Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
APPLIES TO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
本文重点介绍了如何使用增量格式向/从存储在 Azure Data Lake Store Gen2 或 Azure Blob Storage 的 delta lake 复制数据。 该连接器作为映射数据流中的内联数据集提供,同时用作源和接收器。
映射数据流属性
该连接器作为映射数据流中的内联数据集提供,同时用作源和接收器。
源属性
下表列出了 delta 源支持的属性。 可以在“源选项”选项卡中编辑这些属性。
| 名称 | 说明 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| 格式 | 格式必须为 delta |
是 | delta |
格式 |
| 文件系统 | delta lake 的容器/文件系统 | 是 | 字符串 | fileSystem |
| 文件夹路径 | delta lake 的目录 | 是 | 字符串 | folderPath |
| 压缩类型 | Delta 表的压缩类型 | 否 | bzip2gzipdeflateZipDeflatesnappylz4 |
压缩类型 |
| 压缩级别 | 选择压缩是否尽快完成,或者是否应该以最佳方式压缩生成的文件。 | 如果指定了 compressedType,则为必需项。 |
Optimal 或 Fastest |
压缩级别 |
| 时间旅行 | 选择是否查询 delta 表的旧快照 | 否 | 按时间戳查询:时间戳 按版本查询:Integer |
timestampAsOf versionAsOf |
| 允许找不到文件 | 如果为 true,则找不到文件时不会引发错误 | 否 |
true 或 false |
忽略未找到文件 |
导入架构
Delta 仅作为内联数据集提供,且默认情况下没有关联架构。 要获取列元数据,请单击“投影”选项卡中的“导入架构”按钮 。这样你可以引用语料库指定的列名称和数据类型。 若要导入架构,数据流调试会话必须处于活动状态,且你必须具有可以指向的现有 CDM 实体定义文件。
Delta 源脚本示例
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
接收器属性
下表列出了 delta 接收器支持的属性。 可以在“设置”选项卡中编辑这些属性。
| 名称 | 说明 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| 格式 | 格式必须为 delta |
是 | delta |
格式 |
| 文件系统 | delta lake 的容器/文件系统 | 是 | 字符串 | fileSystem |
| 文件夹路径 | delta lake 的目录 | 是 | 字符串 | folderPath |
| 压缩类型 | Delta 表的压缩类型 | 否 | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
压缩类型 |
| 压缩级别 | 选择压缩是否尽快完成,或者是否应该以最佳方式压缩生成的文件。 | 如果指定了 compressedType,则为必需项。 |
Optimal 或 Fastest |
压缩级别 |
| 真空 | 删除早于指定持续时间、不再与当前表版本相关的文件。 如果指定了 0 或更小的值,则不执行真空操作。 | 是 | 整数 | vacuum |
| 表操作 | 告知 ADF 如何处理接收器中的目标 Delta 表。 可以原样保留该行并追加新行,使用新的元数据和数据覆盖现有表定义和数据,或保留现有表结构,但首先截断所有行,然后插入新行。 | 否 | 无,截断,覆盖 | deltaTruncate,覆盖 |
| 更新方法 | 当你单独选择“允许插入”或写入新的 delta 表时,目标将接收所有传入行,而不考虑所设置的行策略。 如果你的数据包含其他行策略的行,则需要使用前面的筛选器转换来排除它们。 选择所有更新方法时,会执行合并,根据使用前面的更改行转换设置的行策略插入/删除/更新插入/更新行。 |
是 |
true 或 false |
insertable 可删除的 upsertable updateable |
| 优化写入 | 通过优化 Spark 执行程序中的内部随机选择,使写入操作实现更高的吞吐量。 因此,你可能会注意到分区较少,并且文件的大小较大。 | 否 |
true 或 false |
optimizedWrite: true |
| 自动压缩 | 完成任何写入操作后,Spark 会自动执行 OPTIMIZE 命令以重新组织数据,并在必要时生成更多分区,以便在将来获得更好的读取性能 |
否 |
true 或 false |
自动压缩:true |
Delta 接收器脚本示例
关联的数据流脚本为:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
使用分区修剪的 Delta 接收器
在上述更新方法(即 update/upsert/delete)下使用此选项,可以限制检查的分区数。 只会从目标存储中提取满足此条件的分区。 可以指定分区列可采用的固定值集。
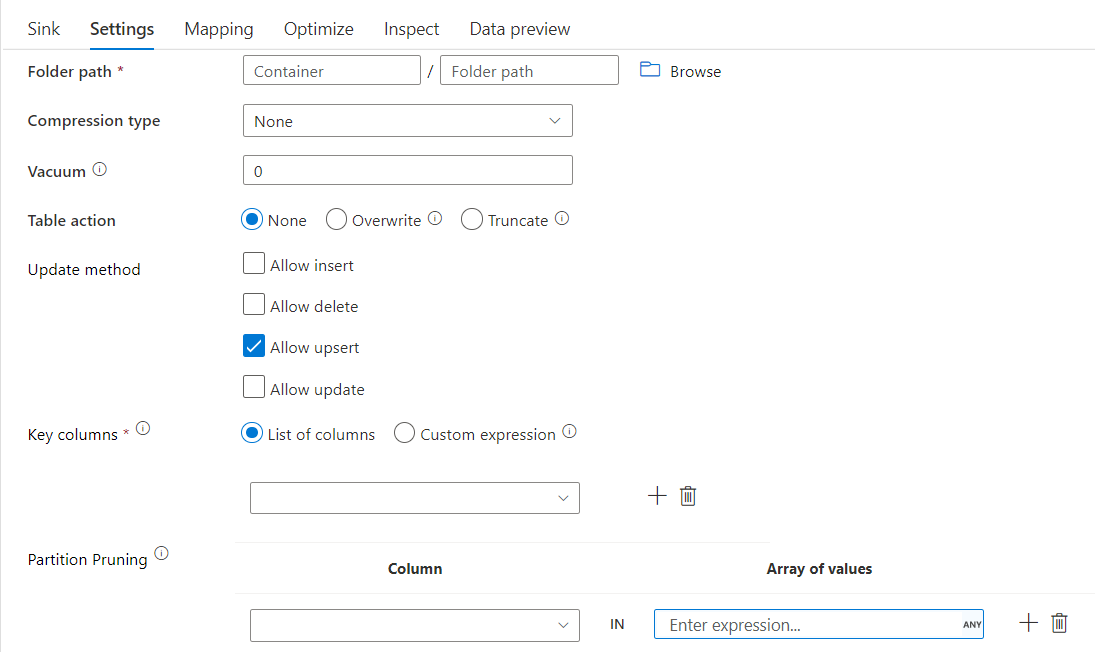
使用分区修剪的 Delta 接收器脚本示例
下面提供了示例脚本。
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Delta 只会从目标 Delta 存储中读取 part_col == 5 和 8 的 2 个分区,而不是读取所有分区。 part_col 是用于对目标增量数据进行分区的列。 它不需要出现在源数据中。
Delta 接收器优化选项
在“设置”选项卡中,你会看到另外三个用于优化增量接收器转换的选项。
如果启用“合并架构”选项,则允许架构演变,即当前传入流中有、但目标 Delta 表中没有的所有列会自动添加到架构中。 所有更新方法都支持此选项。
如果启用“自动压缩”,在一次单独的写入操作后,转换将检查是否可以进一步压缩文件,并运行快速优化作业(文件大小为 128 MB 而不是 1 GB),以便对小文件数量最多的分区进一步压缩文件。 自动压缩有助于将大量小文件合并为少量大文件。 仅当至少有 50 个文件时,才会启动自动压缩。 一旦执行压缩操作,就会创建一个新版本的表,并以压缩形式写入一个新文件,其中包含多个先前文件的数据。
如果启用“优化写入”,接收器转换将根据实际数据,通过尝试为每个表分区写出 128 MB 文件,来动态优化分区大小。 这是一个近似大小,可能因数据集特征而异。 优化的写入可以提升写入和后续读取的整体效率。 它会组织分区,使后续读取的性能得以提高。
提示
优化写入过程会减慢整个 ETL 作业的速度,因为接收器会在处理数据后发出 Spark Delta Lake Optimize 命令。 建议谨慎使用“优化写入”。 例如,如果你有一个每小时数据管道,请每天使用“优化写入”执行数据流。
已知限制
写入 delta 接收器时,存在一个已知的限制,即不会在监视输出中显示写入的行数。