Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
数据流可在Azure Data Factory管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
利用断言转换,你能够在映射数据流中生成自定义规则,以用于数据质量和数据验证。 可以生成用于确定值是否满足预期值域的规则。 此外,你还可以生成检查行唯一性的规则。 断言转换会帮助确定数据的每一行是否满足一组条件。 断言转换还允许设置在不满足数据验证规则时的自定义错误消息。
配置
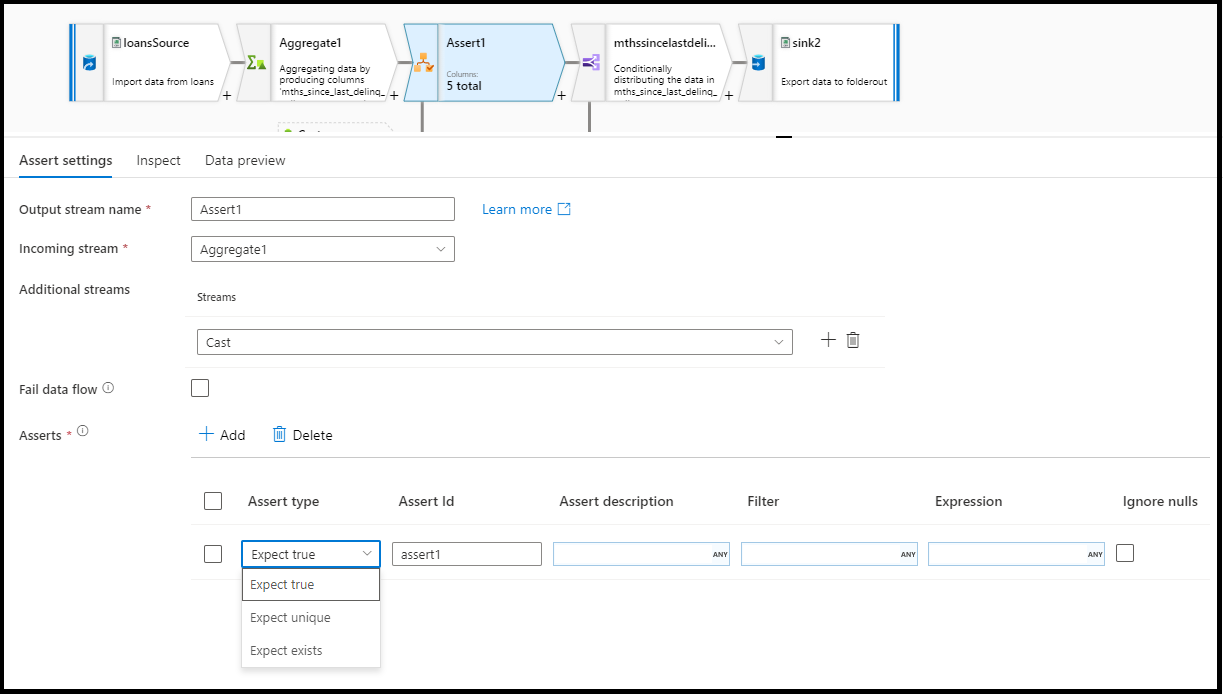
在断言转换配置面板中,你将选择断言类型,为断言提供唯一名称、可选说明,并定义表达式和可选筛选器。 数据预览窗格指示哪些行失败了断言。 此外,针对断言失败的行,可以使用isError() 和 hasError() 在下游测试每个行标记。
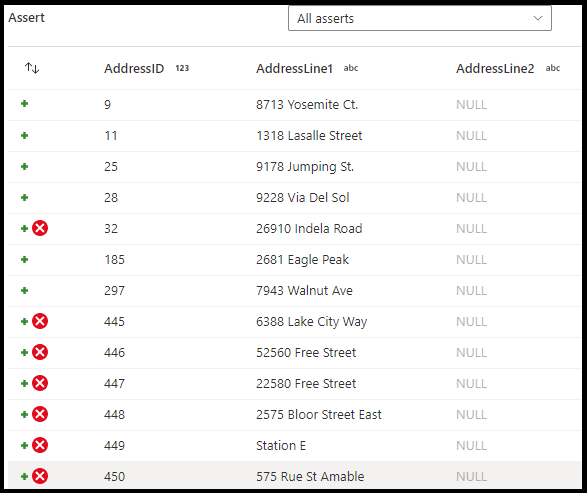
断言类型
- 期望为 true:表达式的结果必须计算为布尔值 true 结果。 此选项用于验证数据中的域值范围。
- 期望为 unique:将列或表达式设置为数据中的唯一性规则。 使用此设置标记重复行。
- 预期为 exists:此选项仅在选中第二个传入流时可用。 存在函数会查看这两个流,并基于您指定的列或表达式来判断这两个流中是否存在行。 若要为存在添加第二个流,请选择
Additional streams。
数据流故障
如果想要断言规则失败时数据流活动立即失败,请选择 fail data flow。
断言 ID
断言 ID 是一个属性,你会在其中为断言输入(字符串)名称。 稍后可以在数据流中向下游使用该标识符,使用 hasError() 或来输出断言失败代码。 每个数据流中的断言 ID 必须是唯一的。
断言说明
在此处为断言输入字符串说明。 也可以在此处使用表达式和行上下文列值。
筛选器
筛选器是一个可选属性,可在其中根据表达式值将断言筛选为仅限行子集。
表达式
为每个断言输入一个求值表达式。 您可以为每个断言转换定义多个断言。 每种类型的断言都需要表达式,ADF 将需要计算该表达式,以测试该断言是否通过。
忽略 null
在默认情况下,断言变换会在行断言计算时自动包括 NULL值。 你可以选择使用此属性忽略 NULL。
直接行断言失败
当断言失败时,可以选择使用汇聚转换上的“错误”选项卡将这些错误行定向到 Azure 云中的文件。 您还可以在汇聚转换中选择不输出断言失败的行,通过忽略所有错误行来完全实现这一点。
示例
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
数据流脚本
示例
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1