Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
重要
- Azure AI 语言公共预览版提供了对当前处于正在开发状态的功能的提前访问权限。
- 根据用户反馈,在正式发布(正式版)之前,功能、方法和流程可能会发生变化。
Azure AI 语言是一项基于云的服务,可将自然语言处理 (NLP) 功能应用于基于文本的数据。 文档摘要使用自然语言处理为文档生成提取性(重点句子提取)或抽象性(上下文字词提取)摘要。
AbstractiveSummarization 和 ExtractiveSummarization API 都支持本机文档处理。 原生文档是指用于创建原始文档的文件格式,例如 Microsoft Word (docx) 或可移植文档文件 (pdf)。 有了原生文档支持,在使用 Azure AI 语言资源功能之前无需再进行文本预处理。 本机文档支持功能让你能够以异步方式发送 API 请求,从而使用 HTTP POST 请求正文来发送数据,使用 HTTP GET 请求查询字符串来检索状态结果。 已处理的文档位于 Azure Blob 存储目标容器中。
支持的文档格式
应用程序使用本机文件格式创建、保存或打开本机文档。 目前,PII 和文档摘要功能支持以下本机文档格式:
| 文件类型 | 文件扩展名 | 说明 |
|---|---|---|
| 文本 | .txt |
无格式的文本文档。 |
| Adobe PDF | .pdf |
可移植文档文件格式的文档。 |
| Microsoft Word | .docx |
Microsoft Word 文档文件。 |
输入准则
支持的文件格式
| 类型 | 支持和限制 |
|---|---|
| 不支持完全扫描的 PDF。 | |
| 图像中的文本 | 不支持带有嵌入文本的数字图像。 |
| 数字表 | 不支持扫描文档中的表。 |
文档大小
| 特征 | 输入限制 |
|---|---|
| 每个请求的文档总数 | ≤ 20 |
| 每个请求的内容总大小 | ≤ 10 MB |
包括带有 HTTP 请求的本机文档
让我们开始吧:
对于此项目,我们使用 cURL 命令行工具进行 REST API 调用。
注释
大多数 Windows 10 和 Windows 11 以及大多数 macOS 和 Linux 发行版都预安装了 cURL 包。 可以使用以下命令检查包版本:Windows:
curl.exe -VmacOS:curl -VLinux:curl --version一个 Azure Blob 存储帐户。 你还需要在 Azure Blob 存储帐户中为源文件和目标文件创建容器:
- 源容器。 此容器用于上传原始文件以进行分析(必需)。
- 目标容器。 此容器用于存储已分析的文件(必需)。
单服务语言资源(不是多服务 Azure AI 服务资源):
完成语言资源项目和实例详细信息字段,如下所示:
订阅。 选择一个可用的 Azure 订阅。
资源组。 你可以创建新的资源组,或将资源添加到预先存在的具有相同生命周期、权限和策略的资源组。
资源区域。 选择“全球”,除非你的业务或应用程序需要特定区域。 如果打算使用系统分配的托管标识进行身份验证,请选择一个地理区域,如“中国北部”。
名称。 输入您为资源选择的名称。 所选名称在 Azure 中必须唯一。
定价层。 可以使用免费定价层 (
Free F0) 试用该服务,然后再升级到付费层进行生产。选择 审阅 + 创建。
查看服务条款,然后选择“创建”以部署资源。
成功部署资源后,选择转到资源。
获取你的密钥和语言服务端点
对语言服务的请求需要一个只读密钥和自定义终结点来对访问进行身份验证。
如果已创建新资源,请在部署该资源后选择“转到资源”。 如果有现有的语言服务资源,请直接导航到资源页。
在左侧导航栏中的资源管理下,选择密钥和终结点。
可以将你的
key和language service instance endpoint复制粘贴到代码示例中,从而对向语言服务的请求进行身份验证。 发出 API 调用只需一个密钥。
创建 Azure Blob 存储容器
在你的 Azure Blob 存储帐户中为源文件和目标文件创建容器。
- 源容器。 此容器用于上传原始文件以进行分析(必需)。
- 目标容器。 此容器用于存储已分析的文件(必需)。
身份验证
语言资源需要被授予对存储帐户的访问权限,然后才能创建、读取或删除 blob。 有两种主要方法可用于授予对存储数据的访问权限:
共享访问签名 (SAS) 令牌。 用户委派 SAS 令牌是通过 Microsoft Entra 凭据保护的。 SAS 令牌提供对 Azure 存储帐户中资源的安全委托式访问。
托管标识基于角色的访问控制 (RBAC)。 Azure 资源托管标识是一种服务主体,可为 Azure 托管资源创建 Microsoft Entra 标识和特定权限。
对于此项目,我们通过在查询字符串中追加共享访问签名 (SAS) 令牌来对 source location 和 target location URL 的访问进行身份验证。 每个令牌都分配给特定的 blob(文件)。

- 源容器或 blob 必须指定读取和列出访问权限。
- 目标容器或 blob 必须指定写入和列出访问权限。
提取式摘要 API 使用自然语言处理技术在非结构化文本文档中查找关键句子。 这些句子共同传达文档的主要理念。
提取式摘要返回排名分数作为系统响应的一部分,并返回提取的句子及其在原始文档中的位置。 排名分数是指确定句子相对于文档主要理念的相关程度的指标。 该模型为每个句子提供 0 到 1(含 0 和 1)之间的分数,并按请求返回分数最高的句子。 例如,如果请求一个包含三个句子的摘要,则该服务将返回分数最高的三个句子。
Azure AI 语言中还有另一项功能关键短语提取,其可提取关键信息。 若要在关键短语提取和提取摘要之间进行决定,以下是有用的注意事项:
- 关键短语提取返回短语,而抽取式摘要返回句子。
- 抽取式摘要返回带有排名分数的句子,并根据请求返回排名靠前的句子。
- 抽取式摘要还返回以下位置信息:
- 偏移量:每个所提取句子的起始位置。
- 长度:每个提取的句子的长度。
确定如何处理数据(可选)
提交数据
你将文档作为文本字符串提交到 API。 在收到请求时执行分析。 因为 API 是异步的,所以在发送 API 请求和接收结果之间可能存在延迟。
使用此功能时,API 结果在引入请求时的 24 小时内可用,并在响应中指示。 在此时间段后,结果将被清除,并且不再可用于检索。
获取文本摘要结果
从语言检测获得结果时,可以将结果流式传输到应用程序或将输出保存到本地系统上的文件中。
下面是可以提交以进行汇总的内容示例,它是使用 Microsoft 博客文章(集成式 AI 的整体表示形式)提取的。 本文只是一个示例。 API 可以接受更长的输入文本。 有关详细信息, 请参阅数据和服务限制。
“在 Microsoft,我们致力于推动人工智能技术超越现有水平,采用更全面、以人为本的方法来学习和理解。” 作为 Azure AI 服务的首席技术官,我一直在与一群了不起的科学家和工程师合作,将这一探索变为现实。 “在我的角色中,我以独特的视角看待人类认知的三个属性之间的关系:语言文本 (X)、音频或视觉传感器信号(Y) 和多语言 (Z)。” 在所有这三个属性的交点,都有一些神奇之处,如图 1 所示,我们称之为 XYZ 代码,它是一种联合表示,可以创造出更强大的 AI,它能说、听、看和更好地理解人类。 我们相信 XYZ 代码将使我们能够实现长期愿景:跨领域迁移学习、跨越模式和语言。 目标是拥有可以联合学习表示以支持广泛的下游 AI 任务的预训练模型,就像人们现在所做的。 在过去的五年里,我们在对话语音识别、机器翻译、对话式问答、机器阅读理解和图像标题方面实现了人类在基准测试方面的表现。 这五项突破为我们提供了强烈的信号,让我们朝着更雄心勃勃的愿望实现人工智能能力的飞跃,实现更接近人类学习和理解方式的多感官和多语言学习。 只要以下游 AI 任务中的外部知识源为基础,我相信联合 XYZ 代码是这一愿望的重要组成部分。”
收到请求后,通过为 API 后端创建作业来处理文本摘要 API 请求。 如果作业成功,将返回 API 的输出。 输出可供在 24 小时内检索。 此时间过后,输出将被清除。 由于多语言和表情符号支持,响应可能包含文本偏移。 有关详细信息,请参阅如何处理偏移量。
使用前面的示例时,API 可能会返回以下汇总句子:
抽取式摘要:
- 在 Microsoft,我们寻求通过采用一种更全面且以人为本的方法来学习和理解,推动 AI 超越现有技术。
- “我们相信 XYZ 代码将使我们能够实现长期愿景:跨领域迁移学习、跨越模式和语言。”
- 目标是拥有可以联合学习表示以支持广泛的下游 AI 任务的预训练模型,就像人们现在所做的。
抽象式摘要:
- “Microsoft 正在采取更全面的、以人为本的方法来学习和理解。 我们相信 XYZ 代码将使我们能够实现长期愿景:跨领域迁移学习、跨越模式和语言。 在过去的五年里,我们在基准测试中达到了人类的表现水平。”
试用文本抽取式摘要
可以使用文本抽取式摘要来获取文章、论文或文档的摘要。 若要查看示例,请参阅快速入门文章。
你可以使用 sentenceCount 参数指导将返回的句子数,默认值为 3。 范围为 1 到 20。
你还可以使用 sortby 参数指定提取的句子的返回顺序(Offset 或 Rank),默认值为 Offset。
| 参数值 | 说明 |
|---|---|
| 设置级别 | 根据句子与输入文档的相关性(由服务决定)对句子进行排序。 |
| Offset | 保持句子在输入文档中出现的原始顺序。 |
试用文本抽象式摘要
以下示例将帮助你开始使用文本抽象式摘要:
- 将以下命令复制到文本编辑器中。 BASH 示例使用
\续行符。 如果你的控制台或终端使用不同的续行符,请改用相应符号。
curl -i -X POST https://<your-language-resource-endpoint>/language/analyze-text/jobs?api-version=2023-04-01 \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>" \
-d \
'
{
"displayName": "Text Abstractive Summarization Task Example",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en",
"text": "At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding. As Chief Technology Officer of Azure AI services, I have been working with a team of amazing scientists and engineers to turn this quest into a reality. In my role, I enjoy a unique perspective in viewing the relationship among three attributes of human cognition: monolingual text (X), audio or visual sensory signals, (Y) and multilingual (Z). At the intersection of all three, there's magic—what we call XYZ-code as illustrated in Figure 1—a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We believe XYZ-code enables us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. The goal is to have pretrained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today. Over the past five years, we have achieved human performance on benchmarks in conversational speech recognition, machine translation, conversational question answering, machine reading comprehension, and image captioning. These five breakthroughs provided us with strong signals toward our more ambitious aspiration to produce a leap in AI capabilities, achieving multi-sensory and multilingual learning that is closer in line with how humans learn and understand. I believe the joint XYZ-code is a foundational component of this aspiration, if grounded with external knowledge sources in the downstream AI tasks."
}
]
},
"tasks": [
{
"kind": "AbstractiveSummarization",
"taskName": "Text Abstractive Summarization Task 1",
}
]
}
'
必要时在命令中进行如下更改:
- 请将值
your-language-resource-key替换为你的密钥。 - 将请求 URL 的第一部分 (
your-language-resource-endpoint) 替换为你的终结点 URL。
- 请将值
打开命令提示符窗口(例如 BASH)。
将文本编辑器中的命令粘贴到命令提示符窗口,然后运行该命令。
从响应头获取
operation-location。 该值类似于以下 URL:
https://<your-language-resource-endpoint>/language/analyze-text/jobs/12345678-1234-1234-1234-12345678?api-version=2022-10-01-preview
- 要获取请求的结果,请使用以下 cURL 命令。 请务必将
<my-job-id>替换为从之前的operation-location响应头中收到的数值 ID 值:
curl -X GET https://<your-language-resource-endpoint>/language/analyze-text/jobs/<my-job-id>?api-version=2022-10-01-preview \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>"
抽象式文本摘要示例 JSON 响应
{
"jobId": "cd6418fe-db86-4350-aec1-f0d7c91442a6",
"lastUpdateDateTime": "2022-09-08T16:45:14Z",
"createdDateTime": "2022-09-08T16:44:53Z",
"expirationDateTime": "2022-09-09T16:44:53Z",
"status": "succeeded",
"errors": [],
"displayName": "Text Abstractive Summarization Task Example",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "AbstractiveSummarizationLROResults",
"taskName": "Text Abstractive Summarization Task 1",
"lastUpdateDateTime": "2022-09-08T16:45:14.0717206Z",
"status": "succeeded",
"results": {
"documents": [
{
"summaries": [
{
"text": "Microsoft is taking a more holistic, human-centric approach to AI. We've developed a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We've achieved human performance on benchmarks in conversational speech recognition, machine translation, ...... and image captions.",
"contexts": [
{
"offset": 0,
"length": 247
}
]
}
],
"id": "1"
}
],
"errors": [],
"modelVersion": "latest"
}
}
]
}
}
| 参数 | 说明 |
|---|---|
-X POST <endpoint> |
指定用于访问 API 的语言资源终结点。 |
--header Content-Type: application/json |
用于发送 JSON 数据的内容类型。 |
--header "Ocp-Apim-Subscription-Key:<key> |
指定用于访问 API 的语言资源密钥。 |
-data |
包含要随请求传递的数据的 JSON 文件。 |
以下 cURL 命令从 BASH shell 中执行。 请使用自己的资源名称、资源密钥和 JSON 值编辑这些命令。 通过选择 Personally Identifiable Information (PII) 或 Document Summarization 代码示例项目来尝试分析本地文档:
摘要示例文档
对于此项目,你需要将源文档上传到源容器。 可下载本快速入门的 Microsoft Word 示例文档或 Adobe PDF。 源语言为英语。
生成 POST 请求
使用首选编辑器或 IDE,为应用创建一个名为
native-document的新目录。在 native-document 目录中创建名为 document-summarization.json 的新 json 文件。
将文档摘要请求示例复制粘贴到你的
document-summarization.json文件中。 使用 Azure 门户存储帐户容器实例中的值替换{your-source-container-SAS-URL}和{your-target-container-SAS-URL}:
请求示例
{
"tasks": [
{
"kind": "ExtractiveSummarization",
"parameters": {
"sentenceCount": 6
}
}
],
"analysisInput": {
"documents": [
{
"source": {
"location": "{your-source-blob-SAS-URL}"
},
"targets": {
"location": "{your-target-container-SAS-URL}"
}
}
]
}
}
运行 POST 请求
在运行 POST 请求之前,将 {your-language-resource-endpoint} 和 {your-key} 替换为你的 Azure 门户语言资源实例中的终结点值。
重要
完成后,请记住将密钥从代码中删除,并且永远不要公开发布该密钥。 对于生产来说,请使用安全的方式存储和访问凭据,例如 Azure Key Vault。 有关详细信息,请参阅 Azure AI 服务安全性。
PowerShell
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" -i -X POST --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
命令提示符/终端
curl -v -X POST "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
示例响应:
HTTP/1.1 202 Accepted
Content-Length: 0
operation-location: https://{your-language-resource-endpoint}/language/analyze-documents/jobs/f1cc29ff-9738-42ea-afa5-98d2d3cabf94?api-version=2024-11-15-preview
apim-request-id: e7d6fa0c-0efd-416a-8b1e-1cd9287f5f81
x-ms-region: China North 2
Date: Thu, 25 Jan 2024 15:12:32 GMT
POST 响应 (jobId)
你会收到包含只读 Operation-Location 标头的 202(成功)响应。 此标头的值包含一个 jobId,可以查询它以获取异步操作的状态,并使用 GET 请求检索结果:
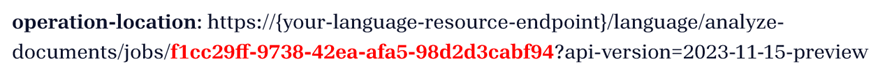
获取分析结果(GET 请求)
在成功的 POST 请求后,轮询 POST 请求中返回的操作位置标头以查看已处理的数据。
下面是 GET 请求的结构:
GET {cognitive-service-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview运行该命令之前,请进行以下更改:
将 {jobId} 替换为 POST 响应中的 Operation-Location 标头。
将 {your-language-resource-endpoint} 和 {your-key} 替换为你的 Azure 门户中语言服务实例中的值。
Get 请求
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" -i -X GET --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
curl -v -X GET "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
检查响应
收到 JSON 输出为 200(成功)的响应。 status 字段指示操作的结果。 如果操作未完成,status 的值为 "running" 或 "notStarted",你应当采用手动方式或通过脚本再次调用该 API。 我们建议两次调用间隔一秒或更长时间。
示例响应
{
"jobId": "f1cc29ff-9738-42ea-afa5-98d2d3cabf94",
"lastUpdatedDateTime": "2024-01-24T13:17:58Z",
"createdDateTime": "2024-01-24T13:17:47Z",
"expirationDateTime": "2024-01-25T13:17:47Z",
"status": "succeeded",
"errors": [],
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "ExtractiveSummarizationLROResults",
"lastUpdateDateTime": "2024-01-24T13:17:58.33934Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "doc_0",
"source": {
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.chinacloudapi.cn/sample-input/input.pdf"
},
"targets": [
{
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.chinacloudapi.cn/sample-output/df6611a3-fe74-44f8-b8d4-58ac7491cb13/ExtractiveSummarization-0001/input.result.json"
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2023-02-01-preview"
}
}
]
}
}
成功完成后:
- 可以在你的目标容器中找到已分析的文档。
- 成功的 POST 方法返回
202 Accepted响应代码,指示服务创建了批处理请求。 - POST 请求还返回了包含
Operation-Location的响应标头,它提供了在后续 GET 请求中使用的值。
清理资源
若要清理和删除 Azure AI 资源,可以删除单个资源或整个资源组。 如果删除资源组,也会删除包含的所有资源。