Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
通过提供预配的吞吐量模型,Azure Cosmos DB 提供任何规模的可预测性能。 提前预留或配置吞吐量可以消除性能上的“干扰性邻居效应”。 指定所需的确切吞吐量,Azure Cosmos DB 保证 SLA 支持的已配置的吞吐量。
可以从 400 RU/秒的最低吞吐量着手,今后可以扩展到每秒数千万个请求或更高的吞吐量。 针对 Azure Cosmos DB 容器或数据库发出的每个请求(例如读取请求、写入请求、查询请求、存储过程)都有相应的成本,从预配的吞吐量中扣除。 如果预配 400 RU/秒的吞吐量并发出成本为 40 RU 的查询,则每秒可以发出 10 个此类查询。 超过该限制的任何请求会受到速率限制,应重试该请求。 如果使用客户端驱动程序,它们支持自动重试逻辑。
可以针对数据库或容器预配吞吐量,每个策略可以帮助你根据方案节省成本。
在不同的级别通过预配吞吐量进行优化
如果针对某个数据库预配吞吐量,该数据库中的所有容器(例如集合/表/图形)可以基于负载共享该吞吐量。 在数据库级别预留的吞吐量将会根据特定容器集上的工作负荷以不均匀的方式进行共享。
如果为某个容器预配吞吐量,则该容器的吞吐量是有保障的,并由服务等级协议(SLA)支持。 所选的逻辑分区键对于在容器的所有逻辑分区之间均匀分配负载至关重要。 有关更多详细信息,请参阅分区和水平缩放文章。
下面是确定预配吞吐量策略时可以参考的一些指导原则:
请考虑为 Azure Cosmos DB 数据库(包含一组容器)预配吞吐量,如果:
有几十个Azure Cosmos DB 容器,并且想要跨部分或全部容器共享吞吐量。
要从设计为在 IaaS 托管的 VM 或本地上运行的单租户数据库(例如 NoSQL 或关系数据库)迁移到 Azure Cosmos DB。 有许多集合/表/图形,并且不想要对数据模型进行任何更改。 请注意,如果从本地数据库迁移时未更新数据模型,则可能需要损害 Azure Cosmos DB 提供的一些优势。 建议经常重新评估数据模型,以获得最大性能并优化成本。
在数据库级别通过汇聚的吞吐量来处理工作负荷中计划外的意外高峰。
不针对单个容器设置特定的吞吐量,而是考虑如何在数据库中的一组容器之间获得聚合吞吐量。
对于以下情况,考虑针对单个容器预配吞吐量:
您有几个 Azure Cosmos DB 容器。 由于 Azure Cosmos DB 与架构无关,因此容器可以包含具有异类架构的项,并且不需要客户为每个实体创建多个容器类型。 如果将 10 到 20 个容器合并为一个容器是合理的,那么始终可以考虑这种做法。 如果容器的最低吞吐量为 400 RU,则将所有 10 到 20 个容器组建成一个池可能更具成本效益。
想对特定容器的吞吐量进行控制,并使给定的容器获得以 SLA 为保障的有保证的吞吐量。
考虑混合上面两种策略:
如前所述,Azure Cosmos DB 允许混合和匹配上述两种策略,因此现在可以在 Azure Cosmos DB 数据库中拥有一些容器,该容器可以共享数据库预配的吞吐量,以及同一数据库中的某些容器,这些容器可能具有专用的预配吞吐量。
可以应用上述策略来实现混合配置,在该配置中,您既可以有数据库级别的预配置吞吐量,也可以让某些容器拥有专用的吞吐量。
如下表所示,根据所选的 API,可以以不同的粒度配置吞吐量。
| API | 对于共享吞吐量,请进行配置 | 对于专用吞吐量,请配置 |
|---|---|---|
| 用于 NoSQL 的 API | 数据库 | 容器 |
| Azure Cosmos DB 的用于 MongoDB 的 API | 数据库 | 集合 |
| 用于 Cassandra 的 API | 密钥空间 | 表 |
| 用于 Gremlin 的 API | 数据库帐户 | Graph |
| 表 API | 数据库帐户 | 表 |
在不同的级别预配吞吐量可以根据工作负荷特征优化成本。 如前所述,随时能够以编程方式针对单个容器或者同时针对一组容器增加或减少预配的吞吐量。 根据工作负荷的变化弹性缩放吞吐量,只需为配置的吞吐量付费。 如果单个容器或一组容器分布在多个区域之间,则所有区域都能保证提供针对这些容器配置的吞吐量。
使用请求的速率限制进行优化
对于不易受延迟影响的工作负荷,可以预配更低的吞吐量,并在实际吞吐量超过预配的吞吐量时,让应用程序处理速率限制。 服务器将抢先结束出现 RequestRateTooLarge(HTTP 状态代码 429)的请求并返回 x-ms-retry-after-ms 标头,该标头指示重试请求之前用户必须等待的时间长度(以毫秒为单位)。
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK 中的重试逻辑
本机 SDK(.NET/.NET Core、Java、Node.js 和 Python)隐式捕获此响应,遵循服务器指定的重试标头,然后重试请求。 除非多个客户端同时访问你的帐户,否则下次重试将会成功。
如果累计有多个客户端一贯在超过请求速率的情况下运行,则当前设置为 9 的默认重试计数可能并不足够。 在这种情况下,客户端会向应用程序抛出RequestRateTooLargeException并返回状态代码429。 可以通过在 ConnectionPolicy 实例上设置 RetryOptions 来更改默认重试计数。 默认情况下,如果请求继续以高于请求速率的方式运行,则在 30 秒的累积等待时间后返回状态代码为 429 的 RequestRateTooLargeException。 即使当前的重试计数小于最大重试计数(默认值 9 或用户定义的值),也会发生这种情况。
MaxRetryAttemptsOnThrottledRequests 设置为 3,因此在这种情况下,如果请求操作由于超过容器的保留吞吐量而受到速率限制,该请求操作将在抛出异常给应用程序之前重试三次。 MaxRetryWaitTimeInSeconds设置为 60,因此在这种情况下,如果自第一个请求超过 60 秒以来的累积重试等待时间(以秒为单位)将引发异常。
ConnectionPolicy connectionPolicy = new ConnectionPolicy();
connectionPolicy.RetryOptions.MaxRetryAttemptsOnThrottledRequests = 3;
connectionPolicy.RetryOptions.MaxRetryWaitTimeInSeconds = 60;
分区策略和预配的吞吐量成本
良好的分区策略对于优化 Azure Cosmos DB 中的成本非常重要。 确保通过存储指标监测到的分区不存在倾斜。 确保分区的吞吐量不存在偏斜,这可以通过吞吐量指标来观察。 确保特定的分区键不存在偏斜。 存储中的主密钥通过指标呈现,但密钥取决于应用程序的访问模式。 最好考虑合适的逻辑分区键。 良好的分区键预期具有以下特征:
选择一个能在所有分区间和时间上均匀分散工作负荷的分区键。 换而言之,不应将某些键用于大部分数据,而将其他键用于少量或无数据。
选择一个分区键,使访问模式在逻辑分区中均匀分布。 工作负荷在所有键之间合理均衡分布。 换而言之,大部分工作负荷不应注重于少数几个特定键。
选择具有宽广值范围的分区键。
基本思路是将容器中的数据和活动分散到逻辑分区集合中,这样数据存储和吞吐量的资源便可以在这些逻辑分区中均匀分配。 分区键的候选项可能包括经常在查询中显示为筛选器的属性。 通过在筛选器谓词中包含分区键,可以有效地路由查询。 使用此类分区策略可以大大简化预配吞吐量的优化。
设计较小的项目以提高吞吐量
给定操作的请求费用或请求处理成本与项的大小直接相关。 针对大项执行操作的成本比针对小项执行操作的成本要高一些。
数据访问模式
最好根据数据的访问频率将数据按逻辑分类。 通过将它分类为热数据、中等数据或冷数据,可以微调消耗storage和所需的吞吐量。 根据access的频率,可以将数据放入单独的容器(例如表、图形和集合),并微调预配的吞吐量以满足该数据段的需求。
此外,如果使用 Azure Cosmos DB,且你知道不会按某些特定的数据值进行搜索或很少访问它们,则应存储这些属性的压缩值。 使用此方法可以节省storage空间、索引空间和预配吞吐量,并降低成本。
通过更改索引策略进行优化
默认情况下,Azure Cosmos DB 自动为每个记录的每个属性编制索引。 这是为了简化开发,并确保跨许多不同类型的即席查询具有优异的性能。 如果你的大型记录包含数千个属性,购买吞吐量来为每个属性编制索引的做法可能并不有效,尤其是只针对其中的 10 个或 20 个属性运行查询时。 在接近于能够控制特定的工作负荷时,我们的指导原则是优化索引策略。 有关 Azure Cosmos DB 索引策略的完整详细信息,请参阅 here。
监视预配的吞吐量和消耗的吞吐量
可以监视预配的请求单位总数、速率限制的请求数以及Azure portal中已使用的 RU 数。 若要了解详细信息,请参阅 Analyze Azure Cosmos DB 指标。 下图显示了示例用量指标:
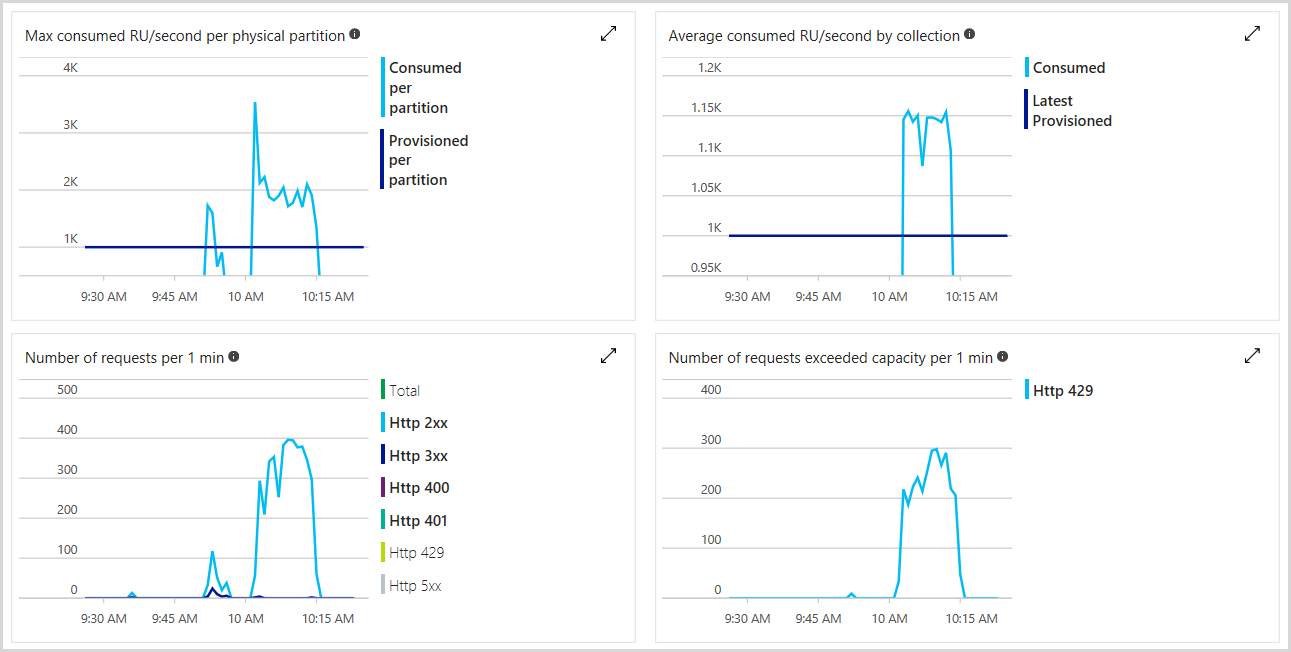 Azure 门户中
Azure 门户中
还可以设置警报,以检查受速率限制的请求数是否超过了特定阈值。 若要了解有关警报的详细信息,请参阅 Azure 监视警报。
按需弹性缩放吞吐量
由于你需要为预配的吞吐量付费,因此,使预配的吞吐量符合需要有助于避免未使用的吞吐量产生费用。 随时可以按需扩展或缩减预配的吞吐量。 如果吞吐量需求非常可预测,可以使用Azure Functions并使用计时器触发器按计划减少吞吐量。
监视 RU 消耗量以及受速率限制的请求比率可以发现,在整个一天或一周中,并不需要保持恒定的预配吞吐量。 在晚上或周末,收到的流量可能更少。 通过使用 Azure portal 或 Azure Cosmos DB 本机 SDK 或 REST API,可以随时缩放预配的吞吐量。 Azure Cosmos DB 的 REST API 提供终结点,用于以编程方式更新容器的性能级别,以便根据一天或一周中的时间直接调整代码的吞吐量。 执行此操作不会造成任何停机,通常在一分钟内就能产生效果。
应扩展吞吐量的其中一个场景是当您在数据迁移期间将数据引入 Azure Cosmos DB 时。 完成迁移后,可以缩减预配的吞吐量以处理解决方案的稳定状态。
请记住,将按一小时粒度计费,因此,如果以高于一小时的频率更改预配的吞吐量,则无法节省成本。
确定新工作负荷所需的吞吐量
若要确定新工作负荷的预配吞吐量,可使用以下步骤:
使用容量规划器执行初始粗略评估,并在 Azure portal 中通过 Azure Cosmos DB 浏览器的帮助来调整估算值。
建议使用超过预期的吞吐量创建容器,然后根据需要进行缩减。
建议使用原生的 Azure Cosmos DB SDK,从而在请求受到速率限制时自动重试以获得好处。 如果正在使用不支持的平台并使用 Azure Cosmos DB 的 REST API,请使用
x-ms-retry-after-ms标头实现自己的重试策略。确保应用程序代码正常支持所有重试都失败的情况。
你可以配置来自Azure portal的警报,以获取速率限制的通知。 一开始可以采用保守的限制,例如,过去 15 分钟有 10 个请求受到速率限制,然后在测算出实际消耗量之后,改用更激进的规则。 偶尔的限流是很好的,这表明你正在测试自己设置的限制,这正是你想要做的事情。
使用监视来了解流量模式,以便可以考虑是否需要动态调整一天或一周的吞吐量预配。
定期监视预配吞吐量与消耗吞吐量的比率,确保预配的容器和数据库不会超过所需的数目。 稍微超过预配的吞吐量是一种良好的安全措施。
有关优化预配吞吐量的最佳做法
以下步骤可帮助你在使用 Azure Cosmos DB 时实现高度可缩放且经济高效的解决方案。
如果容器和数据库明显超过预配的吞吐量,应该检查预配的 RU 和消耗的 RU,并微调工作负荷。
估算应用程序所需的保留吞吐量的一种方法是记录与针对应用程序使用的代表 Azure Cosmos DB 容器或数据库运行典型操作相关的请求单位 RU 费用,然后估计预计每秒执行的操作数。 同时请务必测量并包含典型查询及其用量。 若要了解如何以编程方式或使用门户估算查询的 RU 成本,请参阅优化查询成本。
获取操作及其 RU 成本的另一种方法是启用 Azure Monitor 日志,这将提供操作/持续时间的细分以及请求费用的详细信息。 Azure Cosmos DB 为每个操作提供请求费用,因此每个操作的费用都可以从响应中提取并存储,然后用于分析。
可按需弹性扩展和缩减预配的吞吐量,以适应工作负荷的需要。
可以根据需要添加和删除与 Azure Cosmos DB 帐户关联的区域并控制成本。
确保在容器的逻辑分区之间均匀分布数据和工作负荷。 如果分区分布不均,可能会导致预配的吞吐量高于所需的值。 如果你发现分布有偏斜,我们建议在分区之间均匀重新分布工作负荷,或者将数据重新分区。
如果有多个容器并且这些容器不需要 SLA,则对于每个容器吞吐量 SLA 不适用的情况,可以使用基于数据库的产品/服务。 应确定要迁移到数据库级别吞吐量提供的 Azure Cosmos DB 容器中的哪一个,然后使用基于更改馈送的解决方案迁移它们。
考虑对开发/测试方案使用可下载的 Cosmos DB 模拟器。 将这些选项用于开发/测试可以明显降低成本。
可以进一步执行工作负荷特定的成本优化 – 例如,增加批大小、对跨多个区域的读取操作进行负载均衡,以及删除重复数据(如果适用)。
后续步骤
接下来,可以阅读以下文章,详细了解 Azure Cosmos DB 中的成本优化:
- 尝试为迁移到 Azure Cosmos DB 做容量规划? 可以使用有关现有数据库群集的信息进行容量规划。
- 如果只知道现有数据库群集中的 vCore 和服务器数量,请阅读使用 vCore 或 vCPU 估算请求单位
- 如果您知道当前数据库工作负荷的典型请求速率,请阅读有关使用 Azure Cosmos DB 容量规划工具来估计请求单位的文章
- 详细了解开发和测试优化
- 详细了解 了解 Azure Cosmos DB 帐单
- 详细了解 优化存储成本
- 详细了解如何优化读取和写入成本
- 详细了解如何优化查询成本
- 详细了解 优化多区域Azure Cosmos DB 帐户的成本