Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍通过本地冗余实现可用性的Azure SQL Database体系结构,以及通过区域冗余实现高可用性。
概述
SQL 数据库在具有所有适用修补程序的 Windows 操作系统上的最新稳定版 SQL Server 数据库引擎上运行。 SQL 数据库会自动处理关键服务任务,例如修补、备份、Windows和 SQL 引擎升级,以及基础硬件、软件或网络故障等计划外事件。 修补 SQL 数据库中的数据库或弹性池或进行故障转移时,如果应用中已实现重试逻辑,则故障时间微乎其微。 即使出现最严重的问题,SQL 数据库也能快速恢复,确保数据始终可用。 大多数用户不会注意到升级是持续执行的。
默认情况下,Azure SQL Database通过本地冗余实现 可用性,确保数据库处理中断,例如:
- 因客户发起的管理操作而导致短暂停机
- 服务维护操作
- 以下基础设施的问题:
- 运行服务的计算机所在的机架
- 托管 SQL 数据库引擎的物理计算机
- SQL 数据库引擎的其他问题
- 其他潜在的计划外本地级中断事件
默认可用性解决方案旨在确保提交的数据不会因故障而丢失,维护作对工作负荷的影响最小,并且数据库不是软件体系结构中的单一故障点。
但是,若要在发生整个区域中断时尽量减少对数据的影响,可以通过启用区域冗余来实现高可用性。 如果没有区域冗余,故障转移会在同一数据中心的本地发生,这可能会导致数据库在中断得到解决之前不可用;唯一的恢复方法是通过灾难恢复解决方案进行恢复,例如通过异地冗余备份的活动异地复制、故障转移组或异地还原进行异地故障转移。 要了解详细信息,请查看业务连续性概述。
有三种可用性体系结构模型:
- 基于计算和存储隔离的远程存储模型。 远程存储模型依赖于远程存储层的可用性和可靠性。 此体系结构面向可以容忍在维护活动期间出现一定程度的性能下降的预算导向型业务应用程序。
- 基于数据库引擎进程群集的本地存储模型。 本地存储模型依赖于始终存在可用数据库引擎节点的法定数量。 此体系结构面向具有较高 IO 性能和较高事务处理率的任务关键型应用程序,保证维护活动期间尽量减小对工作负载性能造成的影响。
- 超大规模模型,它使用包含高度可用组件的分布式系统,例如计算节点、页面服务器、日志服务和持久存储。 支持超大规模数据库的每个组件都提供自身的冗余和故障复原能力。 计算节点、页服务器和日志服务在Azure Service Fabric上运行,该服务控制每个组件的运行状况,并根据需要执行到可用正常节点的故障转移。 持久性存储使用 Azure Storage 的本机高可用性和冗余功能。 若要了解详情,请参阅超大规模体系结构。
在三种可用性模型中,SQL 数据库支持本地冗余和区域冗余选项。 本地冗余在数据中心内提供复原能力,而区域冗余通过防范区域中可用性区域的中断,进一步提高复原能力。
下表显示了基于服务层的可用性选项:
| 服务层级 | 高可用性模型 | 本地冗余可用性 | 区域冗余可用性 |
|---|---|---|---|
| 常规用途 (vCore) | 远程存储 | 是 | 是 |
| 业务关键 (vCore) | 本地存储 | 是 | 是 |
| 超大规模 (vCore) | 超大规模 | 是 | 是 |
| 基本 (DTU) | 远程存储 | 是 | 否 |
| 标准 (DTU) | 远程存储 | 是 | 否 |
| 高级 (DTU) | 本地存储 | 是 | 是 |
有关不同服务层级的特定 SLA 的详细信息,请查看 SLA for Azure SQL Database。
通过本地冗余实现可用性
本地冗余可用性基于将数据库存储到本地冗余存储 (LRS) 中,该存储在主要区域的单个数据中心内复制数据三次,并在发生本地故障(例如小规模网络或电源故障)时保护数据。 与其他选项相比,LRS 是成本最低的冗余选项,但提供的持久性也最低。 如果区域内发生火灾或洪水等大规模灾难,使用 LRS 的存储帐户的所有副本可能会丢失或无法恢复。 因此,为了在使用本地冗余可用性选项时进一步保护数据,请考虑为数据库备份使用更具弹性的存储选项。 这不适用于超大规模数据库,因为在该数据库中,数据文件和备份使用的是相同的存储。
所有服务层级和恢复点目标 (RPO) 中的所有数据库都可以使用本地冗余可用性,这表示数据丢失量为零。
基本、标准和常规用途服务层级
基于 DTU 的购买模型的“基本”和“标准”服务层级,以及基于 vCore 的购买模型的“常规用途”服务层级将远程存储可用性模型用于无服务器计算和预配的计算。 下图显示了具有分隔计算层和存储层的节点。
远程存储可用性模型包括两个层:
无状态计算层:运行数据库引擎进程,仅包含暂时性的缓存数据,例如在附加的 SSD 上的
tempdb和model数据库,内存中的计划缓存、缓冲池和列存储池。 此无状态节点由 Azure Service Fabric 负责操作,包括初始化数据库引擎、监控节点运行状况,并在必要时执行到另一个节点的故障转移。一个有状态数据层,其中包含存储在Azure Blob Storage中的数据库文件(
.mdf和.ldf)。 Azure Blob Storage具有内置的数据可用性和冗余功能。 它可以保证即使数据库引擎进程崩溃,日志文件中的每条记录或者数据文件中的页面也仍会得到保留。
每当升级数据库引擎或作系统或检测到故障时,Azure Service Fabric将无状态数据库引擎进程移到具有足够可用容量的另一个无状态计算节点。 Azure Blob 存储中的数据不受移动的影响,数据/日志文件将附加到新初始化的数据库引擎进程。 此过程保证高可用性,但在过渡期间,繁重工作负载的性能可能会有一定程度的下降,因为新的数据库引擎进程是使用冷缓存启动的。
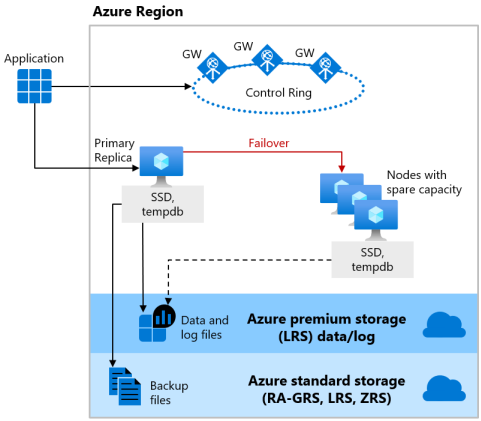
“高级”和“业务关键”服务层级
基于 DTU 的购买模型的高级服务层级以及基于 vCore 的购买模型的业务关键服务层级使用本地存储可用性模型,该模型与单个节点上的计算资源(数据库引擎进程)和存储(本地附加的 SSD)相集成。 实现高可用性的方式是将计算和存储资源复制到其他节点。
底层数据库文件 (.mdf/.ldf) 放在附加的 SSD 存储中,以便为工作负荷提供延迟极低的 IO。 高可用性是使用类似于 SQL Server Always On 可用性组的技术实现的。 群集包含可供读/写客户工作负载访问的单个主要副本,最多包含三个次要副本(计算和存储),这些副本包含数据的副本。 主要副本持续地按顺序将更改推送到次要副本中,并确保在提交每个事务之前,数据已被持久化到足够数量的次要副本。 此过程保证,如果主要副本或可读次要副本因任何原因崩溃,始终有一个完全同步的副本可以转移到。 故障转移由Azure Service Fabric启动。 次要副本成为新的主要副本后,系统将另外创建一个次要副本,确保群集具有足够数量的副本来维持仲裁。 故障转移完成后,Azure SQL连接会自动重定向到新的主副本或可读次要副本。
作为额外优势,本地存储可用性模型包括将只读Azure SQL连接重定向到其中一个次要副本的功能。 此功能称为读取横向扩展。它在无额外费用的情况下提供100%的额外计算容量,以减轻分析工作负荷等只读操作对主要副本的负担。
“超大规模”服务层级
“超大规模”服务层级体系结构在 分布式函数体系结构中进行了介绍,该体系结构具有详细的关系图。
“超大规模”中的可用性模型包括四个层:
无状态计算层:运行数据库引擎进程,仅包含暂时性缓存数据,例如在附加的 SSD 上的非覆盖性 RBPEX 缓存、
tempdb和model数据库等,以及内存中的计划缓存、缓冲池和列存储池。 此无状态层包括一个主要计算副本,以及可选的若干用于故障转移目标的次要计算副本。由页服务器组成的无状态存储层。 此层是在计算副本上运行的数据库引擎进程的分布式存储引擎。 每个页面服务器仅包含临时和缓存的数据,例如附加 SSD 上的 RBPEX 缓存,以及在内存中缓存的数据页。 每个页服务器在主动-主动配置中都有一个配对的页服务器,从而实现负载均衡、冗余性和高可用性。
一个有状态事务日志存储层,包含运行日志服务进程的计算节点、事务日志登陆区域,以及事务日志长期存储。 着陆区和长期存储使用Azure Storage,它为事务日志提供可用性和冗余,确保提交的事务的数据持久性。
具有数据库文件(.mdf/.ndf)的有状态数据存储层,存储在Azure Storage并由页面服务器更新。 此层使用Azure Storage的数据可用性和 redundancy 功能。 它保证保存数据文件中的每个页面,即使“超大规模”体系结构的其他层中的进程崩溃或计算节点故障,也是如此。
所有超大规模层中的计算节点在Azure Service Fabric上运行,该节点控制每个节点的运行状况,并根据需要执行到可用正常节点的故障转移。
若要详细了解超大规模中的高可用性,请参阅超大规模中的数据库高可用性。
通过区域冗余实现高可用性
对于区域冗余部署,在给定的区域中,Azure SQL Database 使用 Azure 可用区的数量,通常为两个或三个。 计算和存储组件跨越两个或三个区域,这些区域由 Azure SQL 数据库选择,以实现最佳复原能力,并位于具有独立电源、冷却和网络的物理位置。 Azure SQL根据区域可用性和服务优化自动选择区域数。 部署的区域不会少于确保复原能力所需的数量。
区域冗余可用性适用于基于 vCore 的购买模型的业务关键、常规用途和超大规模服务层级中的数据库,仅适用于基于 DTU 的购买模型的高级服务层级中的数据库 - 基本和标准服务层级不支持区域冗余。
虽然每个服务层以不同的方式实现区域冗余,但如果Azure区域中的单个可用性区域不可用,则所有实现都可确保恢复点目标(RPO)在故障转移时不会丢失已提交数据。
Azure SQL自动优化部署的区域位置。 所有可用性区域配置(使用两个或三个区域)提供相同的高可用性 SLA 和复原能力保证。
“常规用途”服务层级
在 vCore 购买模型中,无服务器和预配计算模式的“常规用途”服务层级数据库均支持区域冗余配置。 此配置利用 Azure Availability Zones 跨Azure区域中多个物理位置复制数据库。 通过选择区域冗余,你可以使新的和现有的无服务器和预配常规用途单一数据库和弹性池能够灵活应对范围要广得多的故障(包括灾难性的数据中心服务中断),且不会对应用程序逻辑进行任何更改。
“常规用途”层级的区域冗余配置有两个层:
- 一个有状态数据层,其中包含存储在 ZRS(区域冗余存储)中的数据库文件(.mdf/.ldf)。 使用 ZRS,在主要区域中的多个Azure可用性区域中同步复制数据和日志文件。 这是跨两个或三个区域,由Azure SQL选择以实现最佳复原能力。
- 无状态计算层:运行 sqlservr.exe 进程,仅包含暂时性的缓存数据,例如在附加的 SSD 上的
tempdb和model数据库,内存中的计划缓存、缓冲池和列存储池。 Azure Service Fabric 是负责操作此无状态节点的,它初始化 sqlservr.exe,控制节点的运行状况,并在必要时执行故障转移到另一个节点。 对于区域冗余的无服务器和预配常规用途数据库,当发生故障转移时,具有备用容量的节点可以在其他可用区中轻松获得。
常规用途服务级别的高可用性体系结构的区域冗余版本如下图所示:在两个区域或三个区域地区。
| 双区域区域 | 三区域区域 |
|---|---|

|

|
当计算资源被分布在两个可用性区域时:
- 备份和存储仍跨区域中的三个可用性区域同步。
- 区域冗余存储与往常一样,跨三个可用性区域同步。
在三个可用区内预配计算资源时:
- 备份和存储跨区域中的三个可用性区域同步。
具有可用性区域的所有Azure区域都支持区域冗余常规数据库。
区域冗余不适用于 DTU 购买模型中的基本和标准服务层级。
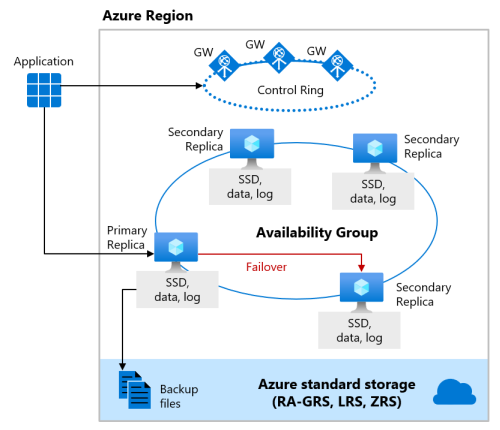
“高级”和“业务关键”服务层级
为高级或业务关键服务层启用区域冗余时,副本放置在同一区域的不同可用性区域中。 若要消除单一故障点,还要将控件环跨区域地复制为三个网关环 (GW)。 到特定网关通道的路由由 Azure Traffic Manager 控制。 由于高级或业务关键服务层级中的区域冗余配置使用其现有副本来放置在不同的可用性区域中,因此无需额外付费即可启用它。 通过选择区域冗余配置,可以使“高级”或“业务关键”数据库和弹性池能够应对范围要广得多的故障(包括灾难性的数据中心服务中断),且不会对应用程序逻辑进行任何更改。 还可以将所有现有“高级”或“业务关键”数据库或弹性池转换到区域冗余配置。
业务关键服务层级的高可用性体系结构的区域冗余版本如下图所示:两个区域或三个区域区域:
| 双区域区域 | 三区域区域 |
|---|---|

|

|
当计算资源被分布在两个可用性区域时:
- 对于业务关键存储,数据和日志文件的本地冗余可用性存储跨两个可用性区域同步。
- 对于其他层,备份和存储跨区域中的三个可用性区域同步。
- 区域冗余存储与往常一样,跨三个可用性区域同步。
在三个可用区内预配计算资源时:
- 对于业务关键存储,数据和日志文件的本地冗余可用性存储跨三个可用性区域同步。
- 对于其他层,备份和存储跨区域中的三个可用性区域同步。
配置具有区域冗余的高级或业务关键数据库时,请考虑以下事项:
- 所有支持可用性区域的 Azure 区域均支持区域冗余的高级版数据库和业务关键型数据库。
“超大规模”服务层级
可以在“超大规模”服务层级中为数据库配置区域冗余。 若要了解详细信息,请查看 创建区域冗余超大规模数据库。
启用此配置可确保通过在各个可用区之间进行复制来实现区域级复原能力,从而确保所有超大规模架构层的可靠性。 通过选择区域冗余,可以使“超大规模”数据库能够灵活应对范围要广得多的故障(包括灾难性的数据中心服务中断),且不会对应用程序逻辑进行任何更改。
下图演示了区域冗余超大规模数据库的基础体系结构,位于两个区域或三个区域区域:
| 双区域区域 | 三区域区域 |
|---|---|

|

|
当计算资源被分布在两个可用性区域时:
- 备份和存储跨区域中的三个可用性区域同步。
- 区域冗余存储与往常一样,跨三个可用性区域同步。
在三个可用区内预配计算资源时:
- 备份和存储跨区域中的三个可用性区域同步。
请考虑以下限制:
具有可用性区域的所有Azure区域都支持区域冗余超大规模数据库。
区域冗余配置只能在数据库创建期间指定。 预配资源后将无法修改此设置。 使用数据库复制、时间点还原,或创建异地副本来更新现有“超大规模”数据库的区域冗余配置。 使用这些更新选项之一时,如果目标数据库位于与源不同的区域,或者如果目标的数据库备份存储冗余与源数据库不同,那么复制操作将是一个数据量大小的操作。
目前使用 Azure 门户将数据库迁移到 Hyperscale 时,无法指定区域冗余。 但是,将现有数据库从另一个Azure SQL Database服务层迁移到“超大规模”时,可以使用Azure PowerShell、Azure CLI或 REST API 指定区域冗余。 下面是Azure CLI的示例:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant true`至少需要一个高可用性计算副本,并使用区域冗余或异地区域冗余备份存储来启用超大规模区域冗余配置。
数据库区域冗余可用性
在 Azure SQL Database 中,server 是充当数据库集合的中心管理点的逻辑构造。 在服务器级别,可以管理登录名、身份验证方法、防火墙规则、审核规则、威胁检测策略和故障转移组。 与其中某些功能(如登录和防火墙规则)相关的数据存储在 master 数据库中。 同样,某些 DMV(例如 sys.resource_stats)的数据也存储在 master 数据库中。
在逻辑服务器上创建具有区域冗余配置的数据库时,与服务器关联的 master 数据库也会自动成为区域冗余。 这可确保在发生区域中断时,使用数据库的应用程序仍然不受影响,因为依赖于 master 数据库的功能(如登录名和防火墙规则)仍然可用。 使 master 数据库成为区域冗余是一个异步过程,需要一些时间才能在后台完成。
如果服务器上的所有数据库均不是区域冗余,或者创建了空服务器,那么与该服务器关联的 master 数据库并非区域冗余。 若要迁移Azure SQL Database以使用区域冗余,请按照 Migrate Azure SQL Database 中的步骤迁移到可用性区域支持。
若要检查 ZoneRedundant 数据库的 master 属性,请使用 Azure PowerShell 或 Azure CLI 或 REST APIValidate Azure SQL Database 可用性区域状态中的步骤。
测试应用程序的故障复原能力
高可用性是 SQL 数据库平台的基本功能,其运作对数据库应用程序透明。 不过,我们认识到,你可能需要先测试在计划内或计划外事件期间启动的自动故障转移操作对应用程序的具体影响,然后才会将其部署到生产环境。 可以通过调用特殊 API 重启数据库或弹性池来手动触发故障转移。 在使用区域冗余无服务器或预配常规用途数据库或弹性池的情况下,API 调用会导致将客户端连接重定向到与旧主节点的可用性区域不同的可用性区域中的新主节点。 因此,除了测试故障转移对现有数据库会话的影响外,还可以验证它是否会由于网络延迟的变化而改变了端到端性能。 由于重启操作会干扰系统,其数量过多可能会对平台造成压力,因此每个数据库或弹性池每 15 分钟只能进行一次故障转移调用。
有关Azure SQL Database高可用性和灾难恢复的详细信息,请查看 高可用性和灾难恢复清单 - Azure SQL Database。
启动故障转移可以使用 PowerShell、REST API 或 Azure CLI:
| 部署类型 | PowerShell | REST API | Azure CLI | 门户(预览版) |
|---|---|---|---|---|
| 数据库 | Invoke-AzSqlDatabaseFailover | 数据库故障转移 | az rest可用于从Azure CLI调用 REST API 调用 | 设置 > 维护 > 重启 |
| 弹性池 | Invoke-AzSqlElasticPoolFailover | 弹性池故障转移 | az rest可用于从Azure CLI调用 REST API 调用 | 设置 > 维护 > 重启 |
重要
故障转移命令不适用于超大规模数据库的可读次要副本。
结论
Azure SQL Database提供与 Azure 平台深度集成的内置高可用性解决方案。 它依赖于 Service Fabric 进行故障检测和恢复,并利用 Azure Blob 存储进行数据保护,以及利用 Availability Zones 提高容错能力。 此外,SQL 数据库使用来自 SQL Server 的 Always On 可用性组技术来进行数据同步和故障转移。 将这些技术相结合,应用程序可完全实现混合存储模型的优势并支持最严格的 SLA。