Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
使用以下策略优化Azure Data Factory和Azure Synapse Analytics管道中映射数据流转换的性能。
优化联接、存在和查找
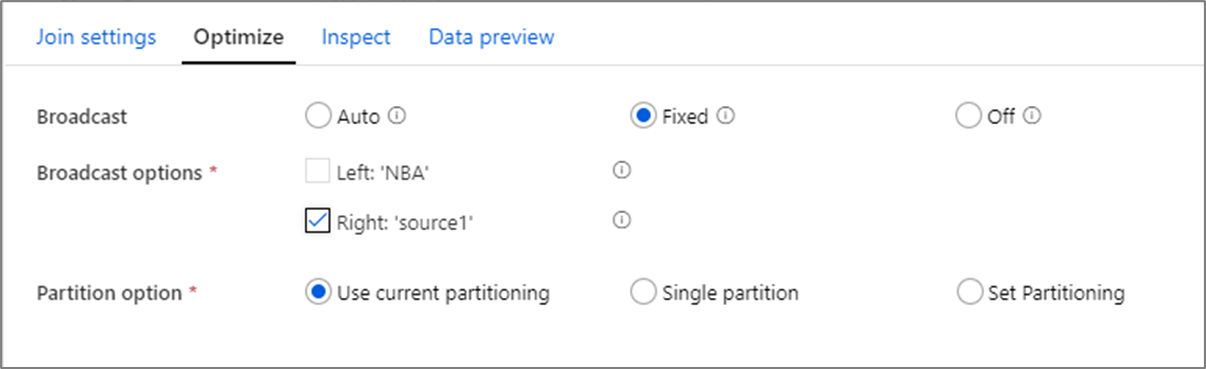
广播
在联接、查找和存在转换中,如果一个或两个数据流都足够小,足以容纳到工作节点内存中,可以通过启用 广播来优化性能。 广播是在将小型数据帧发送到群集中的所有节点时。 这样,Spark 引擎就可以执行联接,而无需在大数据流中重新排序数据。 默认情况下,Spark 引擎会自动决定是否广播联接的一端。 如果你熟悉传入的数据,并且知道一个流比另一个流小,则可以选择使用固定广播。 修复了广播强制 Spark 广播所选流。
如果广播数据的大小对于 Spark 节点太大,则可能会出现内存不足错误。 若要避免内存不足错误,请使用 内存优化 群集。 如果在数据流执行期间遇到广播超时,则可以关闭广播优化。 但是,这会导致执行数据流的速度变慢。
使用可能需要较长时间查询的数据源(如大型数据库查询)时,建议在连接操作中关闭广播功能。 当群集尝试广播到计算节点时,具有较长查询时间的源可能会导致 Spark 超时。 关闭广播的另一个不错的选择是,在数据流中有一个流,该流聚合值供以后在查找转换中使用。 此模式可能会混淆 Spark 优化器并导致超时。
交叉联接
如果在联接条件中使用文本值或在联接的两侧有多个匹配项,Spark 将联接作为交叉联接运行。 交叉联接是一个完整的笛卡尔积,然后筛选出联接的值。 这比其他联接类型慢。 确保联接条件的两侧都有列引用,以避免性能影响。
联接前排序
与 SSIS 等工具中的合并联接不同,联接转换不是强制性的合并联接操作。 联接键不需要在转换之前进行排序。 不建议在映射数据流中使用排序转换。
窗口转换性能
映射数据流中的窗口转换根据您在转换设置中作为over()子句一部分选择的列值来划分数据。 在Windows转换中公开了许多常用的聚合和分析函数。 但是,如果您的用例是在整个数据集上生成窗口以进行排名 rank() 或行号 rowNumber(),建议您使用 排名转换 和 代理键转换。 这些转换使用这些函数再次执行更好的完整数据集操作。
重新分区倾斜的数据
某些转换(如联接和聚合)会重新分配数据分区,有时可能会导致数据偏斜。 数据倾斜意味着数据在分区中分布不均。 严重偏斜的数据可能导致下游转化和数据写入速度变慢。 可以通过单击监视显示中的转换,在数据流运行的任何时间点检查数据的偏差。
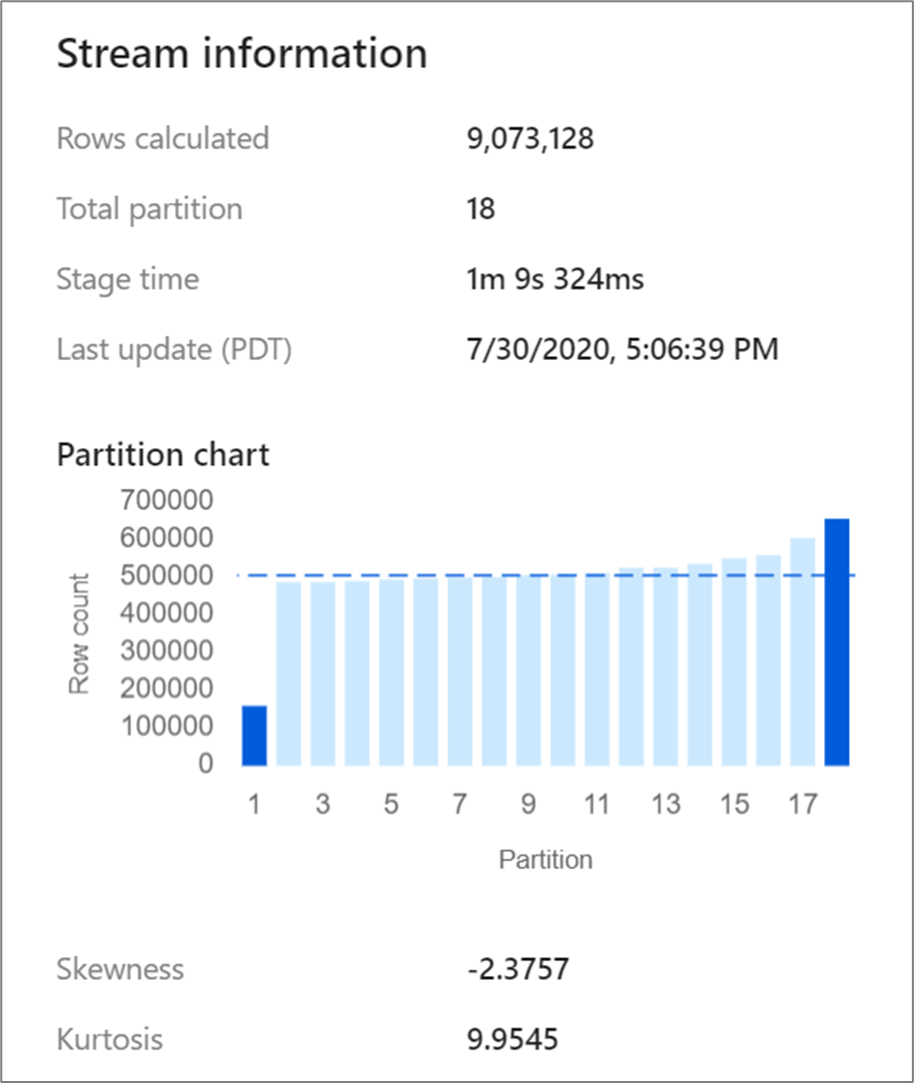
监视屏幕显示数据如何分布到每个分区,并包括两个指标:偏斜度和峰度。 偏斜 是一个度量值,用于衡量数据的不对称程度,并且可以具有正值、零值、负值或未定义值。 负倾斜意味着左尾比右侧长。 Kurtosis 是一种用于衡量数据分布是否具有重尾或轻尾特征的指标。 不需要高结度值。 理想的偏斜范围介于 -3 和 3 之间,而库尔特病范围小于 10。 解释这些数字的一种简单方法是查看分区图表,并查看 1 条是否大于其余条形图。
如果在转换后未均匀分区数据,则可以使用 “优化”选项卡 重新分区。 重新调整数据需要一些时间,并且可能无法提高数据流性能。
小窍门
如果您重新分区数据,但有下游转换会重新洗牌数据,建议在用作连接键的列上使用哈希分区。
注释
数据流中的变换(接收器变换除外)不会修改静态存储的数据的文件和文件夹的分区结构。 每个转换中的分区会将数据重新分区到 ADF 为每个数据流执行管理的临时无服务器 Spark 群集的数据帧内。
相关内容
请参阅与性能相关的其他Data Flow文章: