rules to scale in or out based on deployment metrics. You can also create rules that apply to deployment endpoint metrics. For example, you can allocate another node when the request latency is greater than an average of 70 milliseconds for five minutes.
az monitor autoscale rule create --autoscale-name $AUTOSCALE_SETTINGS_NAME --condition "RequestLatency > 70 avg 5m" --scale out 1 --resource $ENDPOINT_RESOURCE_ID
Create the rule definition:
rule_scale_out_endpoint = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="RequestLatency",
metric_resource_uri = endpoint.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "GreaterThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 70
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 1,
cooldown = datetime.timedelta(hours = 1)
)
)
This rule's metric_resource_uri field now refers to the endpoint rather than the deployment.
Update the my-scale-settings profile to include this rule.
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out,
rule_scale_in,
rule_scale_out_endpoint
]
)
]
}
)
At the bottom of the Azure portal Scaling page with Custom autoscale selected, select the Add a scale condition link.
In the Profile section, select Scale based on a metric and then select the Add a rule link.
On the Scale rule page, configure the following values:
- Metric source: Select Other resource.
- Resource type: Select Machine Learning online endpoints.
- Resource: Select your endpoint.
- Metric name: Select Request latency.
- Operator: Set to Greater than.
- Metric threshold: Set to 70.
- Duration (minutes): Set to 5.
- Time grain statistic: Select Average.
- Operation: Select Increase count by.
- Instance count: Set to 1.
Select Add.
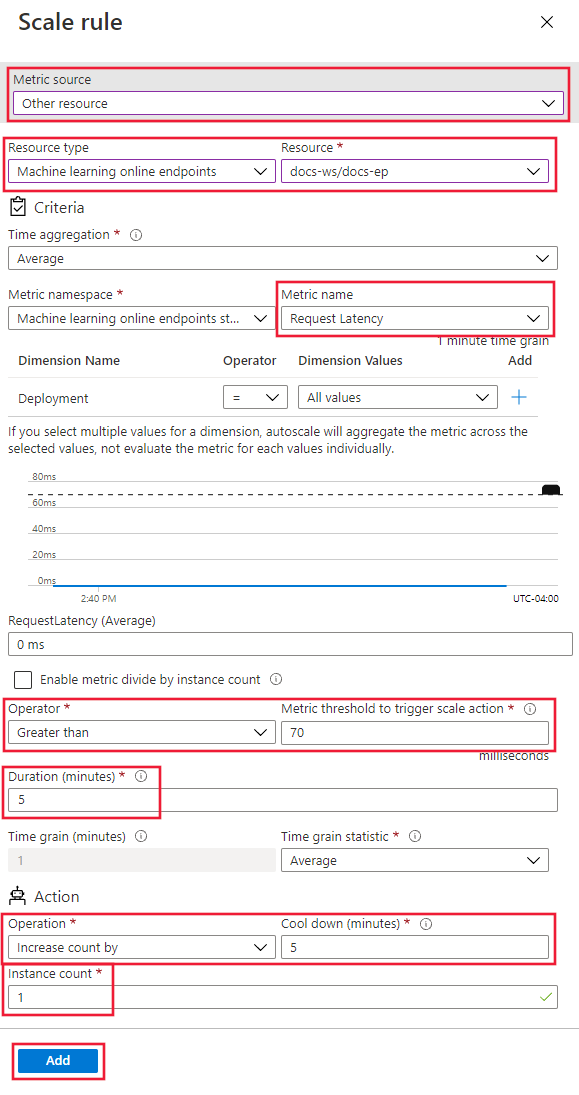
On the Scaling page, select Save.
Find other supported metrics
You can use other metrics when you set up autoscale rules.
Create a scale rule based on schedule
You can create autoscale rules that apply only on certain days or at certain times. For example, you can create a rule that sets the node count to two on weekends.
az monitor autoscale profile create --name weekend-profile --autoscale-name $AUTOSCALE_SETTINGS_NAME --min-count 2 --count 2 --max-count 2 --recurrence week sat sun --timezone "Pacific Standard Time"
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="Default",
capacity={
"minimum" : 2,
"maximum" : 2,
"default" : 2
},
rules=[],
recurrence = Recurrence(
frequency = "Week",
schedule = RecurrentSchedule(
time_zone = "Pacific Standard Time",
days = ["Saturday", "Sunday"],
hours = ["0"],
minutes = ["0"]
)
)
)
]
}
)
At the bottom of the Azure portal Scaling page with Custom autoscale selected, select Add a scale condition.
In the Profile section, select Scale to a specific instance count.
Set Instance count to 2.
For Schedule, select Repeat specific days.
For Repeat every, select Saturday and Sunday.

Select Save at the top of the Scaling page.
Enable or disable autoscale
You can enable or disable a specific autoscale profile.
az monitor autoscale update --autoscale-name $AUTOSCALE_SETTINGS_NAME --enabled false
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"enabled" : False
}
)
On the Azure portal Scaling page:
- To disable autoscale profiles in use, select Manual scale, and then select Save.
- To reenable the autoscale profiles, select Custom autoscale, and then select Save
Delete resources
The following commands delete both the autoscaling profile and the endpoint.
# delete the autoscaling profile
az monitor autoscale delete -n "$AUTOSCALE_SETTINGS_NAME"
# delete the endpoint
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
mon_client.autoscale_settings.delete(
resource_group,
autoscale_settings_name
)
ml_client.online_endpoints.begin_delete(endpoint_name)
Related content

