Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
本文概述了如何从 Oracle 云存储复制数据。 若要了解详细信息,请阅读
支持的功能
此 Oracle 云存储连接器支持以下功能:
| 支持的功能 | IR |
|---|---|
| 复制操作 (source/-) | (1) (2) |
| 查询活动 | (1) (2) |
| GetMetadata 活动 | (1) (2) |
| 删除活动 | (1) (2) |
(1) Azure集成运行时 (2) 自承载集成运行时
具体而言,此 Oracle 云存储连接器支持按原样复制文件,或者使用受支持的文件格式和压缩编解码器分析文件。 它利用 Oracle 云存储的 S3 兼容互操作性。
先决条件
若要从 Oracle 云存储复制数据,请参阅 此处,查看先决条件和所需权限。
入门
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建到 Oracle 云存储的链接服务
使用以下步骤在 Azure 门户 UI 中创建到 Oracle 云存储的链接服务。
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡,并选择“链接服务”,然后单击“新建”:
搜索“Oracle”并选择 Oracle 云存储连接器。
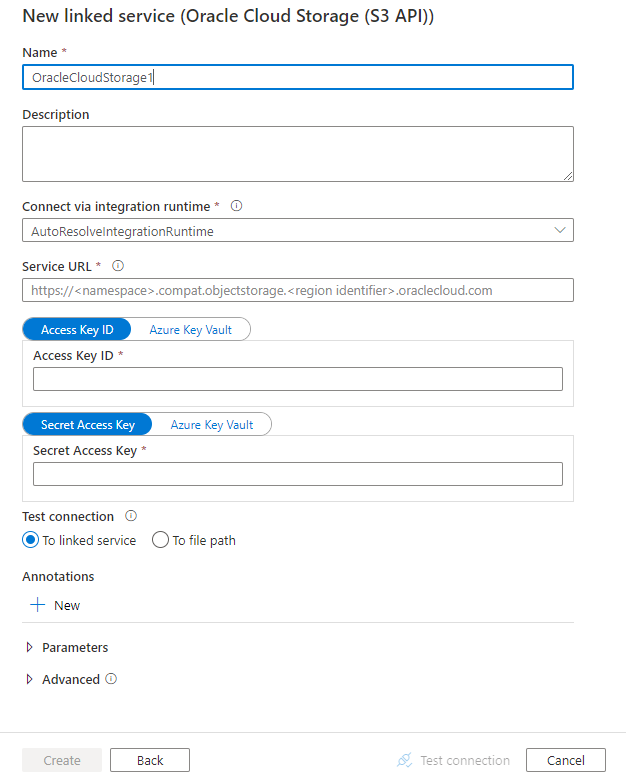
配置服务详细信息、测试连接并创建新的链接服务。
连接器配置详细信息
以下各部分详细介绍了定义特定于 Oracle 云存储的实体时使用的属性。
连接的服务属性
Oracle 云存储链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | “type”属性必须设置为“OracleCloudStorage”。 | 是 |
| accessKeyId | 机密访问键 ID。 若要查找访问密钥和机密,请参阅先决条件。 | 是 |
| secretAccessKey | 机密访问键本身。 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure 密钥保管库 中的机密。 | 是 |
| 服务URL | 将自定义终结点指定为 https://<namespace>.compat.objectstorage.<region identifier>.oraclecloud.com。 请参阅 此处 了解详细信息 |
是 |
| connectVia | 用于连接到数据存储的集成运行时。 可以使用Azure集成运行时或自承载集成运行时(如果数据存储位于专用网络中)。 如果未指定此属性,服务将使用默认Azure集成运行时。 | 否 |
下面是一个示例:
{
"name": "OracleCloudStorageLinkedService",
"properties": {
"type": "OracleCloudStorage",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"serviceUrl": "https://<namespace>.compat.objectstorage.<region identifier>.oraclecloud.com"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
Azure 数据工厂支持以下文件格式。 请参阅每一篇介绍基于格式的设置的文章。
在基于格式的数据集中的 location 设置下,Oracle 云存储支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集中 下的“type”属性必须设置为“OracleCloudStorageLocation”。 | 是 |
| 桶名称 | Oracle 云存储桶名称。 | 是 |
| folderPath | 给定存储桶下的文件夹路径。 如果要使用通配符来筛选文件夹,请跳过此设置并在活动源设置中进行相应的指定。 | 否 |
| 文件名 | 给定存储桶及文件夹路径下的文件名。 如果要使用通配符来筛选文件,请跳过此设置并在活动源设置中进行相应的指定。 | 否 |
示例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Oracle Cloud Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "OracleCloudStorageLocation",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
复制活动 属性
有关可用于定义活动的各部分和属性的完整列表,请参阅管道一文。 本部分提供 Oracle 云存储源支持的属性列表。
将 Oracle 云存储用作源类型
Azure 数据工厂支持以下文件格式。 请参阅每一篇介绍基于格式的设置的文章。
在基于格式的复制源中的 storeSettings 设置下,Oracle 云存储支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 下的“type”属性必须设置为“OracleCloudStorageReadSettings”。 | 是 |
| 找到要复制的文件: | ||
| 选项 1:静态路径 |
从数据集中指定的给定存储桶或文件夹/文件路径复制。 若要复制 Bucket 或文件夹中的所有文件,请另外将 wildcardFileName 指定为 *。 |
|
| 选项 2:Oracle 云存储前缀 -前缀 |
数据集中配置的给定存储桶下的 Oracle 云存储密钥名称的前缀,用于筛选源 Oracle 云存储文件。 选择名称以 bucket_in_dataset/this_prefix 开头的 Oracle 云存储密钥。 它利用 Oracle 云存储的服务端筛选器,相比通配符筛选器,服务端筛选器可提供更好的性能。 |
否 |
| 选项 3:通配符 - wildcardFolderPath |
数据集中配置的给定 Bucket 下包含通配符的文件夹路径,用于筛选源文件夹。 允许的通配符为: *(匹配零个或更多字符)和 ?(匹配零个或单个字符)。 如果您的文件夹名中含有通配符或此转义字符,请使用^进行转义。 请参阅文件夹和文件筛选器示例中的更多示例。 |
否 |
| 选项 4:通配符 - 通配符文件名 |
给定 Bucket 和文件夹路径(或通配符文件夹路径)下包含通配符的文件名,用于筛选源文件。 允许的通配符为: *(匹配零个或更多字符)和 ?(匹配零个或单个字符)。 如果文件名包含通配符或此转义字符,请使用 ^ 进行转义。 请参阅文件夹和文件筛选器示例中的更多示例。 |
是 |
| 选项 5:文件列表 - 文件列表路径 |
指明复制给定文件集。 指向包含要复制的文件列表的文本文件,每行一个文件(即数据集中所配置路径的相对路径)。 使用此选项时,请勿在数据集中指定文件名。 请参阅文件列表示例中的更多示例。 |
否 |
| 其他设置: | ||
| recursive | 指示是要从子文件夹中以递归方式读取数据,还是只从指定的文件夹中读取数据。 请注意,当将 recursive 设置为 true 且目标位置为基于文件的存储时,空的文件夹或子文件夹不会在目标位置被复制或创建。 允许的值为 true(默认值)和 false。 如果配置 fileListPath,则此属性不适用。 |
否 |
| 完成后删除文件 | 指示是否会在二进制文件成功移到目标存储后将其从源存储中删除。 文件删除按文件进行。因此,当复制活动失败时,你会看到一些文件已经复制到目标并从源中删除,而另一些文件仍保留在源存储中。 此属性仅在二进制文件复制方案中有效。 默认值:false。 |
否 |
| 修改日期时间起始 | 文件根据“上次修改时间”属性进行筛选。 如果文件的上次修改时间大于或等于 modifiedDatetimeStart 并且小于 modifiedDatetimeEnd,将选择这些文件。 该时间应用于 UTC 时区,格式为“2018-12-01T05:00:00Z”。 属性可以为 NULL,这意味着不向数据集应用任何文件属性筛选器。 如果 modifiedDatetimeStart 具有日期/时间值,但 modifiedDatetimeEnd 为 NULL,则会选中“上次修改时间”属性大于或等于该日期/时间值的文件。 如果 modifiedDatetimeEnd 具有日期/时间值,但 modifiedDatetimeStart 为 NULL,则会选中“上次修改时间”属性小于该日期/时间值的文件。如果配置 fileListPath,则此属性不适用。 |
否 |
| 修改日期时间结束 | 同上。 | 否 |
| enablePartitionDiscovery | 对于已分区的文件,请指定是否从文件路径分析分区,并将它们添加为附加的源列。 允许的值为 false(默认)和 true 。 |
否 |
| 分区根路径 | 启用分区发现时,请指定绝对根路径,以便将已分区文件夹读取为数据列。 如果未指定,则默认情况下, - 在数据集或源的文件列表中使用文件路径时,分区根路径是在数据集中配置的路径。 - 使用通配符文件夹筛选器时,分区根路径是第一个通配符前的子路径。 例如,假设你将数据集中的路径配置为“root/folder/year=2020/month=08/day=27”: - 如果将分区根路径指定为“root/folder/year=2020”,则除了文件内的列外,复制活动还将生成另外两个列 month 和 day,其值分别为“08”和“27”。- 如果未指定分区根路径,则不会生成额外的列。 |
否 |
| 最大并发连接数 (maxConcurrentConnections) | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
示例:
"activities":[
{
"name": "CopyFromOracleCloudStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "OracleCloudStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
文件夹和文件筛选器示例
本部分介绍使用通配符筛选器生成文件夹路径和文件名的行为。
| Bucket | 关键值 | recursive | 源文件夹结构和筛选器结果(用粗体表示的文件已检索) |
|---|---|---|---|
| Bucket | Folder*/* |
假 | Bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| Bucket | Folder*/* |
true | Bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| Bucket | Folder*/*.csv |
假 | Bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| Bucket | Folder*/*.csv |
true | Bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
文件列表示例
本部分介绍在复制活动源中使用文件列表路径的结果行为。
假设有以下源文件夹结构,并且要复制以粗体显示的文件:
| 示例源结构 | FileListToCopy.txt 中的内容 | 配置 |
|---|---|---|
| Bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv 元数据 FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
在数据集中: - 桶: bucket- 文件夹路径: FolderA在复制活动的源部分中: - 文件列表路径: bucket/Metadata/FileListToCopy.txt 文件列表路径指向同一数据存储中的一个文本文件,该文件包含要复制的文件列表,每行一个文件,其路径相对于数据集中配置的路径。 |
查找活动属性
若要了解有关属性的详细信息,请查看 Lookup 活动。
GetMetadata 活动属性
若要了解有关属性的详细信息,请查看 GetMetadata 活动。
删除活动属性
若要了解有关属性的详细信息,请查看删除活动。
相关内容
关于 复制活动 作为源和汇支持的数据存储列表,请参阅 支持的数据存储。