Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍:
- 可以为此服务收集的监视数据的类型。
- 如何分析这些数据。
如果具有依赖于 Azure 资源的关键应用程序和业务流程,则需要监视并获取系统的警报。 Azure Monitor 服务会从系统的每个组件收集并聚合指标和日志。 Azure Monitor 提供可用性、性能和复原能力视图,并在出现问题时向你发送通知。 可以使用 Azure 门户、PowerShell、Azure CLI、REST API 或客户端库来设置和查看监视数据。
- 有关 Azure Monitor 的详细信息,请参阅 Azure Monitor 概述。
- 有关监视 Azure 资源的常规方法的详细信息,请参阅使用 Azure Monitor 监视 Azure 资源。
Analysis Services 还提供了多个非 Azure Monitor 监视机制:
- SQL Server Profiler 随 SQL Server Management Studio (SSMS) 一起安装,它会捕获有关引擎进程事件的数据,例如批处理或事务的启动,使你能够监视服务器和数据库活动。 有关详细信息,请参阅 使用 SQL Server Profiler 监控 Analysis Services。
- 扩展事件 (xEvents) 是一种占用系统资源非常少的轻量跟踪和性能监视系统,因此它成为了诊断生产和测试服务器问题的理想工具。 有关详细信息,请参阅 使用 SQL Server 扩展事件监视 Analysis Services。
- 动态管理视图 (DMV) 使用 SQL 语法来接口架构行集,这些行集会返回有关服务器实例的元数据和监视信息。 有关详细信息,请参阅 借助动态管理视图(DMVs)对 Analysis Services 进行监视。
资源类型
Azure 使用资源类型和 ID 的概念来标识订阅中的所有内容。 同样的,Azure Monitor 根据资源类型(也称为“命名空间”)将核心监视数据组织为指标和日志。 不同的指标和日志可用于不同的资源类型。 服务可能与多种资源类型关联。
资源类型也是 Azure 中运行的每个资源的资源 ID 的一部分。 例如,虚拟机的一种资源类型是 Microsoft.Compute/virtualMachines。 有关服务及其关联资源类型的列表,请参阅资源提供程序。
有关 Analysis Services 的资源类型的详细信息,请参阅 Analysis Services 监视数据参考。
数据存储
对于 Azure Monitor:
- 指标数据存储在 Azure Monitor 指标数据库中。
- 日志数据存储在 Azure Monitor 日志存储中。 Log Analytics 是 Azure 门户中可以查询此存储的工具。
- Azure 活动日志是一个单独的存储区,在 Azure 门户中有自己的接口。
- 可选择将指标和活动日志数据路由到 Azure Monitor 日志数据库存储,以便可使用 Log Analytics 查询数据并将其与其他日志数据关联。
有关 Azure Monitor 如何存储数据的详细信息,请参阅 Azure Monitor 数据平台。
Azure Monitor 平台指标
Azure Monitor 为大多数服务提供平台指标。 这些指标是:
- 针对每个命名空间单独定义。
- 存储在 Azure Monitor 时序指标数据库中。
- 轻量级且具备支持准实时警报的能力。
- 用于跟踪资源随时间推移的性能变化。
集合:Azure Monitor 会自动收集平台指标。 不需要任何配置。
路由:通常还可将平台指标路由到 Azure Monitor 日志/Log Analytics,从而可以使用其他日志数据对其进行查询。 有关详细信息,请参阅指标诊断设置。 有关如何为服务配置诊断设置,请参阅在 Azure Monitor 中创建诊断设置。
有关可以为 Azure Monitor 中的所有资源收集的所有指标的列表,请参阅 Azure Monitor 中支持的指标。
有关 Analysis Services 的可用度量列表,请参阅 Analysis Services 监视数据参考。
Azure Monitor 资源日志
借助资源日志,可以深入了解 Azure 资源已执行的操作。 日志是自动生成的,但必须将日志路由到 Azure Monitor 日志以保存或查询它们。 日志按类别组织。 给定的命名空间可能具有多个资源日志类别。
收集:在创建诊断设置并将日志路由到一个或多个位置之前,不会收集和存储资源日志。 创建诊断设置时,指定要收集的日志类别。 可以通过多种方式创建和维护诊断设置,包括 Azure 门户、编程方式以及通过 Azure Policy。
路由:建议的默认设置是将资源日志路由到 Azure Monitor 日志,以便可以使用其他日志数据查询它们。 其他位置(例如 Azure 存储、Azure 事件中心和某些 Azure 监视合作伙伴)也可用。 有关详细信息,请参阅 Azure 资源日志和资源日志目标。
有关收集、存储和路由资源日志的详细信息,请参阅 Azure Monitor 中的诊断设置。
有关 Azure Monitor 中所有可用资源日志类别的列表,请参阅 Azure Monitor 中支持的资源日志。
Azure Monitor 中的所有资源日志都具有相同的标头字段,后跟特定于服务的字段。 Azure Monitor 资源日志架构中概述了通用架构。
- 有关可用的资源日志类别、关联的 Log Analytics 表和 Analysis Services 的日志架构,请参阅 Analysis Services 监视数据参考。
Analysis Services 资源日志
若要了解如何设置诊断日志记录,请参阅 设置诊断日志记录。
在为 Analysis Services 设置日志记录时,可以选择记录引擎事件或服务事件,或者选择AllMetrics来记录指标数据。 有关详细信息,请参阅 Microsoft.AnalysisServices/servers 支持的资源日志。
Azure 活动日志
活动日志包含订阅级事件,这些事件跟踪从资源外部看到的每个 Azure 资源的操作;例如,创建新资源或启动虚拟机。
收集:活动日志事件会自动生成并收集在单独的存储中,以便在 Azure 门户中查看。
路由:可将活动日志数据发送到 Azure Monitor 日志,以便可以将它们与其他日志数据一起进行分析。 其他位置(例如 Azure 存储、Azure 事件中心和某些 Azure 监视合作伙伴)也可用。 有关如何路由活动日志的详细信息,请参阅 Azure 活动日志概述。
分析监视数据
有许多工具可用于分析监视数据。
Azure Monitor 工具
Azure Monitor 支持以下基本工具:
指标资源管理器,它是 Azure 门户中的工具,可用于查看和分析 Azure 资源的指标。 有关详细信息,请参阅使用 Azure Monitor 指标资源管理器分析指标。
Log Analytics 是 Azure 门户中的一种工具,可用于使用 Kusto 查询语言(KQL)查询和分析日志数据。 有关详细信息,请参阅 Azure Monitor 日志查询入门。
活动日志,该日志在 Azure 门户中具有用于查看和基本搜索的用户界面。 要进行更深入的分析,必须将数据路由到 Azure Monitor 日志,并在 Log Analytics 中运行更复杂的查询。
支持更复杂可视化效果的工具包括:
- 仪表板,它支持将不同类型的数据合并到 Azure 门户的单个窗格中。
- 工作簿、可在 Azure 门户中创建的可自定义报表。 工作簿可以包括文本、指标和日志查询。
- Power BI 是一项业务分析服务,可跨各种数据源提供交互式可视化效果。 可将 Power BI 配置为自动从 Azure Monitor 导入日志数据,以利用这些可视化效果。
Azure Monitor 导出工具
可以使用以下方法将数据从 Azure Monitor 中提取到其他工具中:
指标:使用适用于指标的 REST API 从 Azure Monitor 指标数据库提取指标数据。 API 支持使用筛选表达式优化检索到的数据。 有关详细信息,请参阅 Azure Monitor REST API 参考。
日志: 使用 REST API 或 相关的客户端库。
要开始使用适用于 Azure Monitor 的 REST API,请参阅 Azure 监视 REST API 演练。
分析 Analysis Services 指标
可以使用 Azure Monitor 指标资源管理器中的 Analysis Services 指标来帮助监视服务器的性能和运行状况。 例如,可以监视内存和 CPU 使用率、客户端连接数和查询资源消耗量。
若要确定是否需要横向扩展服务器,请监视服务器 QPU 和 查询池作业队列长度 指标。 一个可以监视的指标是 ServerResourceType 的平均 QPU,它会比较主服务器与查询池的平均 QPU。 有关如何根据指标数据横向扩展服务器的详细说明,请参阅 Azure Analysis Services 横向扩展。
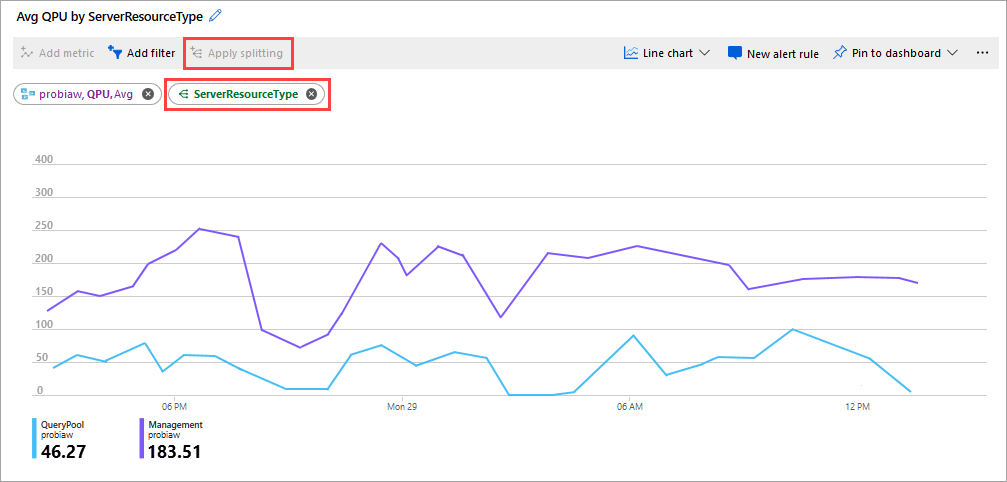
有关为 Analysis Services 收集的指标的完整列表,请参阅 Analysis Services 监控数据参考。
在 Log Analytics 工作区中分析日志
在 Log Analytics 工作区资源中,指标和服务器事件与 Xevent 集成,以便并列分析。 Log Analytics 工作区还可配置为接收来自其他 Azure 服务的事件,从而提供整个体系结构的诊断日志记录数据。
若要查看诊断数据,请从 Log Analytics 工作区的左侧菜单中打开“日志”。
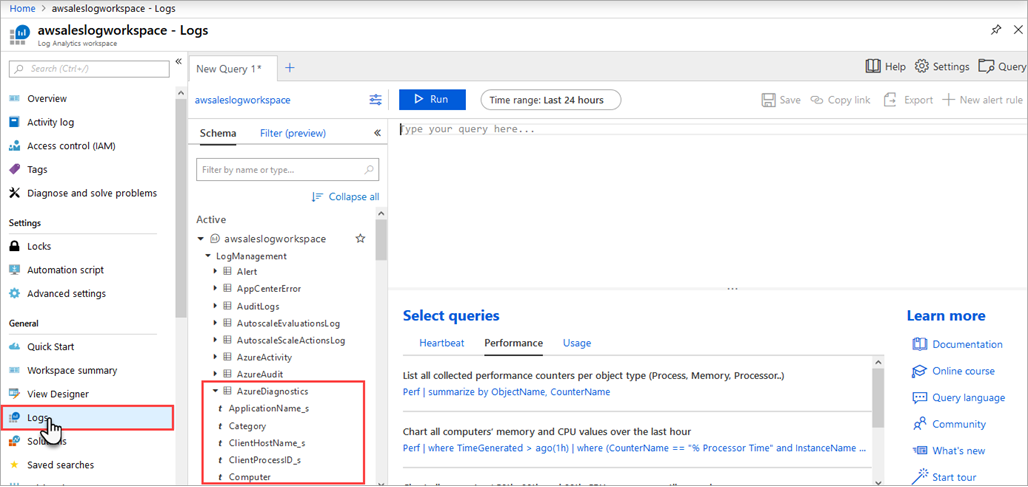
在查询生成器中,展开 LogManagementAzureDiagnostics 。 AzureDiagnostics 包括引擎和服务事件。 注意,查询是即时创建的。 EventClass_s 字段包含 xEvent 名称,如果使用 Xevent 进行本地日志记录,你可能觉得该名称很眼熟。 选择 EventClass_s 或某一个事件名称,Log Analytics 工作区会继续构造查询。 请务必保存查询以便稍后重复使用。
Kusto 查询
可使用 Kusto 查询语言 (KQL) 来分析 Azure Monitor 日志/Log Analytics 存储中的监视数据。
重要
在门户的服务菜单中选择“日志”时,会打开 Log Analytics,并且其查询范围设置为当前服务。 此范围意味着日志查询将仅包含来自该资源类型的数据。 如果希望运行的查询包含来自其他 Azure 服务的数据,请从“Azure Monitor”菜单中选择“日志”。 有关详细信息,请参阅 Azure Monitor Log Analytics 中的日志查询范围和时间范围。
有关任何服务的常见查询列表,请参阅 Log Analytics 查询接口。
以下查询对监视 Analysis Services 服务器很有用。
示例 1
以下查询返回模型数据库和服务器的每个查询结束/刷新结束事件的持续时间。 如果进行横向扩展,则结果将按副本细分,因为副本编号包含在 ServerName_s 中。 按 RootActivityId_g 分组可减少从 Azure 诊断 REST API 检索到的行数,并有助于保持在 Log Analytics 速率限制中所述的限制内。
let window = AzureDiagnostics
| where ResourceProvider == "MICROSOFT.ANALYSISSERVICES" and Resource =~ "MyServerName" and DatabaseName_s =~ "MyDatabaseName" ;
window
| where OperationName has "QueryEnd" or (OperationName has "CommandEnd" and EventSubclass_s == 38)
| where extract(@"([^,]*)", 1,Duration_s, typeof(long)) > 0
| extend DurationMs=extract(@"([^,]*)", 1,Duration_s, typeof(long))
| project StartTime_t,EndTime_t,ServerName_s,OperationName,RootActivityId_g,TextData_s,DatabaseName_s,ApplicationName_s,Duration_s,EffectiveUsername_s,User_s,EventSubclass_s,DurationMs
| order by StartTime_t asc
示例 2
以下查询返回服务器的内存和 QPU 消耗。 如果进行横向扩展,则结果将按副本细分,因为副本编号包含在 ServerName_s 中。
let window = AzureDiagnostics
| where ResourceProvider == "MICROSOFT.ANALYSISSERVICES" and Resource =~ "MyServerName";
window
| where OperationName == "LogMetric"
| where name_s == "memory_metric" or name_s == "qpu_metric"
| project ServerName_s, TimeGenerated, name_s, value_s
| summarize avg(todecimal(value_s)) by ServerName_s, name_s, bin(TimeGenerated, 1m)
| order by TimeGenerated asc
示例 3
以下查询返回服务器的 Analysis Services 引擎性能计数器每秒读取的行数。
let window = AzureDiagnostics
| where ResourceProvider == "MICROSOFT.ANALYSISSERVICES" and Resource =~ "MyServerName";
window
| where OperationName == "LogMetric"
| where parse_json(tostring(parse_json(perfobject_s).counters))[0].name == "Rows read/sec"
| extend Value = tostring(parse_json(tostring(parse_json(perfobject_s).counters))[0].value)
| project ServerName_s, TimeGenerated, Value
| summarize avg(todecimal(Value)) by ServerName_s, bin(TimeGenerated, 1m)
| order by TimeGenerated asc
警报
在监视数据中发现特定情况时,Azure Monitor 警报会主动向你发出通知。 有了警报,你就可以在客户注意到你的系统中的问题之前找出和解决问题。 有关详细信息,请参阅 Azure Monitor 警报。
Azure 资源的常见警报具有许多来源。 有关 Azure 资源常见警报的示例,请参阅示例日志警报查询。 Azure Monitor 基线警报 (AMBA) 站点提供了 Azure 登陆区域 (ALZ) 场景的关键警报指标、仪表板和指南。
通用警报模式对 Azure Monitor 警报通知的使用体验进行了标准化。 有关详细信息,请参阅 常见警报架构。
警报类型
可以在 Azure Monitor 数据平台中针对任何指标或日志数据源发出警报。 警报具有许多不同类型,具体取决于要监视的服务以及要收集的监视数据。 不同类型的警报各有优缺点。 有关详细信息,请参阅选择正确的监视警报类型。
以下列表介绍了可以创建的 Azure Monitor 警报类型:
- 指标警报会定期评估资源指标。 指标可以是平台指标、自定义指标、Azure Monitor 中的日志转换为的指标或 Application Insights 指标。 指标警报还可以应用多个条件和动态阈值。
- 日志警报支持用户使用 Log Analytics 查询按照预定义的频率评估资源日志。
- 当发生匹配所定义条件的新活动日志事件时,会触发活动日志警报。 资源运行状况警报和服务运行状况警报是报告服务和资源运行状况的活动日志警报。
还可以为某些 Azure 服务创建以下类型的警报:
- Application Insights 资源上的智能检测警报会就 Web 应用程序中的潜在性能问题和故障异常自动向你发出警报。 可以在 Application Insights 资源上迁移智能检测,以便为不同的智能检测模块创建警报规则。
- Prometheus 警报:针对 Prometheus 指标的警报,这些指标存储在适用于 Prometheus 的 Azure Monitor 托管服务中。 该警报规则基于 PromQL,它是一种开源查询语言。 你的服务可能不支持此类型警报。 目前,Prometheus 用于具有来宾操作系统的有限服务集,例如 Azure 虚拟机和 Azure 容器实例。
- 对于某些 Azure 资源(包括虚拟机、Azure Kubernetes 服务 [AKS] 资源和 Log Analytics 工作区),提供了现成可用的建议警报规则。
监视多个资源
通过将相同的指标警报规则应用于同一 Azure 区域中的多个相同类型资源,可以进行大规模的监视。 将为每个受监视的资源发送单独通知。 有关支持的 Azure 服务和云,请参阅使用一个警报规则监视多个资源。
Analysis Services 警报规则
下表列出了 Analysis Services 的一些常见和常用的警报规则。
| 警报类型 | 条件 | DESCRIPTION |
|---|---|---|
| 指标 | 每当最大 qpu_metric 大于动态阈值时。 | 如果 QPU 经常超过上限,则表示针对模型的查询数量超出了计划的 QPU 限制。 |
| 指标 | 每当最大 QueryPoolJobQueueLength 大于动态阈值时。 | 查询线程池队列中的查询数超过了可用的 QPU。 |
顾问建议
如果在资源操作期间出现严重情况或即将发生变化,则门户中的“概述”页面上会显示一个警报。
可以在监控下的顾问建议中找到警报的详细信息和建议的修复措施。 在正常操作期间,不会显示任何顾问建议。
有关 Azure 顾问的详细信息,请参阅 Azure 顾问概述。
相关内容
- 有关为 Analysis Services 创建的指标、日志和其他重要值的参考,请参阅 Analysis Services 监视数据参考 。
- 有关监视 Azure 资源的一般详细信息,请参阅使用 Azure Monitor 监视 Azure 资源。