Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article illustrates common scenarios users have encountered in the area of monitoring and diagnostics with Service Fabric. The scenarios presented cover all three layers of service fabric: Application, Cluster, and Infrastructure. Each solution uses Application Insights and Azure Monitor logs, Azure monitoring tools, to complete each scenario. The steps in each solution give users an introduction on how to use Application Insights and Azure Monitor logs in the context of Service Fabric.
Warning
Application Insights for the Service Fabric SDK is no longer supported.
Prerequisites and Recommendations
The solutions in this article use the following tools. We recommend you have these set up and configured:
- Application Insights with Service Fabric
- Enable Azure Diagnostics on your cluster
- Set up a Log Analytics workspace
- Log Analytics agent to track Performance Counters
How can I see unhandled exceptions in my application?
Navigate to your Application Insights resource that your application is configured with.
Select Search in the top left. Then select filter on the next panel.
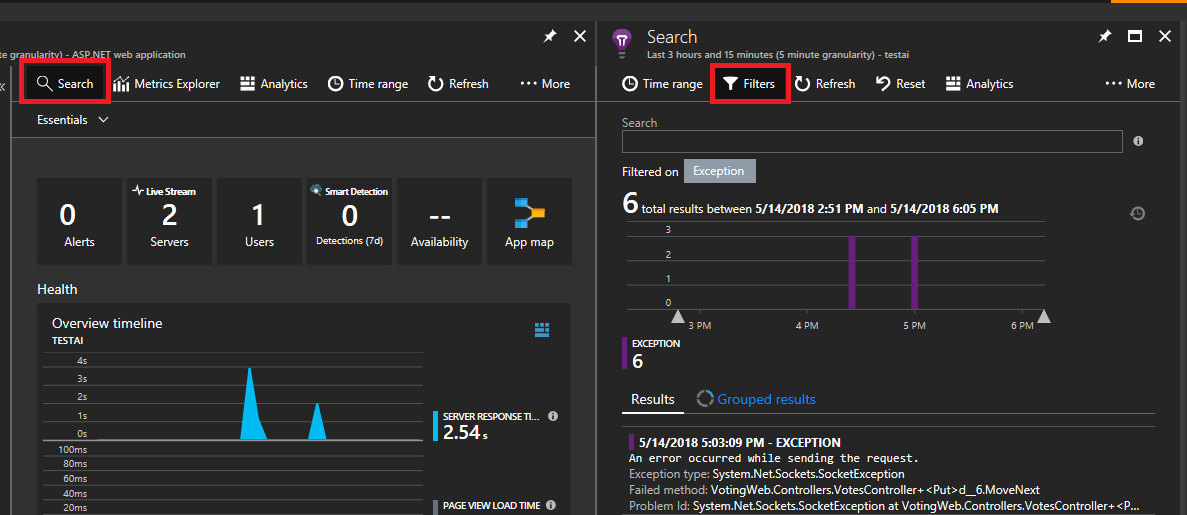
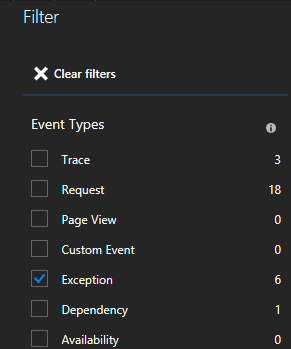
You will see lots of types of events (traces, requests, custom events). Choose "Exception" as your filter.
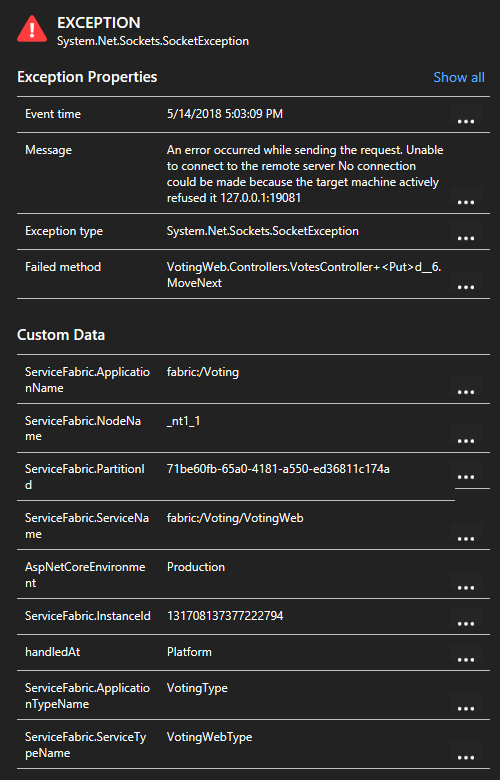
By clicking an exception in the list, you can look at more details including the service context if you're using the Service Fabric Application Insights SDK.
How do I view which HTTP calls are used in my services?
In the same Application Insights resource, you can filter on "requests" instead of exceptions and view all requests made
If you're using the Service Fabric Application Insights SDK, you can see a visual representation of your services connected to one another, and the number of succeeded and failed requests. On the left, select "Application Map"
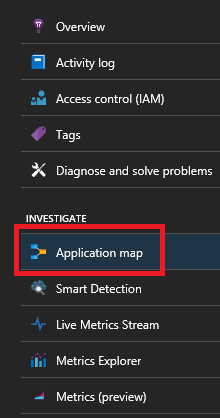
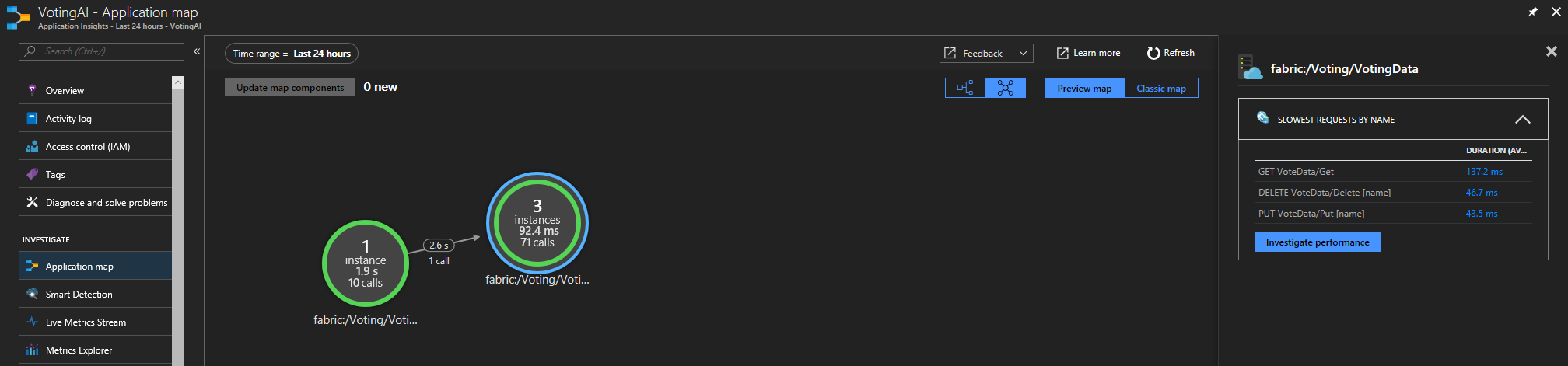
For more information on the application map, visit the Application Map documentation
How do I create an alert when a node goes down
Node events are tracked by your Service Fabric cluster. Navigate to the Service Fabric Analytics solution resource named ServiceFabric(NameofResourceGroup)
Select the graph on the bottom of the blade titled "Summary"
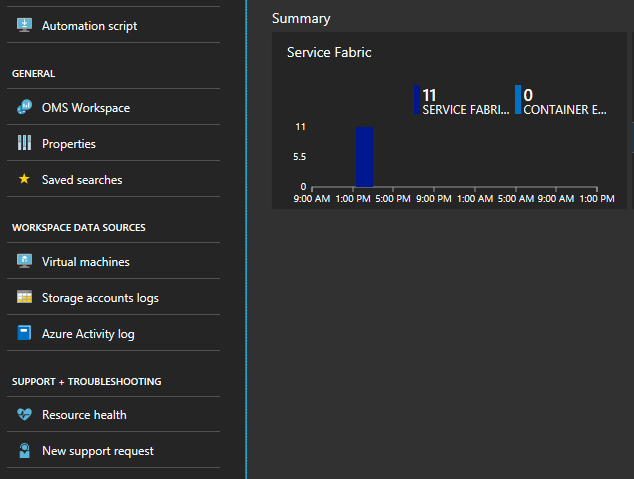
Here you have many graphs and tiles displaying various metrics. Select one of the graphs and it will take you to the Log Search. Here you can query for any cluster events or performance counters.
Enter the following query. These event IDs are found in the Node events reference
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626Select "New Alert Rule" at the top and now anytime an event arrives based on this query, you'll receive an alert in your chosen method of communication.
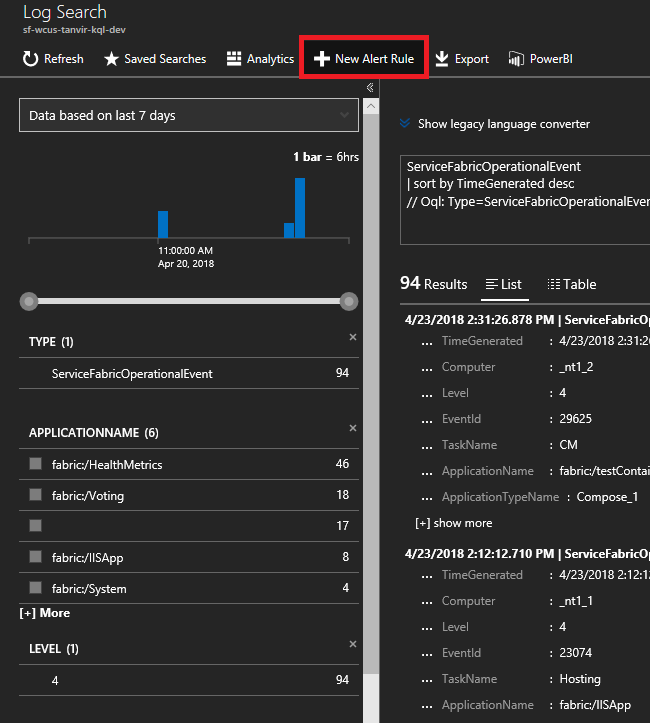
How can I be alerted of application upgrade rollbacks?
On the same Log Search window as before, enter the following query for upgrade rollbacks. These event IDs are found under Application events reference
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624Click "New Alert Rule" at the top and now anytime an event arrives based on this query, you will receive an alert.
How can I monitor performance counters?
Once you have added the Log Analytics agent to your cluster, you need to add the specific performance counters you want to track. Navigate to the Log Analytics workspace's page in the portal - from the solution's page the workspace tab is on the left menu.
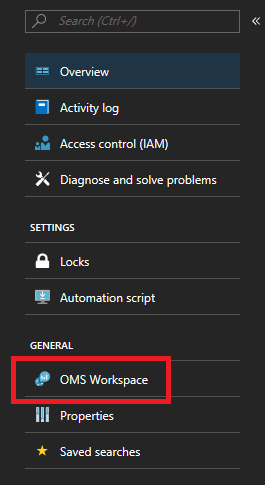
Once you're on the workspace's page, Select "Advanced settings" in the same left menu.
Select Data > Windows Performance Counters (Data > Linux Performance Counters for Linux machines) to start collecting specific counters from your nodes via the Log Analytics agent. Here are examples of the format for counters to add
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeIn the quickstart, VotingData and VotingWeb are the process names used, so tracking these counters would look like
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes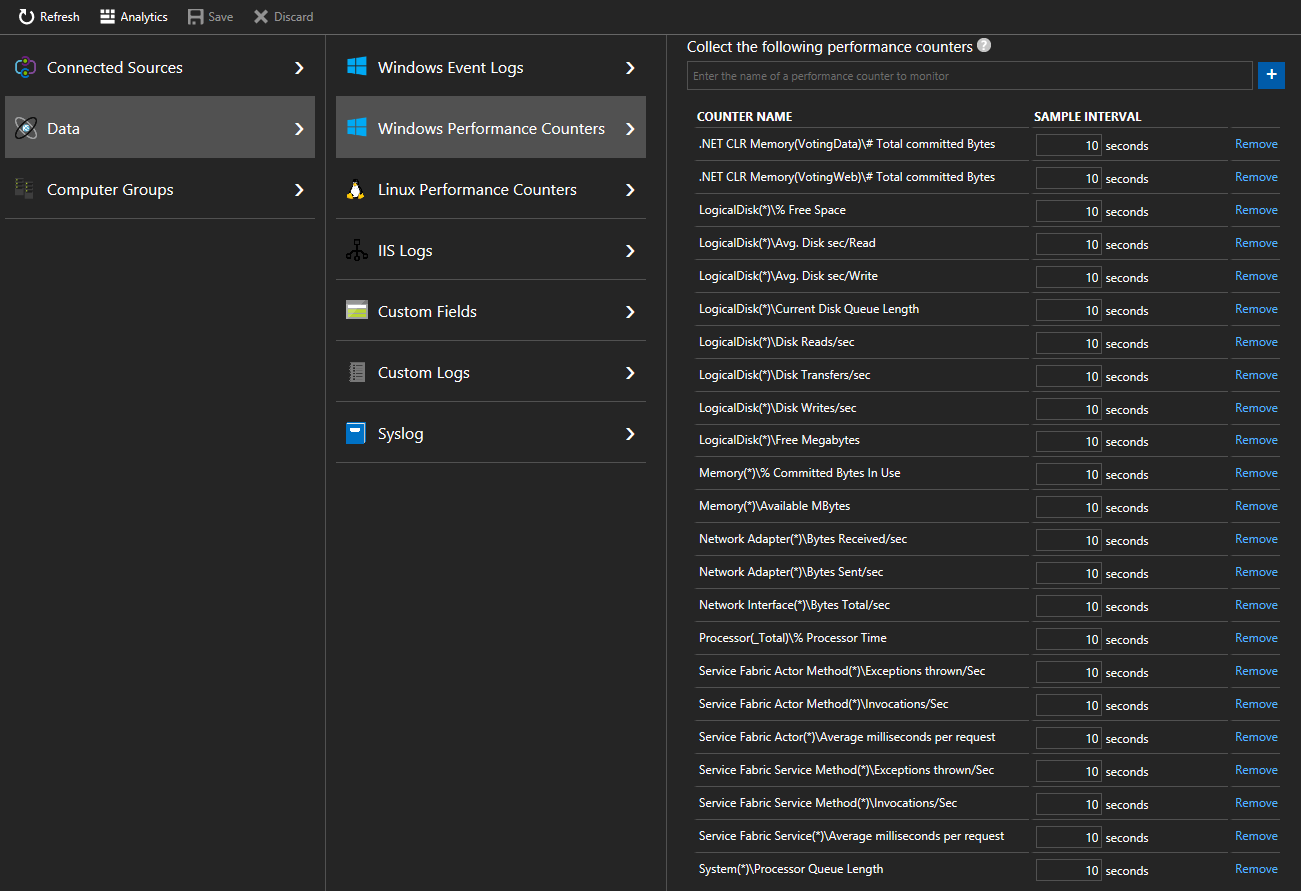
This allows you to see how your infrastructure is handling your workloads, and set relevant alerts based on resource utilization. For example - you might want to set an alert if the total Processor utilization goes above 90% or below 5%. The counter name you would use for this is "% Processor Time." You could do this by creating an alert rule for the following query:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
How do I track performance of my Reliable Services and Actors?
To track the performance of Reliable Services or Actors in your applications, you should collect the Service Fabric Actor, Actor Method, Service, and Service Method counters as well. Here are examples of reliable service and actor performance counters to collect
Note
Service Fabric performance counters cannot be collected by the Log Analytics agent currently, but can be collected by other diagnostic solutions
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Check these links for the full list of performance counters on Reliable Services and Actors
Next steps
- Look Up Common Code Package Activation Errors
- Set up Alerts in AI to be notified about changes in performance or usage
- Smart Detection in Application Insights performs a proactive analysis of the telemetry being sent to AI to warn you of potential performance problems
- Learn more about Azure Monitor logs alerting to aid in detection and diagnostics.
- For on-premises clusters, Azure Monitor logs offers a gateway (HTTP Forward Proxy) that can be used to send data to Azure Monitor logs. Read more about that in Connecting computers without Internet access to Azure Monitor logs using the Log Analytics gateway
- Get familiarized with the log search and querying features offered as part of Azure Monitor logs
- Get a more detailed overview of Azure Monitor logs and what it offers, read What is Azure Monitor logs?