Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
With a Linked Service, you can connect to your instance of Azure Database for PostgreSQL flexible server and use it within Azure Data Factory and Synapse Analytics activities.
The Copy Activity supports Copy Command, Bulk Insert, and Upsert. For more information, see Copy and transform data in Azure Database for PostgreSQL using Azure Data Factory or Synapse Analytics.
The next section has a step-by-step guide on how to manually create a copy activity and how to create a pipeline.
Prerequisites
- An Azure Database for PostgreSQL flexible server instance. For more information, see Create an Azure Database for PostgreSQL.
- (Optional) An Azure integration runtime created within a managed virtual network.
- An Azure Data Factory Linked Service connected to Azure Database for PostgreSQL.
- An Azure Data Factory Dataset with your Azure Database for PostgreSQL.
Create a data copy activity via the portal
In Azure Data Factory Studio, select the Author hub. Hover over the Pipelines section, select ... at the left, and select New pipeline to create a new pipeline.
Under Move and transform, drag and drop the Copy data activity into the pipeline.
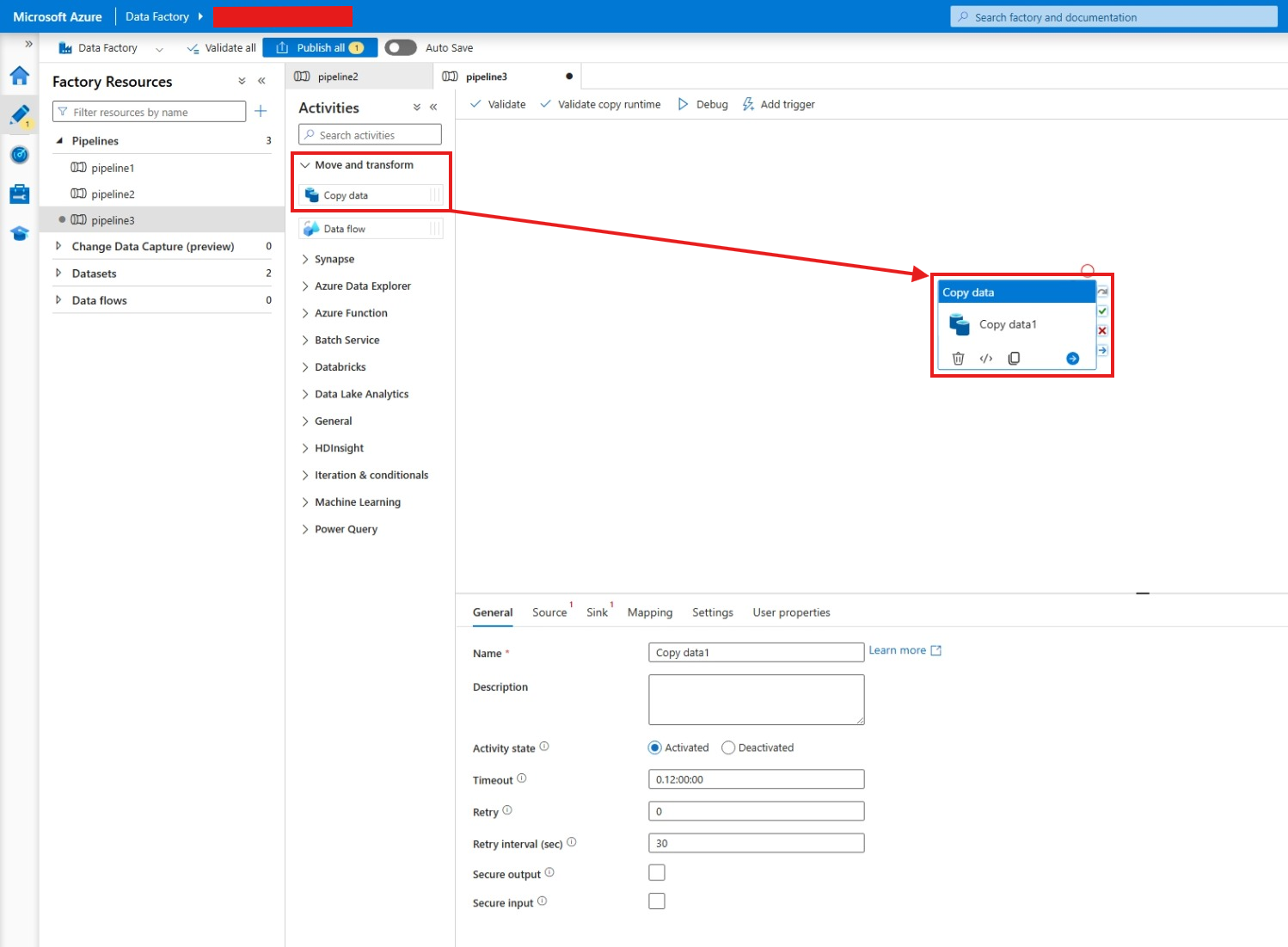
At the General tab, give a name to your pipeline.
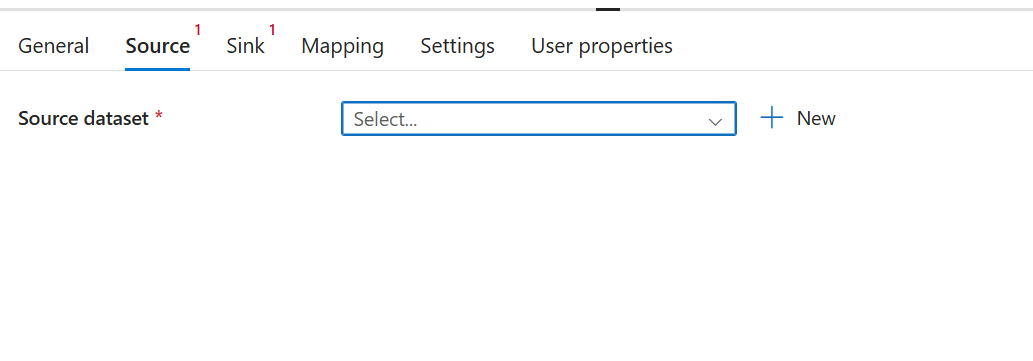
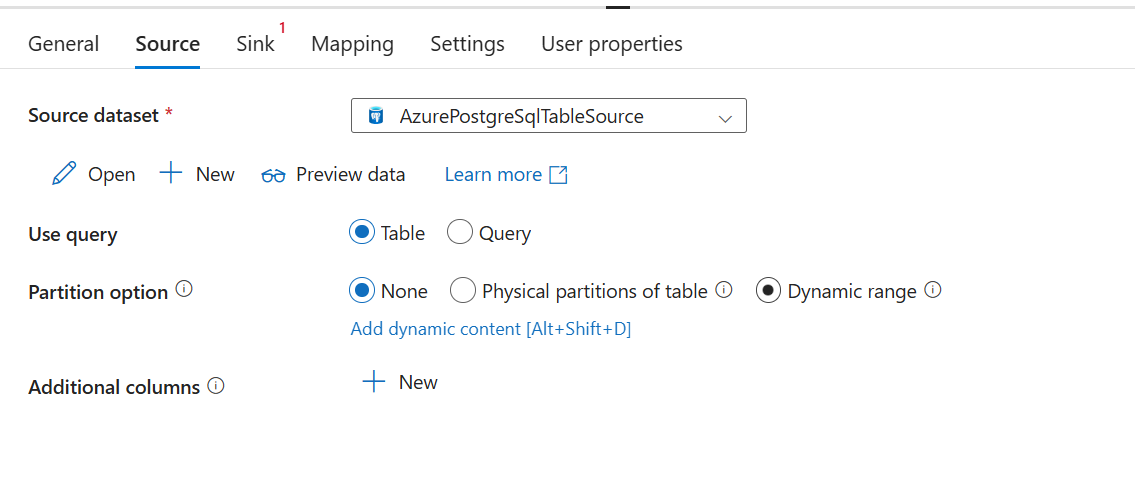
At the Source tab, select or create a Source dataset. In this example, select an Azure Database for PostgreSQL table.
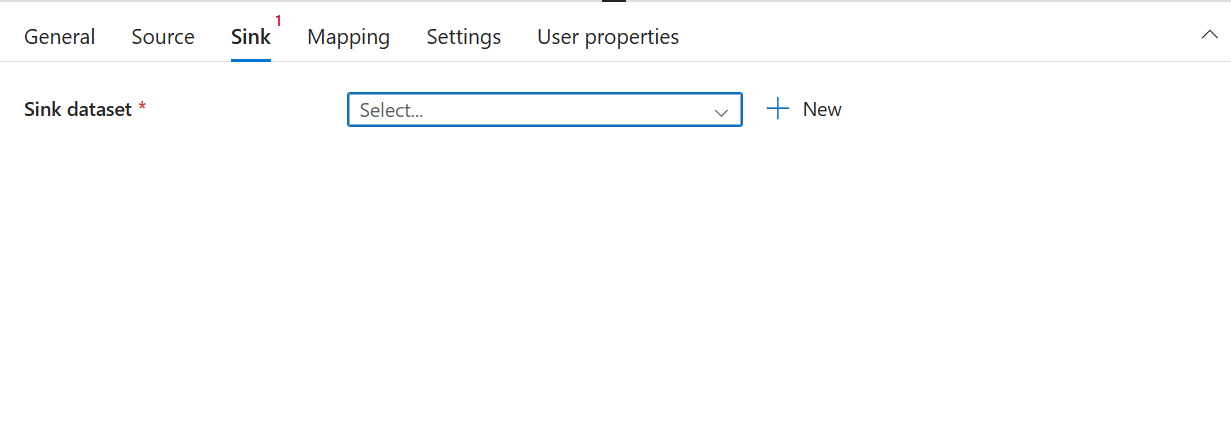
At the Sink tab, select or create an Azure Database for PostgreSQL dataset as Sink dataset, and choose the Write method. For more information, see Azure Copy Activity and Write Method.
Select between Copy command, Bulk insert, and Upsert for the Write method.
If a custom mapping is required, configure your mapping in the Mapping tab.
Validate your pipeline.
Select Debug to run the pipeline manually.
Set up a trigger for your pipeline.








For JSON payload examples, see Azure Database for PostgreSQL as sink.
Key columns behavior on upsert
When you upsert data with the Azure Database for PostgreSQL connector, you can specify optional fields called Key Columns.
 There are three acceptable ways to use the Key Columns:
There are three acceptable ways to use the Key Columns:
Select New and add all the primary key columns of the sink datasource table
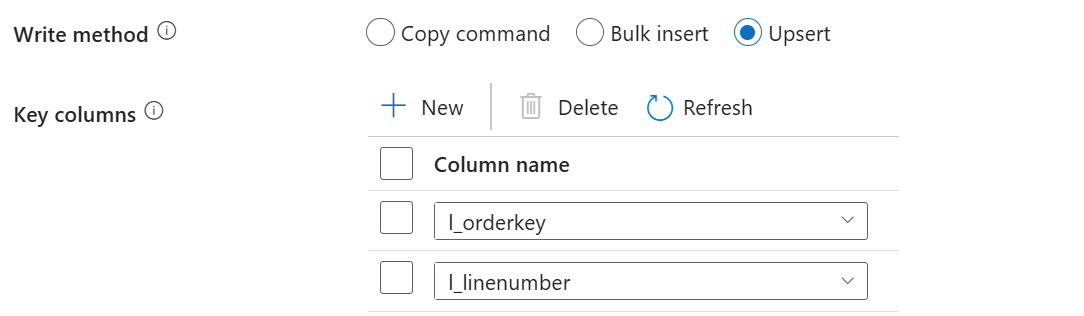
Select New and add one or more unique columns of the sink datasource table
Leave the Key columns empty. In this case, the connector finds the primary key columns and uses them as Key columns

