Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Cloud tiering, an optional feature of Azure File Sync, decreases the amount of local storage required while keeping the performance of an on-premises file server.
When you enable this feature, it stores only frequently accessed (hot) files on your local server. Infrequently accessed (cool) files are split into namespace (file and folder structure) and file content. The namespace is stored locally, and the file content is stored in an Azure file share in the cloud.
When a user opens a tiered file, Azure File Sync seamlessly recalls the file data from the Azure file share.
How cloud tiering works
Cloud tiering works by monitoring file access patterns and tiering files based on defined policies.
Cloud tiering policies
When you enable cloud tiering, there are two policies that you can set to inform Azure File Sync when to tier cool files: the volume free space policy and the date policy.
Volume free space policy
The volume free space policy tells Azure File Sync to tier cool files to the cloud when a certain amount of space is taken up on your local disk.
For example, if your local disk capacity is 200 GiB and you want at least 40 GiB of your local disk capacity to always remain free, set the volume free space policy to 20%. Volume free space applies at the volume level rather than at the level of individual directories or server endpoints.
Date policy
With the date policy, cool files are tiered to the cloud if they haven't been accessed (read or written to) for x number of days. For example, if you notice that files that have gone more than 15 days without being accessed are typically archival files, you should set your date policy to 15 days.
For more examples on how the date policy and volume free space policy work together, see Choose Azure File Sync cloud tiering policies.
Windows Server data deduplication
Starting with Windows Server 2016, data deduplication is supported on volumes that have cloud tiering enabled. For more information, see Plan for an Azure File Sync deployment.
Cloud tiering heatmap
Azure File Sync monitors file access (read and write operations) over time and assigns a heat score to every file based on how recently and frequently the file is accessed. It uses these scores to build a "heatmap" of your namespace on each server endpoint. This heatmap is a list of all syncing files in a location with cloud tiering enabled, ordered by their heat score. Frequently accessed files that were recently opened are considered hot, while files that were rarely accessed and haven't been accessed for some time are considered cool.
To determine the relative position of an individual file in that heatmap, the system uses the maximum of its timestamps, in the following order: MAX (Last Access Time, Last Modified Time, Creation Time).
Typically, last access time is tracked and available. However, when you create a new server endpoint with cloud tiering enabled, not enough time has passed to observe file access. If there's no valid last access time, the last modified time is used instead, to evaluate the relative position in the heatmap.
The date policy works the same way. Without a last access time, the date policy acts on the last modified time. If that's unavailable, it falls back to the create time of a file. Over time, the system observes more file access requests and automatically starts to use the self-tracked last access time.
Note
Cloud tiering doesn't depend on the NTFS feature for tracking last access time. This NTFS feature is off by default. Due to performance considerations, we don't recommend that you manually enable this feature. Cloud tiering tracks last access time separately.
Considerations for choosing a cloud tiering policy
Cold files that are accessed less frequently are best suited to be tiered files, as recalling data requires downloading from the cloud. Azure File Sync reserves 10% of total memory for persisting recalls to the disk. If 60% of this reserved memory is in use, the recalls aren't persisted to the disk. If a large number of tiered files are present on the system and a lot of access takes place, the system might hit a memory threshold. This situation can cause unexpected extra egress, I/O performance degradation, system slowness, and hangs.
Proactive recall
When a file is created or modified, you can proactively recall the file to servers that you specify. Proactive recall makes the new or modified file readily available for consumption in each specified server.
If files recalled to the server aren't needed locally, the unnecessary recall can increase your egress traffic and costs. Therefore, only enable proactive recall when you know that prepopulating a server's cache with recent changes from the cloud will have a positive effect on users or applications using the files on that server.
Enabling proactive recall might also result in increased bandwidth usage on the server and could cause other relatively new content on the local server to be aggressively tiered due to the increase in files being recalled. In turn, tiering too soon might lead to more recalls if the files being tiered are considered hot by servers.
For more information on proactive recall, see Deploy Azure File Sync.
Tiered vs. locally cached file behavior
Cloud tiering is the separation between namespace (the file and folder hierarchy as well as file properties) and the file content.
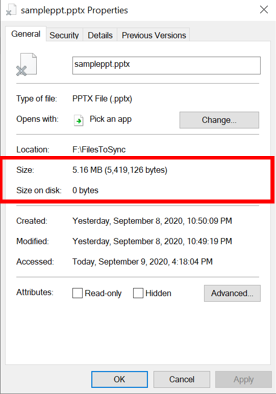
Tiered file
For tiered files, the size on disk is zero because the file content itself isn't being stored locally. When a file is tiered, the Azure File Sync file system filter (StorageSync.sys) replaces the file locally with a pointer called a reparse point. The reparse point represents a URL to the file in the Azure file share. A tiered file has both the offline attribute and the FILE_ATTRIBUTE_RECALL_ON_DATA_ACCESS attribute set in NTFS so that third-party applications can securely identify tiered files.
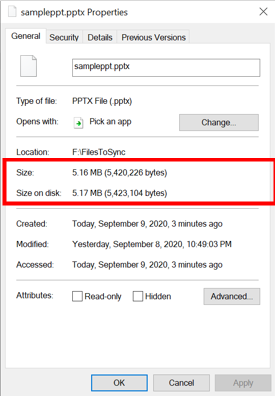
Locally cached file
For files stored in an on-premises file server, the size on disk is about equal to the logical size of the file, because the entire file (file attributes and file content) is stored locally.
It's also possible for a file to be partially tiered or partially recalled. In a partially tiered file, only part of the file is stored on disk. You might have partially recalled files on your volume if files are partially read by applications that support streaming access to files. Some examples are multimedia players and zip utilities. Azure File Sync is efficient and recalls only the requested information from the connected Azure file share.
Note
Size represents the logical size of the file. Size on disk represents the physical size of the file stream that's stored on the disk.
Low disk space mode
Disks that have server endpoints can run out of space for various reasons, even when cloud tiering is enabled. These reasons include:
- Manually copying data to the disk outside of the server endpoint path
- Slow or delayed sync causing files not to be tiered
- Excessive recalls of tiered files
When the disk space runs out, Azure File Sync might not function correctly and can even become unusable. While Azure File Sync can't completely prevent these occurrences, the low disk space mode (available in Azure File Sync agent versions starting from 15.1) helps prevent a server endpoint from reaching this situation and helps the server get out of it faster.
For server endpoints with cloud tiering enabled, if the free space on the volume drops below the calculated threshold, the volume enters low disk space mode.
In low disk space mode, the Azure File Sync agent does two things differently:
Proactive tiering: The File Sync agent tiers files more proactively to the cloud. The sync agent checks for files to tier every minute instead of the normal frequency of every hour. Volume free space policy tiering typically doesn't happen during initial upload sync until the full upload is complete. However, in low disk space mode, tiering is enabled during the initial upload sync, and files are considered for tiering once the individual file is uploaded to the Azure file share.
Non-persistent recalls: When a user opens a tiered file, files recalled from the Azure file share directly aren't persisted to the disk. Recalls initiated by the
Invoke-StorageSyncFileRecallcmdlet are an exception to this rule and are persisted to disk.
When the volume free space surpasses the threshold, Azure File Sync automatically reverts to the normal state. Low disk space mode only applies to servers with cloud tiering enabled and always respects the volume free space policy.
If a volume has two server endpoints, one with tiering enabled and one without tiering, low disk space mode only applies to the server endpoint where tiering is enabled.
How is the threshold for low disk space mode calculated?
Calculate the threshold by taking the minimum of the following three numbers:
- 10% of volume size in GiB
- Volume Free Space Policy in GiB
- 20 GiB
The following table includes some examples of how the threshold is calculated and when the volume is in low disk space mode.
| Volume Size | 10% of Volume Size | Volume Free Space Policy | Threshold = Min (10% of Volume Size, Volume Free Space Policy, 20 GiB) | Current Volume Free Space | Is Low Disk Space Mode? | Reason |
|---|---|---|---|---|---|---|
| 100 GiB | 10 GiB | 7% (7 GiB) | 7 GiB = Min (10 GiB, 7 GiB, 20 GiB) | 9% (9 GiB) | No | Current Volume Free Space (9 GiB) > Threshold (7 GiB) |
| 100 GiB | 10 GiB | 7% (7 GiB) | 7 GiB = Min (10 GiB, 7 GiB, 20 GiB) | 5% (5 GiB) | Yes | Current Volume Free Space (5 GiB) < Threshold (7 GiB) |
| 300 GiB | 30 GiB | 8% (24 GiB) | 20 GiB = Min (30 GiB, 24 GiB, 20 GiB) | 7% (21 GiB) | No | Current Volume Free Space (21 GiB) > Threshold (20 GiB) |
| 300 GiB | 30 GiB | 8% (24 GiB) | 20 GiB = Min (30 GiB, 24 GiB, 20 GiB) | 6% (18 GiB) | Yes | Current Volume Free Space (18 GiB) < Threshold (20 GiB) |
How does low disk space mode work with volume free space policy?
Low disk space mode always respects the volume free space policy. The threshold calculation is designed to make sure it respects the volume free space policy that you set.
What is the most common cause for server endpoint being in low disk mode?
The primary cause of low disk mode is copying or moving large amounts of data to the disk where a tiering-enabled server endpoint is located.
How do I get out of low disk space mode?
Low disk mode automatically switches to normal behavior by not persisting recalls and tiering files more frequently, without requiring any intervention. You can manually speed up the process by increasing the volume size or freeing up space outside the server endpoint.
How can I check if a server is in low disk space mode?
- If a server endpoint is in low disk space mode, the Azure portal displays it in the cloud tiering health section of the Errors + troubleshooting tab of the server endpoint.
- Event ID 19000 is logged to the Telemetry event log every minute for each server endpoint. Use this event to determine if the server endpoint is in low disk space mode (IsLowDiskMode = true). You can find the Telemetry event log in Event Viewer under
Applications and Services\Microsoft\FileSync\Agent.