Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
使用Data Flow活动通过映射数据流转换和移动数据。 如果不熟悉数据流,请参阅 Mapping Data Flow 概述
使用 UI 创建数据流任务
若要在管道中使用Data Flow活动,请完成以下步骤:
在“管道活动”窗格中搜索 Data Flow,并将Data Flow活动拖动到管道画布。
如尚未选择画布上的新数据流活动,请选择它并打开Settings选项卡以编辑详细信息。
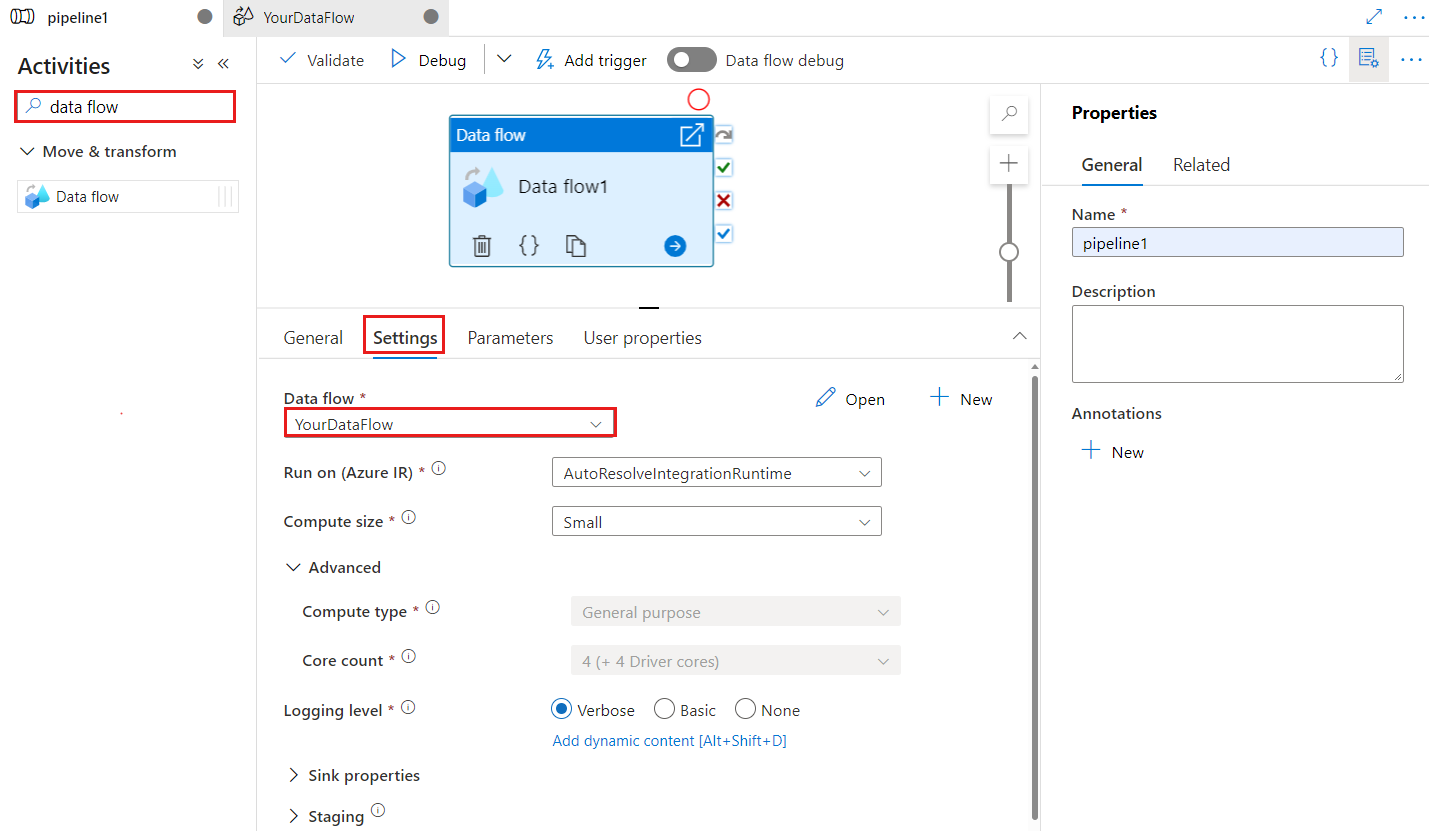
当数据流用于变更数据捕获时,检查点键用于设置检查点。 可以覆盖它。 数据流活动使用 GUID 值作为检查点的关键,而不是“管道名称 + 活动名称”,以便即使进行了重命名操作,它也可以始终跟踪客户的更改数据捕获状态。 所有现有数据流活动都使用旧模式键实现后向兼容性。 发布启用了更改数据捕获功能的数据流资源的新数据流活动后,其检查点键选项如下所示。
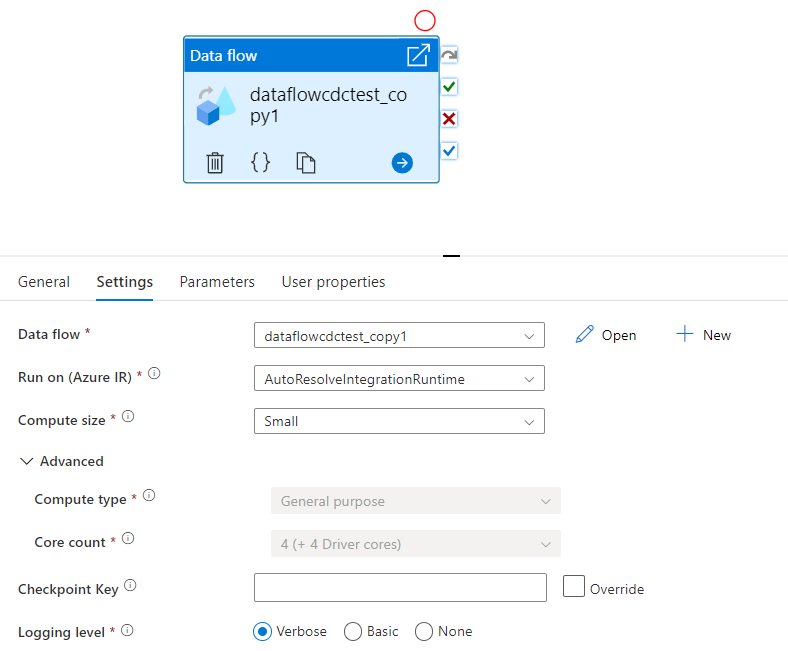
选择现有数据流,或使用“新建”按钮创建一个新数据流。 选择所需的其他选项以完成配置。
语法
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Type属性
| 属性 | 说明 | 允许的值 | 必须 |
|---|---|---|---|
| 数据流 | 对正在执行的Data Flow的引用 | DataFlowReference | 是 |
| integrationRuntime | 运行数据流的计算环境。 如果未指定,将使用自动解析的 Azure 集成运行时。 | IntegrationRuntimeReference | 否 |
| compute.coreCount | Spark 群集中使用的内核数。 仅当使用 autoresolve Azure Integration Runtime 时,才能指定 | 8、16、32、48、80、144、272 | 否 |
| 计算.计算类型 | Spark 群集中使用的计算类型。 仅当使用 autoresolve Azure Integration Runtime 时,才能指定 | “常规” | 否 |
| staging.linkedService | 如果您正在使用 Azure Synapse Analytics 源或汇聚,请指定用于 PolyBase 暂存的存储帐户。 如果您的 Azure 存储配置了 VNet 服务终结点,则必须在存储帐户上启用托管身份验证,并且勾选“允许信任的 Microsoft 服务通过”选项。请参阅 使用 VNet 服务终结点对 Azure 存储的影响。 另请分别了解 Azure Blob 和 Azure Data Lake Storage Gen2 所需的配置。 |
LinkedServiceReference | 仅当数据流读取或写入Azure Synapse Analytics |
| staging.folderPath | 如果您正在使用 Azure Synapse Analytics 数据源或汇,则在 Blob 存储帐户中用于 PolyBase 暂存的文件夹路径 | 字符串 | 仅当数据流读取或写入Azure Synapse Analytics |
| traceLevel | 设置数据流活动执行的日志记录级别 | 精细、粗略、无 | 否 |
在运行时动态调整数据流计算资源配置
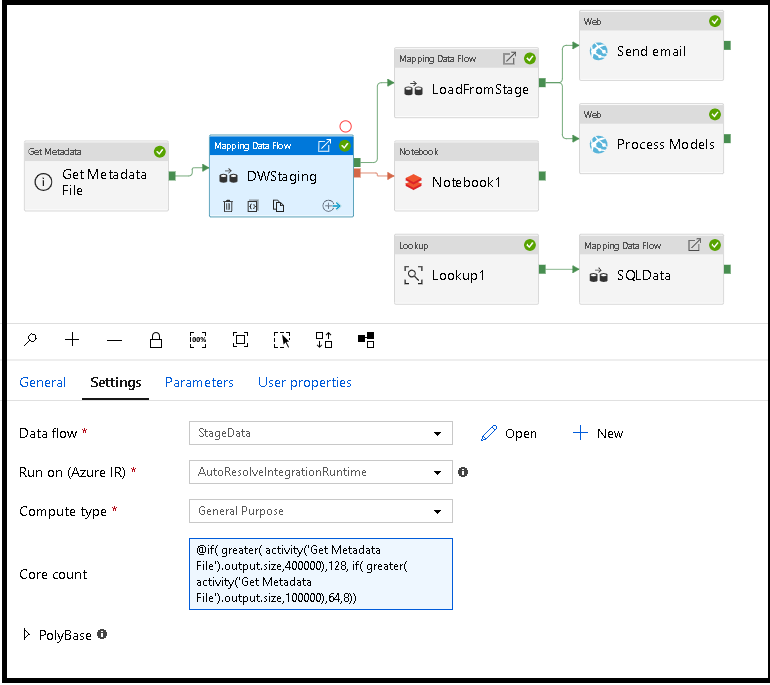
可以动态设置“核心计数”和“计算类型”属性,以在运行时调整传入源数据的大小。 使用管道活动(例如“查找”或“获取元数据”),以便查找源数据集数据的大小。 然后,在Data Flow活动属性中使用“添加动态内容”。 可以选择小、中或大计算大小。 (可选)选择“自定义”并手动配置计算类型和核心数。
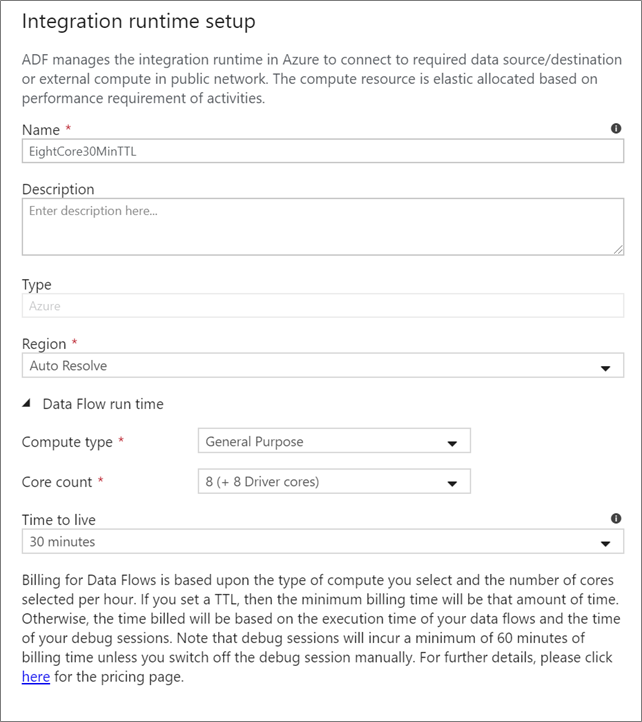
Data Flow集成运行时
选择要用于Data Flow活动执行的Integration Runtime。 默认情况下,该服务使用 autoresolve Azure Integration Runtime 和四个辅助角色核心。 此 IR 具有常规用途计算类型,并在与服务实例相同的区域中运行。 对于操作化管道,强烈建议创建自己的 Azure Integration Runtime,用于定义数据流活动执行的特定区域、计算类型、核心计数和 TTL。
对于大多数生产工作负载,建议至少使用一个具有 8+8(总计 16)个 v-Core 配置和 10 分钟生存时间的“常规用途”计算类型。 通过设置较小的 TTL,Azure IR 可以保持热群集,从而避免冷群集启动时需耗费几分钟的等待时间。 有关详细信息,请参阅 Azure 集成运行时。
重要
Data Flow活动中的Integration Runtime选择仅适用于将管道触发执行。 调试您的管道时,数据流将在调试会话中指定的群集上运行。
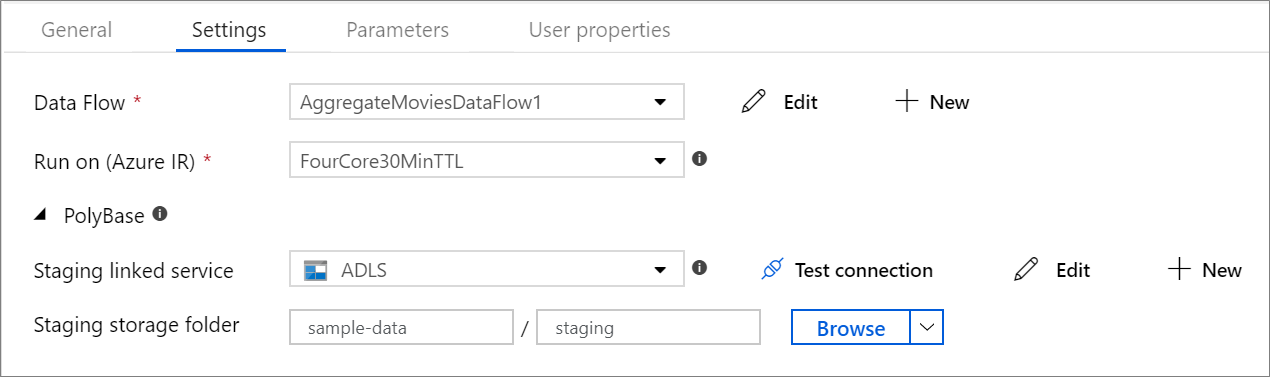
PolyBase
如果使用 Azure Synapse Analytics 作为汇集或源时,必须为 PolyBase 批处理加载选择暂存位置。 PolyBase 允许批量加载而不是逐行加载数据。 PolyBase 将加载时间大幅减少到Azure Synapse Analytics。
检查点键
对数据流源使用更改捕获选项时,ADF 会自动维护和管理检查点。 默认检查点键是数据流名称和管道名称的哈希。 如果对源表或文件夹使用动态模式,可能要替代此哈希并在此处设置自己的检查点键值。
日志记录级别
如果不需要数据流活动的每个管道执行过程完整地记录所有详细的遥测日志,可以选择性地将日志记录级别设置为“基本”或“无”。 在执行数据流时,如果使用“详细”(默认)模式,即表示您要求服务在数据转换期间完整记录每个分区级别的活动。 该操作成本昂贵,因此仅在进行故障排除时启用“详细”模式可优化整体数据流和管道性能。 “基本”模式仅记录转换持续时间,而“无”模式仅提供持续时间摘要。

接收器属性
数据流中的分组功能既可以设置接收器的执行顺序,又可以使用相同的组号将接收器分组在一起。 为帮助管理组,可以要求此服务在同一组中运行接收器,以并行运行。 您还可以将接收器组设置为,即使其中一个接收器出现错误时仍继续运行。
数据流接收器的默认行为是依次串行执行每个接收器,当接收器中遇到错误时终止数据流。 此外,默认情况下,所有接收器都被分配到同一组,除非您进入数据流属性并为接收器设置不同的优先级。

仅第一行
此选项仅适用于已为“输出到活动”启用了缓存接收器的数据流。 直接注入到管道中的数据流的输出限制为 2MB。 设置“仅第一行”有助于在将数据流活动输出直接注入到管道时限制来自数据流的数据输出。
将数据流参数化
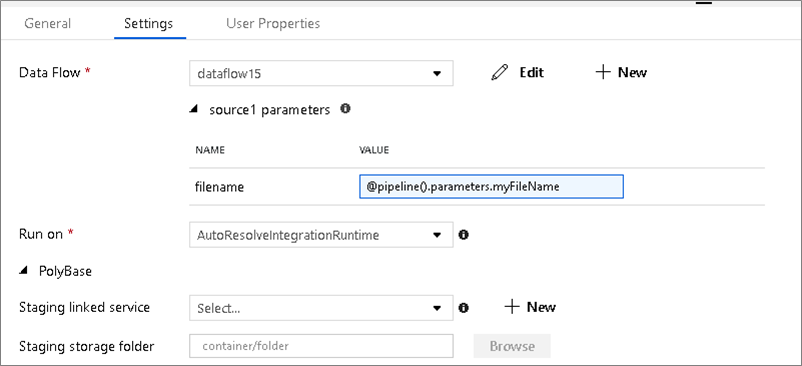
参数化数据集
如果数据流使用参数化数据集,请在“设置”选项卡中设置参数值。
参数化数据流
如果数据流已参数化,请在“参数”选项卡中设置数据流参数的动态值。可以使用管道表达式语言或数据流表达式语言来分配动态或文字参数值。 有关详细信息,请参阅 Data Flow Parameters。
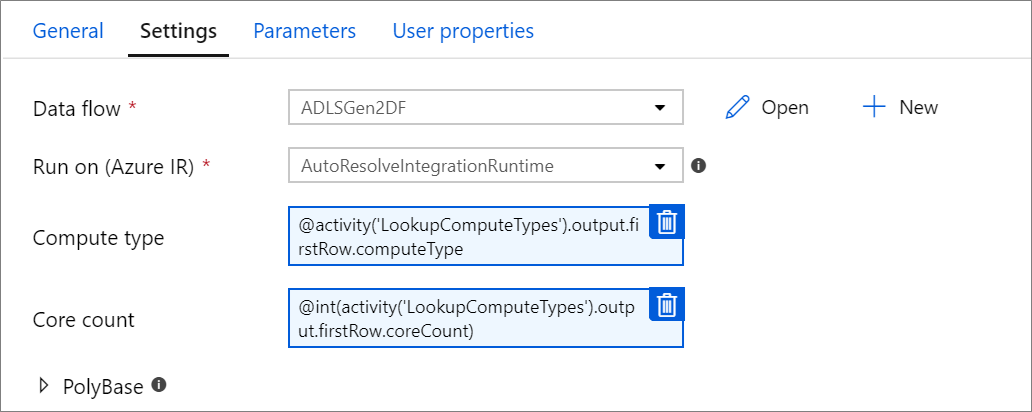
参数化计算属性。
如果使用 autoresolve Azure Integration Runtime 并指定 compute.coreCount 和 compute.computeType 的值,则可以参数化核心计数或计算类型。
Data Flow活动的管道调试
若要使用 Data Flow 活动来执行调试管道运行,必须通过顶部栏上的 Data Flow Debug 滑块打开 Data Flow 调试模式。 调试模式允许您在活跃的 Spark 集群上运行数据流。 有关详细信息,请参阅调试模式。

调试管道针对活动调试群集运行,而不是在Data Flow活动设置中指定的集成运行时环境。 在启动调试模式时,可以选择调试计算环境。
监控数据流活动
Data Flow活动具有特殊的监视体验,可在其中查看分区、阶段时间和数据世系信息。 通过“操作”下的眼镜图标打开监视窗格。 有关详细信息,请参阅监视数据流。
在后续活动中使用“数据流”活动结果
数据流活动输出有关写入每个接收器的行数和从每个源读取的行数的指标。 这些结果将在活动运行结果的 output 部分中返回。 返回的指标采用以下 json 格式。
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
例如,要获取在名为“dataflowActivity”的活动中写入接收器“sink1”的行数,可使用 @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten。
要获取从该接收器中使用的源“source1”读取的行数,可使用 @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead。
注意
如果接收器写入的行数为零,则它将不会显示在指标中。 可以使用 contains 函数来验证存在性。 例如,contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') 检查是否有任何行被写入 sink1。
相关内容
参阅支持的控制流活动: