Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
数据流可在Azure Data Factory管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
使用 select 转换对列执行重命名、删除或重新排序操作。 此转换不会更改行数据,但会选择哪些列是在下游传播的。
在 select 转换中,用户可指定固定映射、使用模式来执行基于规则的映射,也可启用自动映射。 可在同一 select 转换中同时使用固定映射和基于规则的映射。 如果某个列与定义的某个映射不匹配,则该列将被删除。
固定映射
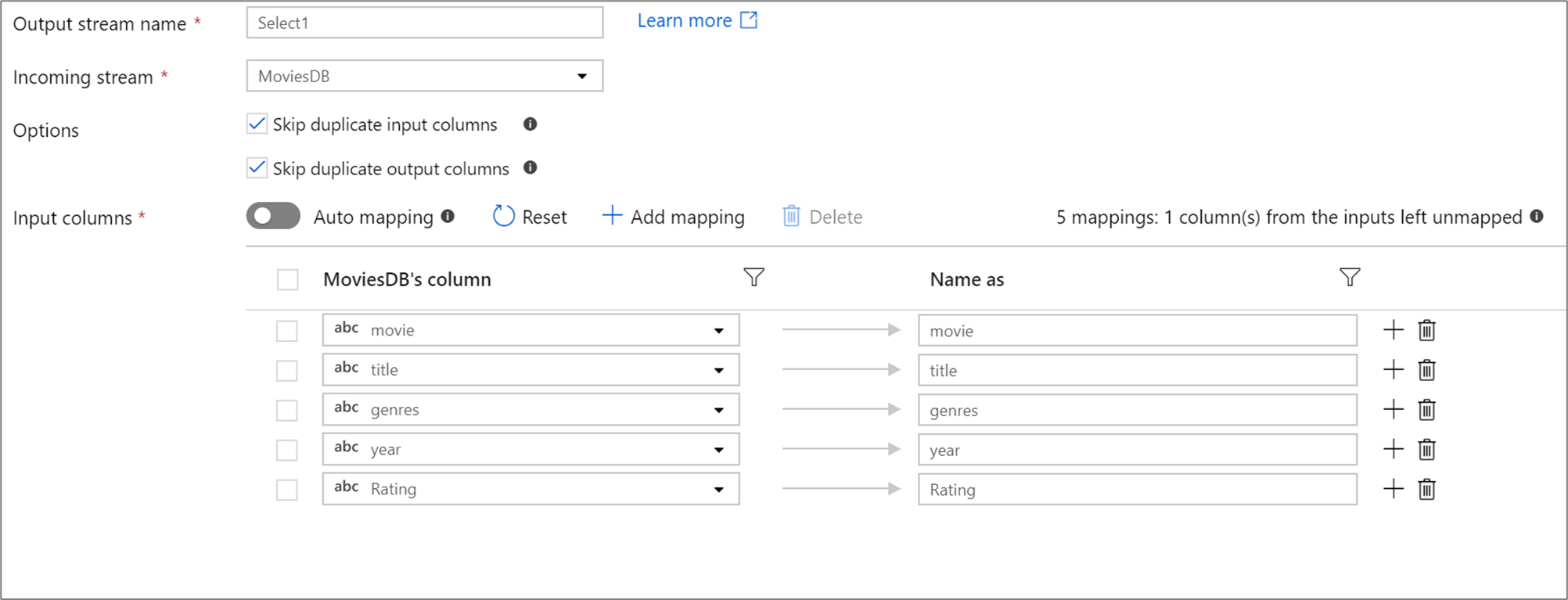
如果投影中定义的列少于 50,则默认情况下,所有定义的列都将具有固定映射。 固定映射采用已定义的传入列,并将其映射为精确名称。
注意
不能使用固定映射来映射或重命名偏移列
映射分层列
固定映射可用于将分层列的子列映射到顶级列。 如果具有已定义的层次结构,请使用列下拉列表选择子列。 选择转换将创建一个新列,并包含子列的值和数据类型。
基于规则的映射
如果希望一次映射多个列或将偏移列传递到下游,请使用基于规则的映射来定义使用列模式的映射。 基于列的 name、type、stream 和 position 进行匹配。 可使用固定映射和基于规则的映射的任意组合。 默认情况下,列数大于 50 的投影都将默认为基于规则的映射,其在每列上进行匹配并输出所输入的名称。
若要添加基于规则的映射,请单击“添加映射”,然后选择“基于规则的映射” 。

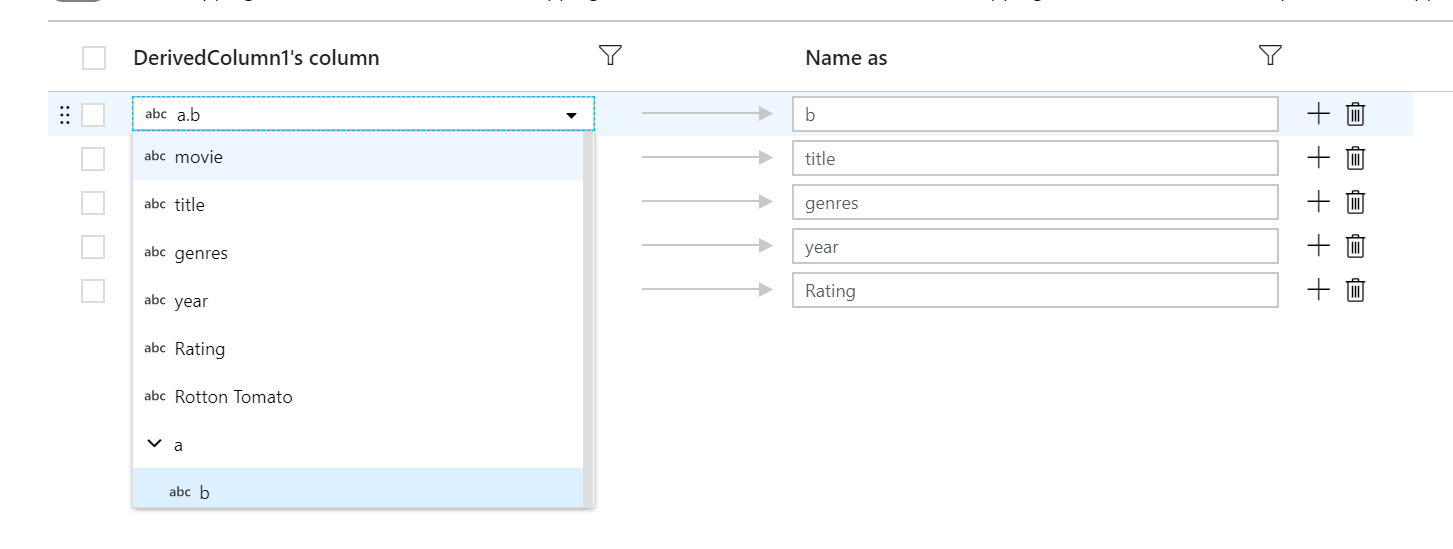
每个基于规则的映射需要两个输入:要匹配的条件以及每个映射列的名称。 这两个值都是通过表达式生成器输入的。 在左侧表达式框中,输入布尔值匹配条件。 在右侧的表达式框中,指定匹配列的映射目标。

使用 $$ 语法来引用匹配列的输入名称。 以上图为例,假设用户想要在名称长度不到 6 个字符的所有字符串列上进行匹配。 如果一个传入列被命名为 test,则表达式 $$ + '_short' 会将列重命名为 test_short。 如果这是存在的唯一映射,则所有不符合该条件的列都将从输出的数据中删除。
模式同时匹配偏移列和已定义的列。 若要查看由规则映射的已定义的列,请单击规则旁边的眼镜图标。 使用数据预览来验证输出。
正则表达式映射
如果单击向下的 V 形图标,可指定正则表达式映射条件。 正则表达式映射条件匹配所有符合指定正则表达式的列名称。 这可与标准的基于规则的映射结合使用。

上述示例与正则表达式模式 (r) 或任何包含小写 r 的列名匹配。 与标准规则映射类似,所有匹配的列都使用$$语法由右侧的条件进行更改。
如果列名称中有多个正则表达式匹配项,可使用 $n 来指示特定匹配项(其中“n”表示具体的匹配项)。 例如,“$2”指列名称中的第二个匹配项。
基于规则的层次结构
如果定义的投影具有层次结构,则可使用基于规则的映射来映射层次结构子列。 指定匹配条件和要映射其子列的复杂列。 每个匹配的子列都将按照右侧指定的“命名为”规则进行输出。
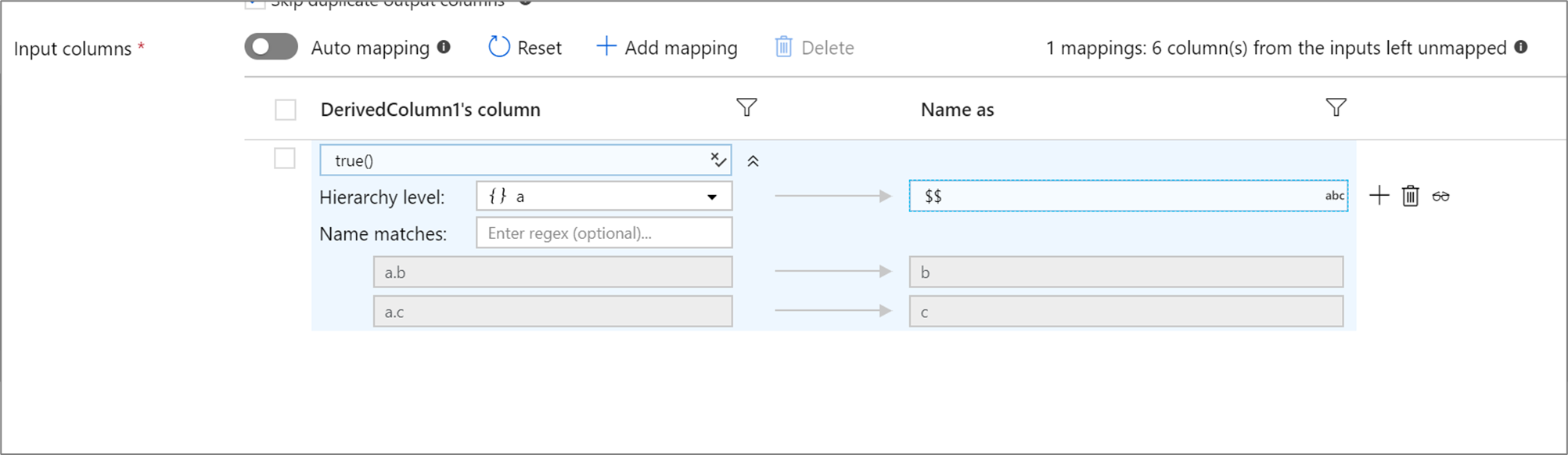
上面的示例与复杂列 a 的所有子列匹配。
a 包含两个子列 - b 和 c。 输出架构将包括两列 b 和 c,因为“名称为”条件是 $$。
参数化
可使用基于规则的映射对列名称进行参数化。 使用关键字 name 将传入列名称与参数匹配。 例如,如果你具数据流参数 mycolumn,则可创建匹配等于 mycolumn 的任何列名称的规则。 可将匹配的列重命名为硬编码的字符串(例如“业务键”),并显式引用它。 在此示例中,匹配条件为 name == $mycolumn,名称条件为“业务键”。
自动映射
添加 select 转换时,可以通过切换“自动映射”滑块来启用该功能。 启用自动映射后,select 转换会映射所有传入列(不包括重复列),其名称与它们的输入相同。 这将包括偏移列,这意味着输出数据可能包含未在架构中定义的列。 有关偏移列的详细信息,请参阅架构偏差。
启用自动映射后,选择转换将遵循跳过重复项的设置,并为现有列提供新的别名。 在同一流和自联接方案中执行多个联接或查找时,别名非常有用。
重复列
默认情况下,select 转换会删除输入和输出投影中的重复列。 重复输入列通常来自联接和查找转换,其中列名称在联接的每一侧都是重复的。 如果将两个不同的输入列映射到同一名称,则可能产生重复输出列。 通过勾选复选框选择是删除还是保留重复列。
列的顺序
映射的顺序决定了输出列的顺序。 如果多次映射某个输入列,则只采用第一个映射。 在删除重复列时,将保留第一个匹配的列。
数据流脚本
语法
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
示例
下面是 select 映射及其数据流脚本的一个示例:
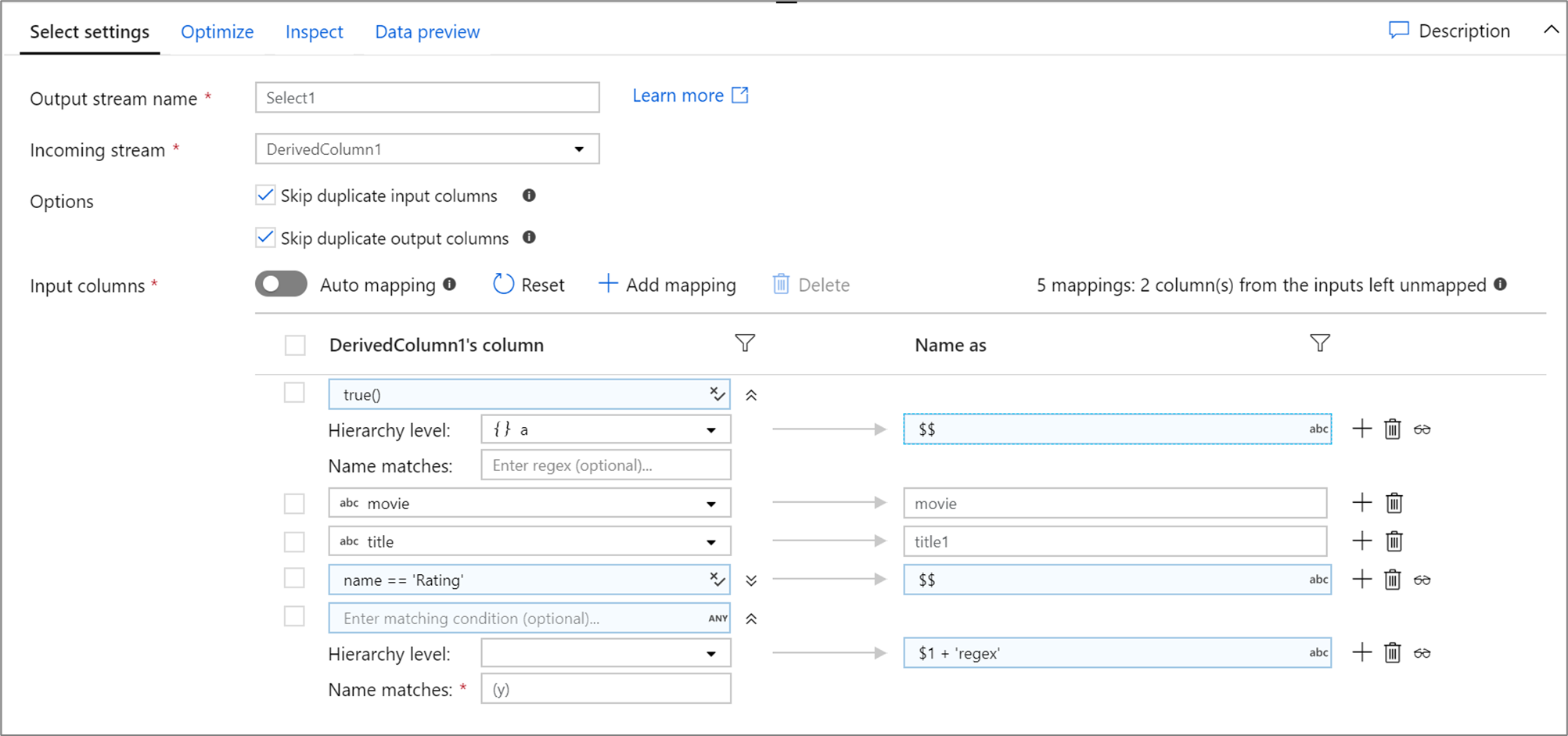
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
相关内容
- 使用 Select 来对列执行重命名、重新排序和别名设置操作后,使用Sink 转换将数据存储到数据存储中。