Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure 数据工厂
Azure 数据工厂  Azure Synapse Analytics
Azure Synapse Analytics
此快速入门介绍如何使用 PowerShell 创建 Azure 数据工厂。 在此数据工厂中创建的管道会将数据从 Azure Blob 存储中的一个文件夹复制到另一个文件夹。 有关如何使用 Azure 数据工厂转换数据的教程,请参阅教程:使用 Spark 转换数据。
注意
本文不提供数据工厂服务的详细介绍。 有关 Azure 数据工厂服务的介绍,请参阅 Azure 数据工厂简介。
先决条件
Azure 订阅
如果没有 Azure 订阅,请在开始前创建一个试用订阅。
Azure 角色
若要创建数据工厂实例,用于登录到 Azure 的用户帐户必须属于参与者或所有者角色,或者是 Azure 订阅的管理员。 若要查看你在订阅中拥有的权限,请转到 Azure 门户,在右上角选择你的用户名,然后选择“...” 图标以显示更多选项,然后选择“我的权限” 。 如果可以访问多个订阅,请选择相应的订阅。
若要为数据工厂创建和管理子资源(包括数据集、链接服务、管道、触发器和集成运行时),以下要求适用:
- 若要在 Azure 门户中创建和管理子资源,你必须属于资源组级别或更高级别的数据工厂参与者角色。
- 若要使用 PowerShell 或 SDK 创建和管理子资源,资源级别或更高级别的参与者角色已足够。
有关如何将用户添加到角色的示例说明,请参阅添加角色一文。
有关详细信息,请参阅以下文章:
Azure 存储帐户
在本快速入门中,使用常规用途的 Azure 存储帐户(具体的说就是 Blob 存储)作为源 和目标 数据存储。 如果没有常规用途的 Azure 存储帐户,请参阅创建存储帐户创建一个。
获取存储帐户名称
在本快速入门中,将需要 Azure 存储帐户的名称。 以下步骤可帮助您获取存储帐户的名称:
- 在 Web 浏览器中,转到 Azure 门户并使用你的 Azure 用户名和密码登录。
- 从 Azure 门户菜单中,选择“所有服务”,然后选择“存储”“存储帐户” 。 此外,也可以在任何页面中搜索和选择“存储帐户” 。
- 在“存储帐户”页中,筛选你的存储帐户(如果需要),然后选择它 。
此外,也可以在任何页面中搜索和选择“存储帐户” 。
创建 Blob 容器
本部分介绍如何在 Azure Blob 存储中创建名为 adftutorial 的 Blob 容器。
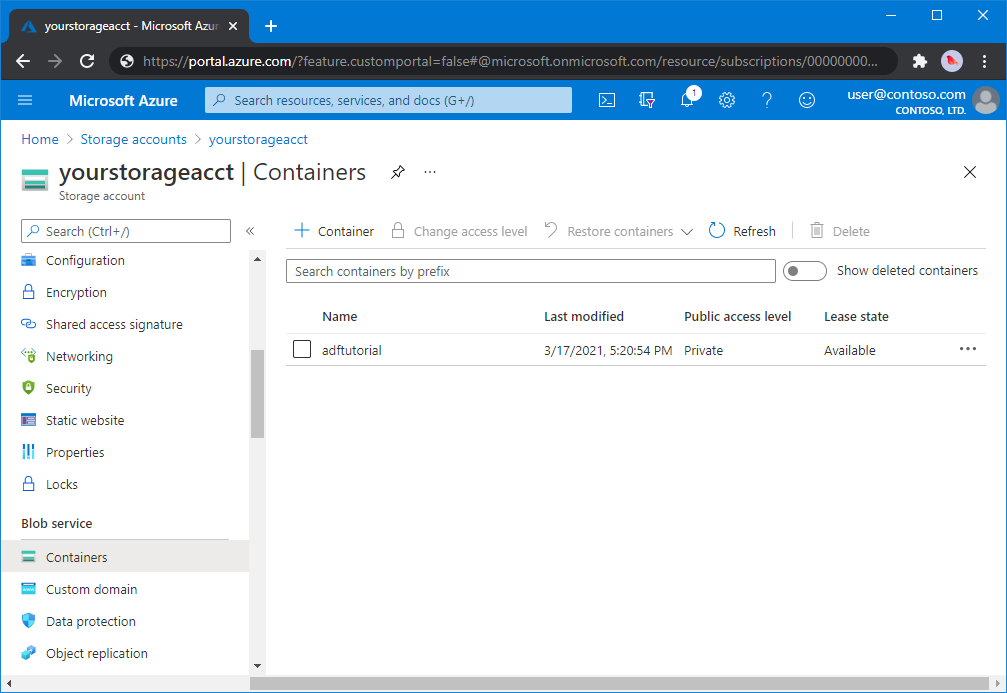
在“存储帐户”页上,选择“概述”“容器”。>
在“<帐户名称>”“容器”页的工具栏中,选择“容器” - 。
在“新建容器” 对话框中,输入 adftutorial 作为名称,然后选择“确定” 。 “<帐户名称>”“容器”页已更新为在容器列表中包含“adftutorial” - 。
为 Blob 容器添加输入文件夹和文件
在此部分中,在创建的容器中创建名为“input”的文件夹,再将示例文件上传到 input 文件夹。 在开始之前,打开文本编辑器(如记事本),并创建包含以下内容的名为“emp.txt”的文件 :
John, Doe
Jane, Doe
将此文件保存在 C:\ADFv2QuickStartPSH 文件夹中 。 (如果此文件夹不存在,则创建它。)然后返回到 Azure 门户并执行以下步骤:
在上次离开的“<Account name>”“容器”页中,选择已更新的容器列表中的“adftutorial” - 。
- 如果关闭了窗口或转到其他页,请再次登录到 Azure 门户。
- 从 Azure 门户菜单中,选择“所有服务”,然后选择“存储”“存储帐户” 。 此外,也可以在任何页面中搜索和选择“存储帐户” 。
- 选择您的存储帐户,然后依次选择容器>adftutorial。
在“adftutorial”容器页面的工具栏上,选择“上传” 。
在“上传 Blob”页面中,选择“文件”框,然后浏览到 emp.txt 文件,并进行选择。
展开“高级”标题。 此页现在显示如下内容:
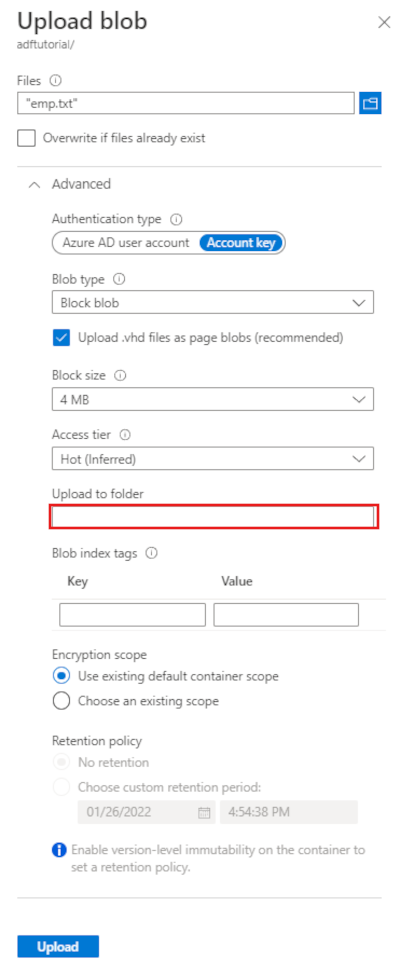
在“上传到文件夹”框中,输入“输入”。
选择“上传”按钮。 应该会在列表中看到 emp.txt 文件和上传状态。
选择“关闭”图标 (X) 以关闭“上传 Blob”页面。
让“adftutorial”容器页面保持打开状态 。 在本快速入门结束时可以使用它来验证输出。
Azure PowerShell
注意
建议使用 Azure Az PowerShell 模块与 Azure 交互。 请参阅安装 Azure PowerShell 以开始使用。 若要了解如何迁移到 Az PowerShell 模块,请参阅 将 Azure PowerShell 从 AzureRM 迁移到 Az。
按如何安装和配置 Azure PowerShell 中的说明安装最新的 Azure PowerShell 模块。
警告
如果不使用最新版本的 PowerShell 和数据工厂模块,则在运行命令时可能会遇到反序列化错误。
登录到 PowerShell
在计算机上启动 PowerShell。 在完成本快速入门之前,请将 PowerShell 保持打开状态。 如果将它关闭再重新打开,则需要再次运行这些命令。
运行以下命令,并输入用于登录 Azure 门户的同一 Azure 用户名和密码:
Connect-AzAccount -Environment AzureChinaCloud运行以下命令查看此帐户的所有订阅:
Get-AzSubscription如果看到多个订阅与帐户相关联,请运行以下命令,选择要使用的订阅。 请将 SubscriptionId 替换为自己的 Azure 订阅的 ID:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
创建数据工厂
为资源组名称定义一个变量,稍后会在 PowerShell 命令中使用该变量。 将以下命令文本复制到 PowerShell,在双引号中指定 Azure 资源组的名称,然后运行命令。 例如:
"ADFQuickStartRG"。$resourceGroupName = "ADFQuickStartRG";如果该资源组已存在,请勿覆盖它。 为
$ResourceGroupName变量分配另一个值,然后再次运行命令若要创建 Azure 资源组,请运行以下命令:
$ResGrp = New-AzResourceGroup $resourceGroupName -location 'China East 2'如果该资源组已存在,请勿覆盖它。 为
$ResourceGroupName变量分配另一个值,然后再次运行命令。定义一个用于数据工厂名称的变量。
重要
更新数据工厂名称,使之全局唯一。 例如 ADFTutorialFactorySP1127。
$dataFactoryName = "ADFQuickStartFactory";若要创建数据工厂,请运行下面的 Set-AzDataFactoryV2 cmdlet,使用 $ResGrp 变量中的 Location 和 ResourceGroupName 属性:
$DataFactory = Set-AzDataFactoryV2 -ResourceGroupName $ResGrp.ResourceGroupName ` -Location $ResGrp.Location -Name $dataFactoryName
请注意以下几点:
Azure 数据工厂的名称必须全局唯一。 如果收到以下错误,请更改名称并重试。
The specified Data Factory name 'ADFv2QuickStartDataFactory' is already in use. Data Factory names must be globally unique.若要创建数据工厂实例,用于登录到 Azure 的用户帐户必须是 参与者 或 所有者 角色的成员,或者是 Azure 订阅的 管理员 。
若要查看目前提供数据工厂的 Azure 区域的列表,请在以下页面上选择感兴趣的区域,然后展开“分析”以找到“数据工厂”:可用产品(按区域)。 数据工厂使用的数据存储(Azure 存储、Azure SQL 数据库,等等)和计算资源(HDInsight 等)可以位于其他区域中。
创建链接服务
在数据工厂中创建链接服务,将数据存储和计算服务链接到数据工厂。 在本快速入门中,创建一个 Azure 存储链接服务,用作源存储和目标存储。 链接服务包含的连接信息可供数据工厂服务用来在运行时连接到它。
提示
在本快速入门中,你将使用 帐户密钥 作为数据存储的身份验证类型,但你可以根据需要选择其他支持的身份验证方法: SAS URI、*服务主体和 托管标识 。 有关详细信息,请参阅此文中的相应部分。 为了安全地存储数据存储的机密,我们还建议使用 Azure Key Vault。 有关详细说明,请参阅此文。
在 C:\ADFv2QuickStartPSH 文件夹中创建包含以下内容的名为 AzureStorageLinkedService.json 的 JSON 文件:(如果尚不存在,请创建 ADFv2QuickStartPSH 文件夹)。
重要
将 <accountName> 和 <accountKey> 分别替换为 Azure 存储帐户的名称和密钥,然后保存文件。
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.chinacloudapi.cn" } } }如果使用记事本,请在“另存为”对话框中选择“所有文件”作为“另存为类型”字段的值。 否则,它可能会向文件添加
.txt扩展名。 例如,AzureStorageLinkedService.json.txt。 如果先在文件资源管理器中创建该文件,然后再在记事本中将其打开,则可能看不到.txt扩展,因为系统默认设置“隐藏已知文件类型的扩展名”选项。 在执行下一步骤之前删除.txt扩展名。在 PowerShell 中,切换到 ADFv2QuickStartPSH 文件夹。
Set-Location 'C:\ADFv2QuickStartPSH'运行 Set-AzDataFactoryV2LinkedService cmdlet 来创建链接服务:AzureStorageLinkedService。
Set-AzDataFactoryV2LinkedService -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "AzureStorageLinkedService" ` -DefinitionFile ".\AzureStorageLinkedService.json"下面是示例输出:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedService
创建数据集
此过程创建两个数据集:InputDataset 和 OutputDataset 。 这两个数据集的类型为 Binary。 它们指的是您在上一节创建的 Azure Storage 关联服务。 输入数据集表示输入文件夹中的源数据。 在输入数据集定义中,请指定包含源数据的 Blob 容器 (adftutorial)、文件夹 (input) 和文件 (emp.txt)。 输出数据集表示复制到目标的数据。 在输出数据集定义中,请指定要将数据复制到其中的 Blob 容器 (adftutorial)、文件夹 (output) 和文件。
在 C:\ADFv2QuickStartPSH 文件夹中创建一个名为 InputDataset.json 的 JSON 文件,使其包含以下内容:
{ "name": "InputDataset", "properties": { "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "fileName": "emp.txt", "folderPath": "input", "container": "adftutorial" } } } }若要创建数据集 InputDataset,请运行 Set-AzDataFactoryV2Dataset cmdlet。
Set-AzDataFactoryV2Dataset -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "InputDataset" ` -DefinitionFile ".\InputDataset.json"下面是示例输出:
DatasetName : InputDataset ResourceGroupName : <resourceGroupname> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.BinaryDataset重复创建输出数据集的步骤。 在 C:\ADFv2QuickStartPSH 文件夹中创建一个名为 OutputDataset.json 的 JSON 文件,使其包含以下内容:
{ "name": "OutputDataset", "properties": { "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "folderPath": "output", "container": "adftutorial" } } } }运行 Set-AzDataFactoryV2Dataset cmdlet 以创建 OutDataset。
Set-AzDataFactoryV2Dataset -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "OutputDataset" ` -DefinitionFile ".\OutputDataset.json"下面是示例输出:
DatasetName : OutputDataset ResourceGroupName : <resourceGroupname> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.BinaryDataset
创建管道
在此过程中,您将创建一个包含复制活动的管道,该活动使用输入和输出数据集。 复制活动将数据从输入数据集设置中指定的文件复制到输出数据集设置中指定的文件。
在 C:\ADFv2QuickStartPSH 文件夹中创建一个名为 Adfv2QuickStartPipeline.json 的 JSON 文件,使其包含以下内容:
{ "name": "Adfv2QuickStartPipeline", "properties": { "activities": [ { "name": "CopyFromBlobToBlob", "type": "Copy", "dependsOn": [], "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false, "secureInput": false }, "userProperties": [], "typeProperties": { "source": { "type": "BinarySource", "storeSettings": { "type": "AzureBlobStorageReadSettings", "recursive": true } }, "sink": { "type": "BinarySink", "storeSettings": { "type": "AzureBlobStorageWriteSettings" } }, "enableStaging": false }, "inputs": [ { "referenceName": "InputDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "OutputDataset", "type": "DatasetReference" } ] } ], "annotations": [] } }若要创建管道 Adfv2QuickStartPipeline,请运行 Set-AzDataFactoryV2Pipeline cmdlet。
$DFPipeLine = Set-AzDataFactoryV2Pipeline ` -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName ` -Name "Adfv2QuickStartPipeline" ` -DefinitionFile ".\Adfv2QuickStartPipeline.json"
创建管道运行
在此步骤中,将创建管道运行。
运行 Invoke-AzDataFactoryV2Pipeline cmdlet 以创建一个管道运行。 此 cmdlet 返回管道运行 ID,用于将来的监视。
$RunId = Invoke-AzDataFactoryV2Pipeline `
-DataFactoryName $DataFactory.DataFactoryName `
-ResourceGroupName $ResGrp.ResourceGroupName `
-PipelineName $DFPipeLine.Name
监视管道运行
运行以下 PowerShell 脚本,持续检查管道运行状态,直到完成数据复制为止。 在 PowerShell 窗口中复制/粘贴以下脚本,然后按 ENTER。
while ($True) { $Run = Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $ResGrp.ResourceGroupName ` -DataFactoryName $DataFactory.DataFactoryName ` -PipelineRunId $RunId if ($Run) { if ( ($Run.Status -ne "InProgress") -and ($Run.Status -ne "Queued") ) { Write-Output ("Pipeline run finished. The status is: " + $Run.Status) $Run break } Write-Output ("Pipeline is running...status: " + $Run.Status) } Start-Sleep -Seconds 10 }下面是管道运行的示例输出:
Pipeline is running...status: InProgress Pipeline run finished. The status is: Succeeded ResourceGroupName : ADFQuickStartRG DataFactoryName : ADFQuickStartFactory RunId : 00000000-0000-0000-0000-0000000000000 PipelineName : Adfv2QuickStartPipeline LastUpdated : 8/27/2019 7:23:07 AM Parameters : {} RunStart : 8/27/2019 7:22:56 AM RunEnd : 8/27/2019 7:23:07 AM DurationInMs : 11324 Status : Succeeded Message :运行以下脚本来检索复制活动运行详细信息,例如,读取/写入的数据的大小。
Write-Output "Activity run details:" $Result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $DataFactory.DataFactoryName -ResourceGroupName $ResGrp.ResourceGroupName -PipelineRunId $RunId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) $Result Write-Output "Activity 'Output' section:" $Result.Output -join "`r`n" Write-Output "Activity 'Error' section:" $Result.Error -join "`r`n"确认你看到了与活动运行结果的以下示例输出类似的输出:
ResourceGroupName : ADFQuickStartRG DataFactoryName : ADFQuickStartFactory ActivityRunId : 00000000-0000-0000-0000-000000000000 ActivityName : CopyFromBlobToBlob PipelineRunId : 00000000-0000-0000-0000-000000000000 PipelineName : Adfv2QuickStartPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesRead, filesWritten...} LinkedServiceName : ActivityRunStart : 8/27/2019 7:22:58 AM ActivityRunEnd : 8/27/2019 7:23:05 AM DurationInMs : 6828 Status : Succeeded Error : {errorCode, message, failureType, target} Activity 'Output' section: "dataRead": 20 "dataWritten": 20 "filesRead": 1 "filesWritten": 1 "sourcePeakConnections": 1 "sinkPeakConnections": 1 "copyDuration": 4 "throughput": 0.01 "errors": [] "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (China East 2)" "usedDataIntegrationUnits": 4 "usedParallelCopies": 1 "executionDetails": [ { "source": { "type": "AzureBlobStorage" }, "sink": { "type": "AzureBlobStorage" }, "status": "Succeeded", "start": "2019-08-27T07:22:59.1045645Z", "duration": 4, "usedDataIntegrationUnits": 4, "usedParallelCopies": 1, "detailedDurations": { "queuingDuration": 3, "transferDuration": 1 } } ] Activity 'Error' section: "errorCode": "" "message": "" "failureType": "" "target": "CopyFromBlobToBlob"
查看已部署的资源
管道会自动在 adftutorial Blob 容器中创建 output 文件夹。 然后将 emp.txt 文件从 input 文件夹复制到 output 文件夹。
在 Azure 门户的“adftutorial”容器页中选择“刷新”,查看输出文件夹。
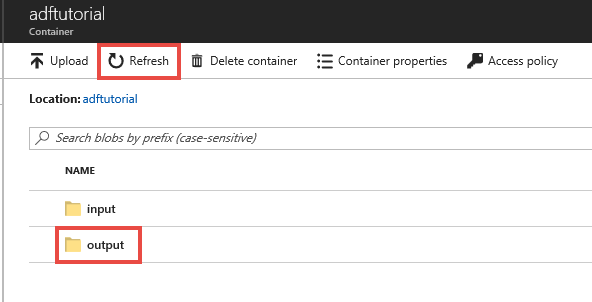
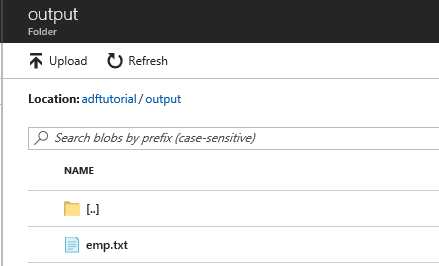
在文件夹列表中,选择“输出”。
确认 emp.txt 已复制到 output 文件夹。
清理资源
可以通过两种方式清理在快速入门中创建的资源。 可以删除 Azure 资源组,其中包括资源组中的所有资源。 若要使其他资源保持原封不动,请仅删除在此教程中创建的数据工厂。
删除资源组时会删除所有资源,包括其中的数据工厂。 运行以下命令可以删除整个资源组:
Remove-AzResourceGroup -ResourceGroupName $resourcegroupname
注意
删除资源组可能需要一些时间。 请耐心等待此过程完成
如果只需删除数据工厂,不需删除整个资源组,请运行以下命令:
Remove-AzDataFactoryV2 -Name $dataFactoryName -ResourceGroupName $resourceGroupName
相关内容
此示例中的管道将数据从 Azure Blob 存储中的一个位置复制到另一个位置。 完成相关教程来了解如何在更多方案中使用数据工厂。