Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
架构偏差是指源经常更改元数据。 可以动态添加、删除或更改字段、列和类型。 如果不处理架构偏差,当上游数据源发生更改时,数据流就很容易受到影响。 当传入的列和字段发生更改时,典型的 ETL 模式将会失败,因为它们往往绑定到这些源名称。
为了防范架构偏差,必须在数据流工具中提供相应的机制,使数据工程师能够:
- 定义具有可变字段名称、数据类型、值和大小的源
- 定义可以使用数据模式而不是硬编码字段和值的转换参数
- 定义可以识别与传入字段相匹配而不是使用命名字段的表达式
Azure 数据工厂本机支持随执行而变化的灵活架构,这样你就可以生成通用的数据转换逻辑,而无需重新编译数据流。
需要在数据流中做出体系结构方面的决策,使整个流接受架构偏差。 这样做可以防范源中发生架构更改。 但是,整个数据流中列和类型的前期绑定将会丢失。 Azure 数据工厂将架构偏差流视为后期绑定流,因此,当你生成转换时,整个流的架构视图中不会显示偏差列名。
源中的架构偏差
当源投影中不存在的列通过源定义进入数据流时,它们被定义为“偏差”。 可以从源转换的“投影”选项卡中查看源投影。 为源选择数据集时,该服务会自动从数据集中获取架构,并基于该数据集架构定义创建投影。
在源转换中,架构偏差定义为读取数据集架构中未定义的列。 若要启用架构偏差,请在源转换中选中“允许架构偏差”。
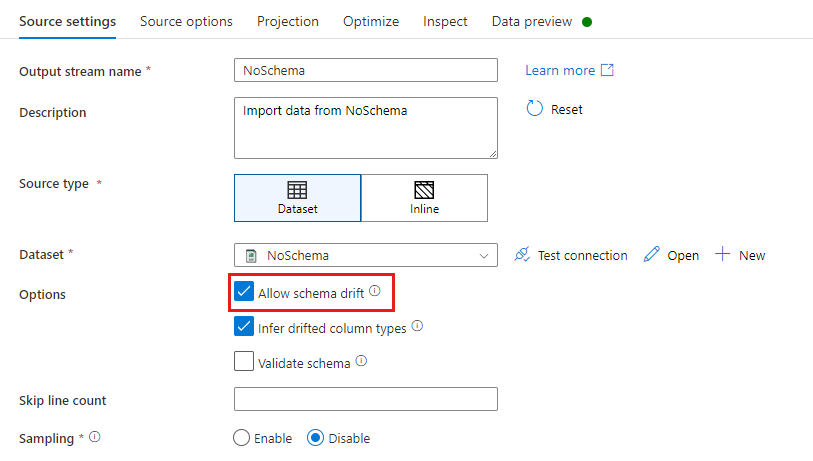
启用架构偏差后,将在执行过程中从源读取所有传入字段,并将其通过整个流传递到接收器。 默认情况下,所有新检测到的列(称为漂移列)将作为字符串数据类型到达。 如果希望数据流自动推断偏差列的数据类型,请在源设置中选中“推断偏差列类型”。
接收器中的架构偏差
在“汇流转换”中,模式漂移是指在汇流数据架构中定义的基础上额外写入新的列。 若要启用架构偏差,请在“接收器”转换中选中“允许架构偏差”。
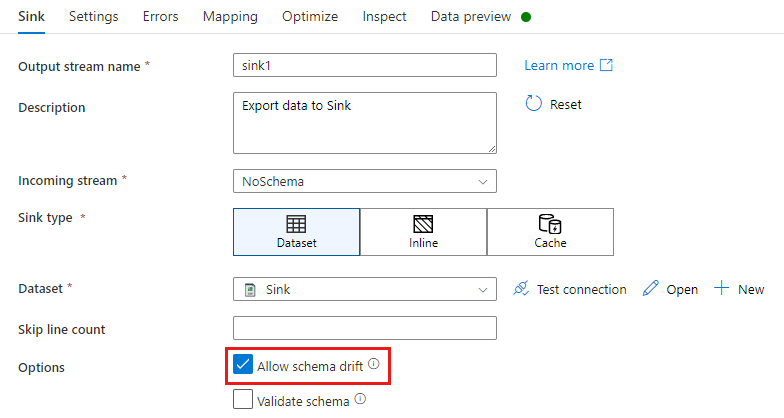
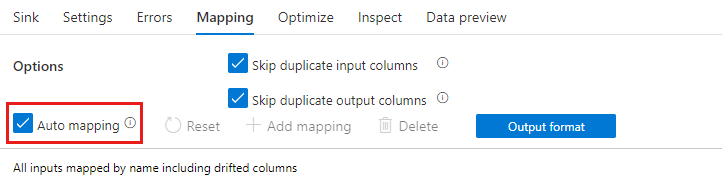
如果启用了架构偏差,请确保“映射”选项卡中的“自动映射”滑块处于开启状态。 开启此滑块时,所有传入列都将写入你的目标位置。 否则,必须使用基于规则的映射来写入偏差列。
转换偏差列
数据流包含偏差列时,可以使用以下方法在转换中访问这些列:
- 使用
byPosition和byName表达式按名称或位置号显式引用列。 - 在“派生列”或“聚合”转换中添加列模式,以匹配名称、流、位置、来源或类型的任何组合
- 在“选择”或“接收器”转换中添加基于规则的映射,以便通过模式将偏移列与列别名匹配
有关如何实现列模式的详细信息,请参阅映射数据流中的列模式。
映射偏移列快速操作
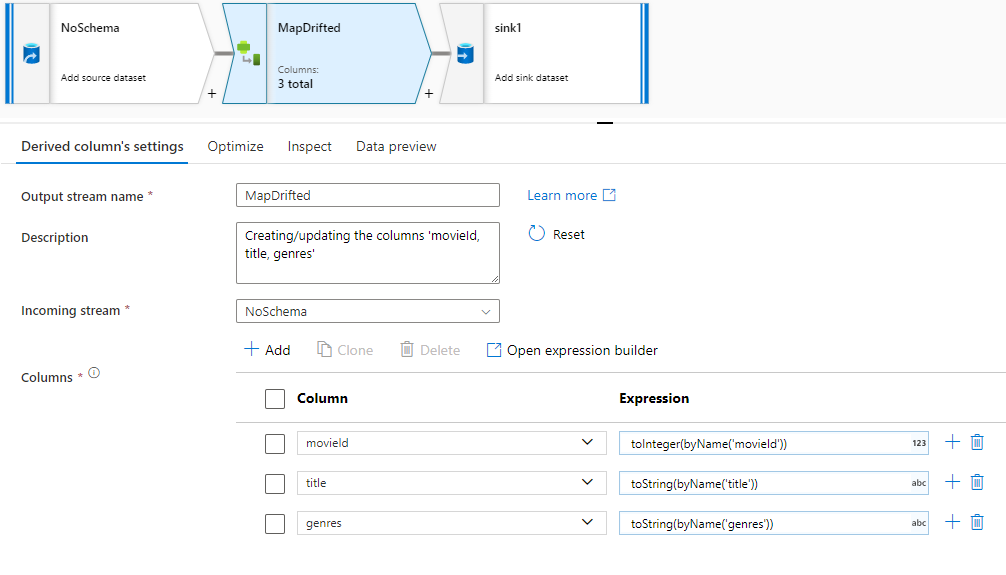
若要显式引用偏移列,可以通过数据预览快速操作快速生成这些列的映射。 调试模式开启后,转到“数据预览”选项卡,然后单击“刷新”以获取数据预览。 如果数据工厂检测到存在漂移的列,则可以单击“映射漂移”并生成一个派生列,以便在下游的模式视图中引用所有漂移的列。
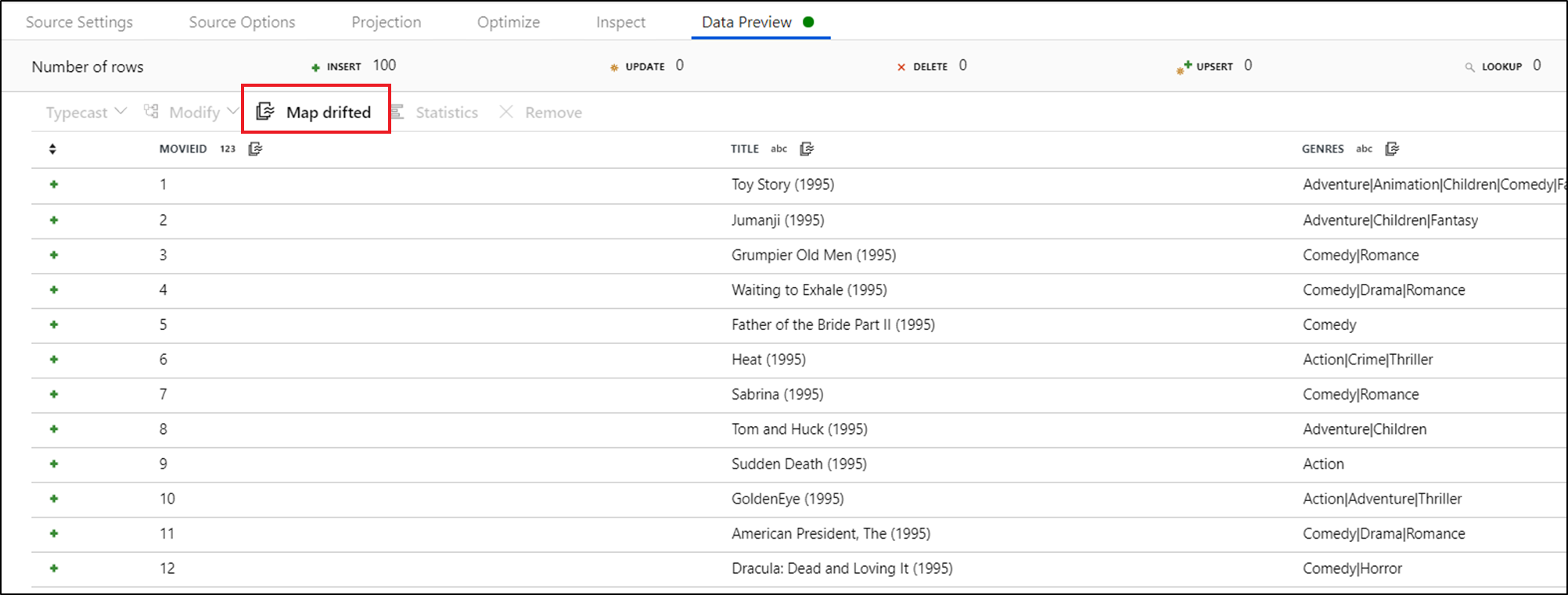
在生成的“派生列”转换中,每个偏差列都映射到其检测到的名称和数据类型。 在上述数据预览中,“movieId”列检测为整数。 单击“映射偏差”后,movieId 在“派生列”中定义为 ,并包含在下游转换的架构视图中toInteger(byName('movieId'))。
相关内容
在数据流表达式语言中,你将找到用于列模式和架构偏差的其他功能,包括“byName”和“byPosition”。