Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
此内容适用于:![]() v4.0 (GA) | 早期版本:
v4.0 (GA) | 早期版本:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0(停用)
v3.0(停用)
自定义分类模型会对输入文件的每一页分类,以识别其中的一个或更多文档。 分类器模型还可识别输入文件中多个文档或单个文档的多个实例。 文档智能自定义模型仅需每个文档类别提供五个训练文档即可开始使用。 若要训练自定义分类模型,需要每个类至少有五个文档以及两类文档。
自定义分类模型输入要求
请确保训练数据集符合文档智能的输入要求。
支持以下文件格式。
| 型号 | 图片: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Office: Word(DOCX)、Excel(XLSX)、PowerPoint(PPTX)、HTML |
|
|---|---|---|---|
| 读取 | ✔ | ✔ | ✔ |
| 版式 | ✔ | ✔ | ✔ |
| 常规文档 | ✔ | ✔ | |
| 预构建 | ✔ | ✔ | |
| 自定义提取 | ✔ | ✔ | |
| 自定义分类 | ✔ | ✔ | ✔ |
- 照片和扫描:为获得最佳结果,请为每个文档提供一张清晰的照片或高质量的扫描。
- PDF 和 TIFF:对于 PDF 和 TIFF,最多可以处理 2,000 页。 (使用免费层订阅时,只处理前两个页面。
- 文件大小:用于分析文档的文件大小是付费层 (S0) 层的 500 MB,免费层为 4 MB(F0) 层。
- 图像尺寸:尺寸必须介于 50 像素 x 50 像素和 10,000 像素 x 10,000 像素之间。
- 密码锁:如果 PDF 是密码锁定的,则必须在提交之前删除该锁。
- 文本高度:要提取的文本的最小高度是 1024 x 768 像素图像的 12 像素。 此尺寸对应于 8 点大约文本,即每英寸 150 点。
- 自定义模型训练:自定义模板模型的最大训练页数为 500,自定义神经模型为 50,000。
- 自定义提取模型训练:对于模板模型,训练数据的总大小为 50 MB,神经网络模型为 1 GB。
- 自定义分类模型训练:训练数据的总大小为 1 GB,最大为 10,000 页。 对于 2024-11-30(GA),训练数据的总大小为 2 GB,最大为 10,000 页。
- Office 文件类型(DOCX、XLSX、PPTX):最大字符串长度限制为 800 万个字符。
训练数据提示
请按照以下提示来进一步优化用于训练的数据集:
如果可以,请使用基于文本的 PDF 文档而不是基于图像的文档。 扫描的 PDF 作为图像处理。
如果表单图像质量较低,请使用较大的数据集(例如 10-15 张图像)。
上传训练数据
在将用于训练的表单集或文档集放到一起后,需要将其上传到 Azure Blob 存储容器。 如果不知道如何使用容器创建 Azure 存储帐户,请按照 Azure 门户的 Azure 存储快速入门中的说明操作。 可以使用免费定价层 (F0) 试用该服务,然后再升级到付费层进行生产。 如果数据集整理成了文件夹,请保留该结构,因为 Studio 可以使用标签的文件夹名来简化标记过程。
在文档智能工作室中创建分类项目
Document Intelligence Studio 提供和协调完成数据集和训练模型所需的 API 调用。
首先,导航到“文档智能工作室”。 首次使用此 Studio 时,需要初始化订阅、资源组和资源。 然后,按照自定义项目的先决条件的说明将工作室配置为可以访问你的训练数据集。
在工作室中,选择页面中自定义模型部分的“自定义分类模型”图块,然后选择“创建项目”按钮。
在
Create Project对话框中,提供项目的名称,还可以选择是否提供说明,然后选择“继续”。接下来,选择或创建文档智能资源,然后继续。
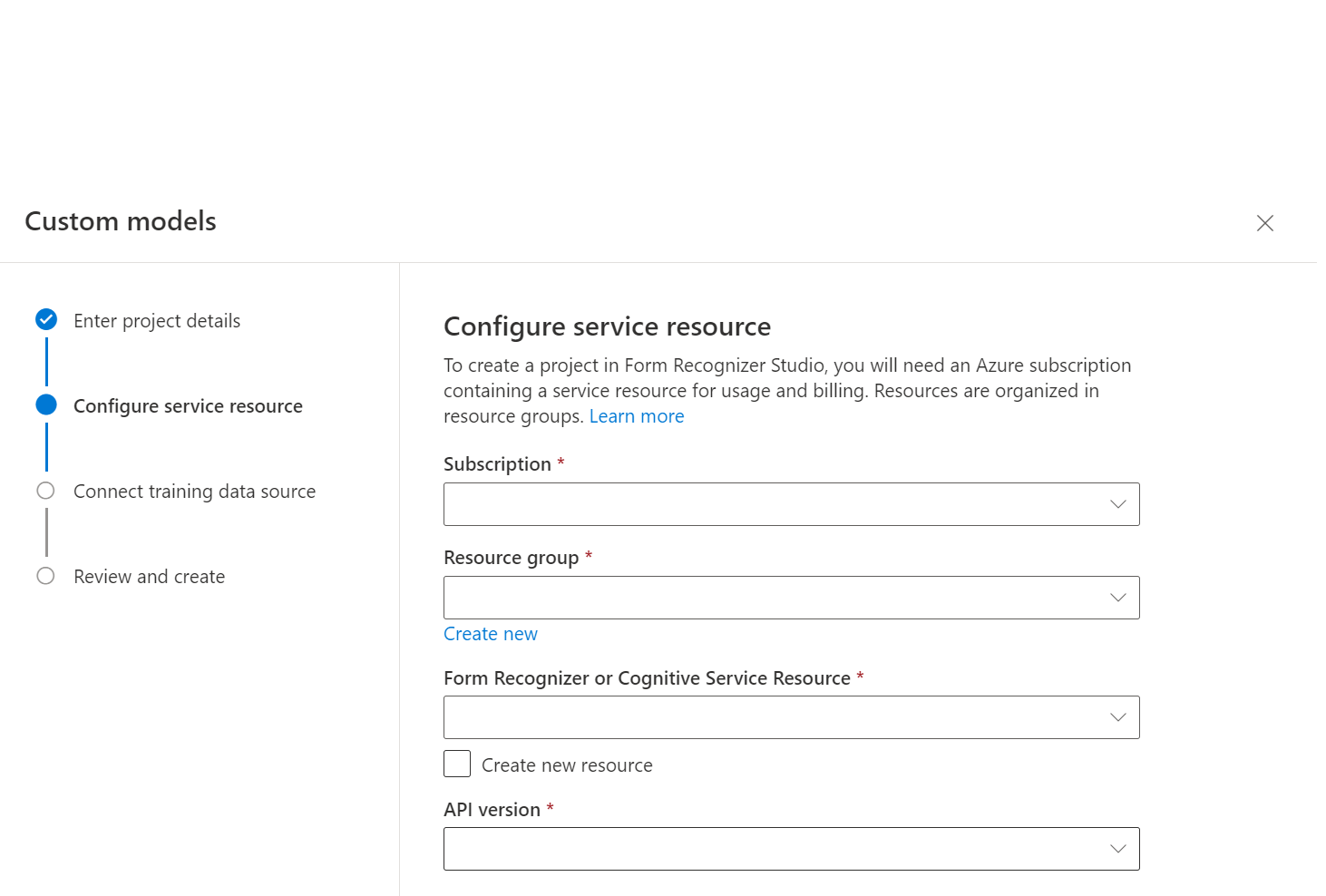
接下来,选择用于上传了自定义模型训练数据集的存储帐户。 如果训练文档位于容器的根目录,那么,“文件夹路径”中就应该是空的。 如果文档位于子文件夹中,请在“文件夹路径”字段中输入容器根目录中的相对路径。 在配置了存储帐户后,选择“继续”。
重要
可以按文件夹名称是文档的标签或类的文件夹来组织训练数据集。 或者,可以创建可在 Studio 中分配标签的文档平面列表。
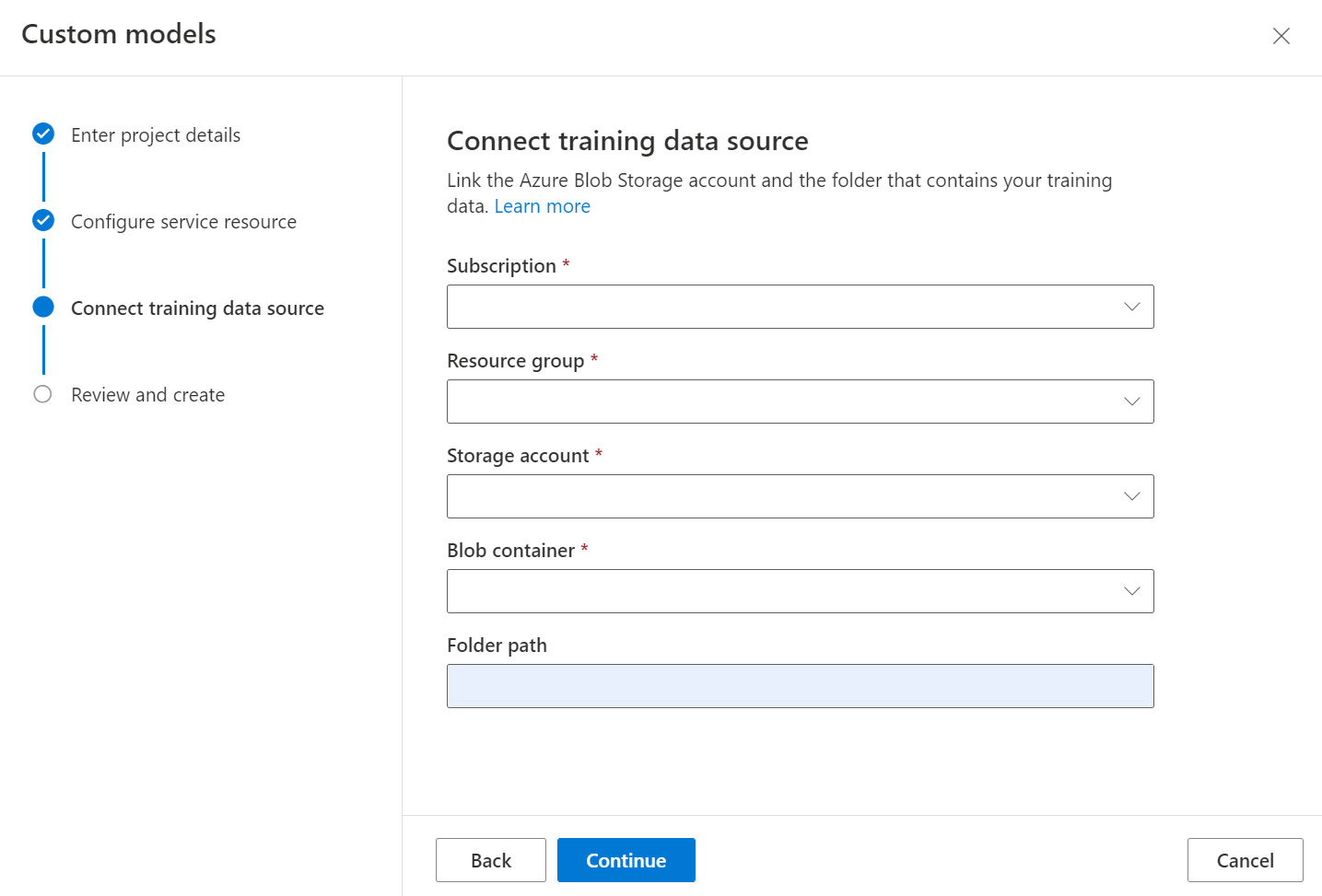
训练自定义分类器需要来自数据集中每个文档的布局模型的输出。 在模型训练前,对所有文档进行版面分析。
最后,查看项目设置,然后选择“创建项目”,以创建新项目。 现在,应该会出现标记窗口,并且可以看到列出了你的数据集中的文件。
标记数据
在项目中,只需使用相应的类标签标记每个文档。
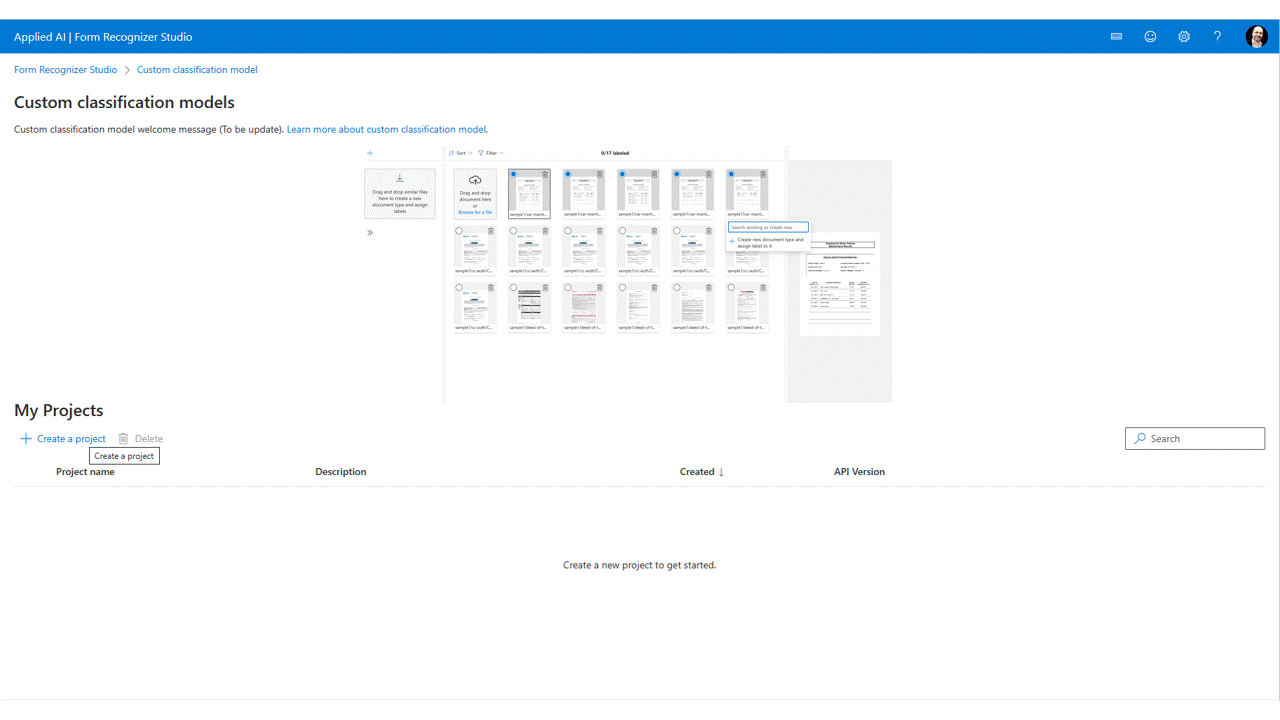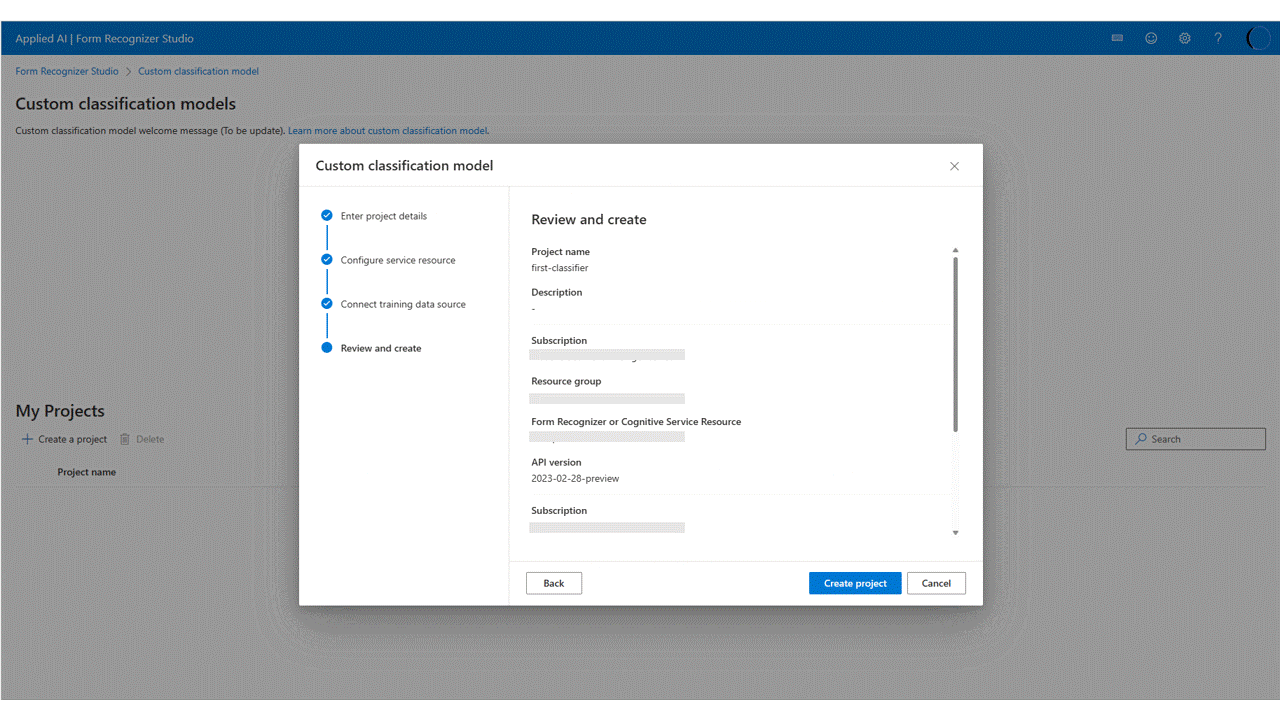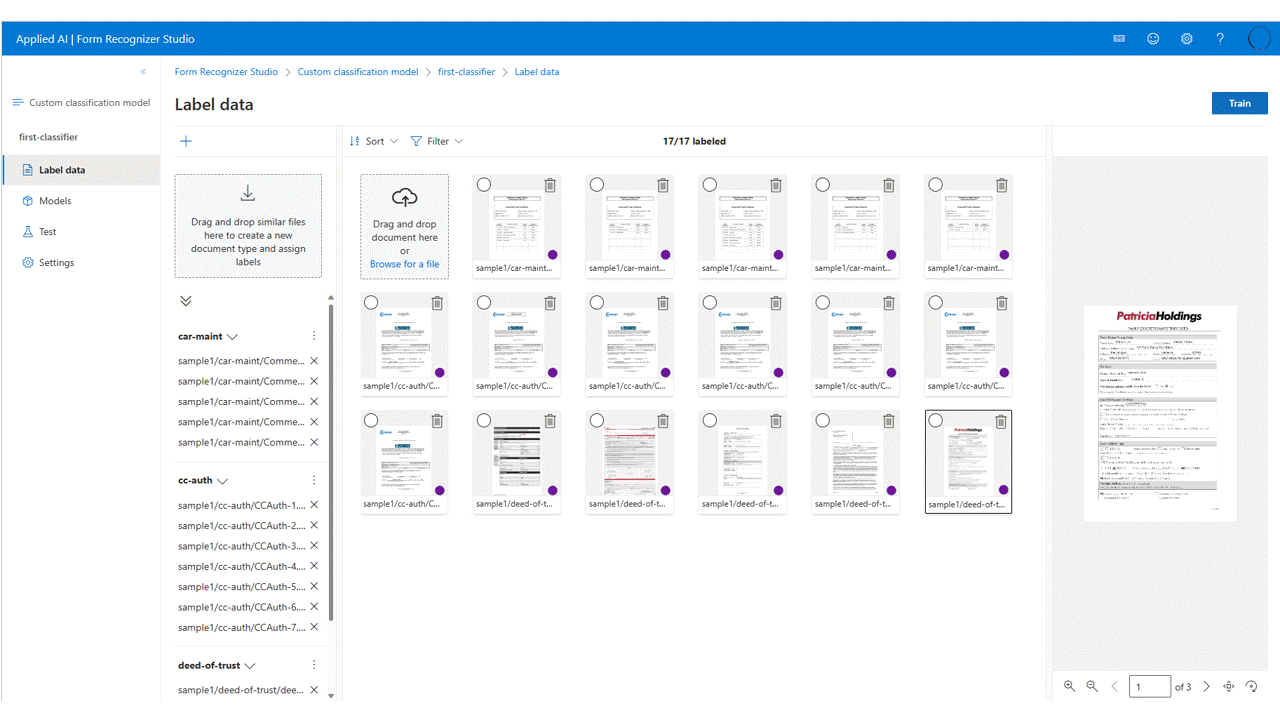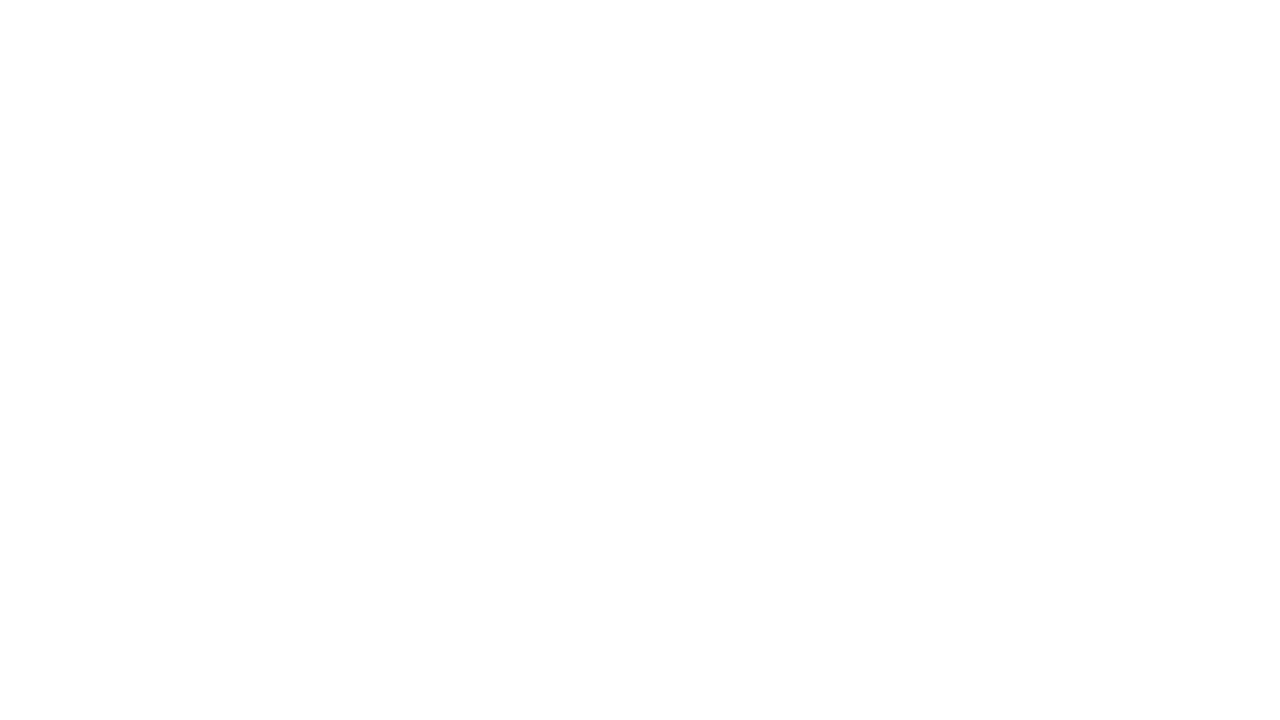
你可以在文件列表中看到已上传到存储空间的文件,并可对其进行标记。 有几个选项可用于标记数据集。
如果文档是整理在文件夹中,Studio 会提示要使用文件夹名称作为标签。 此步骤将标记过程简化为只需一次选择即可完成。
若要为文档分配标签,请选择
add label selection mark。按住 Control 键多选文档,以将其分配到某个标签。
现在,你的数据集中的所有文档应该都已完成标注。 如果查看存储帐户,将会看到训练数据集中每个文档对应的 .ocr.json 文件,以及每个已标记的类都有一个新的 class-name.jsonl 文件。 提交此训练数据集来训练模型。
训练模型
在标记了数据集后,你现在已准备就绪,可以训练模型了。 请选择右上角的训练按钮。
在训练模型对话框中,输入唯一的分类器 ID,并可选择输入描述。 该分类器 ID 接受字符串数据类型。
选择“训练”,以启动训练过程。
分类器模型会在几分钟内完成训练。
转到模型菜单以查看训练操作的状态。
测试模型
在完成模型训练后,可通过在模型列表页上选择该模型来测试模型。
选择模型,然后选择 “测试 ”按钮。
通过浏览文件或将文件放入文档选择器来添加新文件。
选择了某个文件后,选择“分析”按钮,以测试该模型。
模型结果显示有已识别文档的列表、每个已识别文档的置信度分数以及页面范围。
通过评估每个已识别文档的结果来验证模型。
使用 SDK 或 API 训练自定义分类器
Studio 协调 API 调用,以便训练自定义分类器。 分类器训练数据集需要与训练模型的 API 版本匹配的布局 API 的输出。 如果使用较旧 API 版本中的布局结果,则可能会导致模型的准确性较低。
如果数据集不包含布局结果,工作室将为训练数据集生成布局结果。 使用 API 或 SDK 训练分类器时,需要将布局结果添加到包含各个文档的文件夹。 直接调用布局时,布局结果应采用 API 响应的格式。 SDK 对象模型不同。 确保 layout results 是 API 结果而不是 SDK response。
疑难解答
分类模型需要来自每个训练文档的布局模型的结果。 如果未提供布局结果,Studio 会尝试在训练分类器之前为每个文档运行布局模型。 该过程会被限流,并且可能返回 429 响应。
在 Studio 中使用分类模型进行训练之前,对每个文档运行布局模型,并将其上传到与原始文档相同的位置。 添加布局结果后,可以使用文档训练分类器模型。