Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
数据流可在Azure Data Factory管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
源转换为数据流配置数据源。 设计数据流时,第一步始终是配置源转换。 若要添加源,请在数据流画布中选择“添加源”框。
每个数据流至少需要一个源转换,但你可根据需要添加任意多个源来完成数据转换。 可以使用连接、查找或合并转换的方式将这些数据源连接到一起。
每个源转换只与一个数据集或链接服务相关联。 数据集定义要写入或读取的数据的形状和位置。 如果使用基于文件的数据集,则可在源中使用通配符和文件列表,一次性处理多个文件。
内联数据集
创建源转换时所做的第一次决策是源信息是在数据集对象内定义还是在源转换内定义。 大多数格式只适用于其中之一。 若要了解如何使用特定连接器,请参阅相应的连接器文档。
当某一格式同时支持内联和数据集对象时,这两种方式各有其好处。 数据集对象是可重用的实体,可在其他数据流和复制等活动中使用。 使用强化的架构时,这些可重复使用的实体特别有用。 数据集不基于 Spark。 有时,可能需要在源转换中替代某些设置或架构投影。
如果使用灵活的架构、一次性源实例或参数化源,建议使用内联数据集。 如果源的参数化程度非常高,则使用内联数据集可以不创建“虚拟”对象。 内联数据集基于 Spark,其属性是数据流中固有的。
若要使用内联数据集,请在“源类型”选择器中选择所需的格式。 选择要与其连接的链接服务,而不是选择源数据集。
架构选项
由于内联数据集在数据流内定义,因此没有与内联数据集关联的定义架构。 在“投影”选项卡上,可以导入源数据架构,并将该架构存储为源投影。 在此选项卡上,显示了一个“架构选项”按钮,可用于定义 ADF 架构发现服务的行为。
- 使用投影架构:当有大量源文件且 ADF 会将其扫描为源时,此选项非常有用。 ADF 的默认行为是发现每个源文件的架构。 但是,如果源转换中已存储了预定义的投影,可以将此投影设置为 true,ADF 就会跳过对每个架构的自动发现。 启用此选项后,源转换可以更快地读取所有文件,并将预定义的架构应用于每个文件。
- 支持架构偏差:启用架构偏差,以便数据流能够支持源架构中尚未定义的新列。
- 验证架构:如果在投影中定义的任何列和类型与发现的源数据架构不一致,设置此选项就会导致数据流失败。
- 推断偏差列类型:当 ADF 识别到新的偏差列时,将使用 ADF 的自动类型推断将这些新列强制转换为合适的数据类型。
工作区数据库(专用于 Synapse 工作区)
在Azure Synapse工作区中,数据流源转换中存在一个名为 Workspace DB 的其他选项。 因此,你可以直接选取任何可用类型的工作区数据库作为源数据,无需额外的链接服务或数据集。
受支持的源类型
映射数据流遵循提取、加载和转换(ELT)的方法,并与Azure中的所有暂存数据集一起使用。 目前,以下数据集可用于源转换。
| 连接器 | 格式 | 数据集/内联 |
|---|---|---|
| Amazon S3 |
Avro 带分隔符的文本 Delta Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Appfigures(预览版) | -/✓ | |
| Asana(预览版) | -/✓ | |
| Azure Blob Storage |
Avro 带分隔符的文本 Delta Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| 用于 NoSQL 的 Azure Cosmos DB | ✓/- | |
| Azure Data Lake Storage Gen2 |
Avro 常见数据模型 带分隔符的文本 Delta Excel JSON ORC Parquet XML |
✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Azure SQL Managed Instance | ✓/✓ | |
| Azure Synapse Analytics | ✓/✓ | |
| data.world(预览版) | -/✓ | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Google Sheets(预览版) | -/✓ | |
| Hive | -/✓ | |
| Quickbase(预览版) | -/✓ | |
| SFTP |
Avro 带分隔符的文本 Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Smartsheet(预览版) | -/✓ | |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ | |
| REST | ✓/✓ | |
| TeamDesk(预览版) | -/✓ | |
| Twilio(预览版) | -/✓ | |
| Zendesk(预览版) | -/✓ |
特定于这些连接器的设置位于“源选项”选项卡上。有关这些设置的信息和数据流脚本示例位于连接器文档中。
Azure Data Factory 和 Synapse 管道可以访问超过 90 个本地连接器。 若要将其他这些源中的数据包含到你自己的数据流中,请使用复制活动将该数据加载到其中一个受支持的暂存区域。
源设置
添加源后,通过“源设置”选项卡进行配置。可在此处选取或创建源指向的数据集。 还可选择数据的架构和采样选项。
可在调试设置中配置数据集参数的开发值。 (必须打开调试模式。)
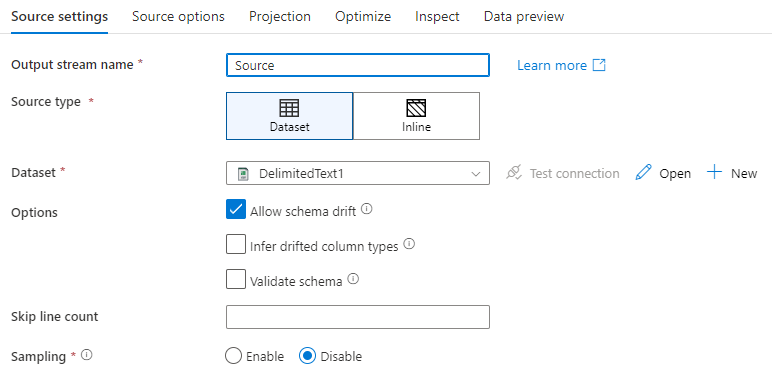
输出流名称:源转换的名称。
源类型:选择是要使用内联数据集还是现有数据集对象。
测试连接:测试数据流的 Spark 服务是否可以成功连接到源数据集中使用的链接服务。 要启用此功能,必须打开调试模式。
架构偏差:架构偏差是指在无需显式定义列更改的情况下,服务在数据流中以原生方式处理灵活架构的能力。
如果源列经常更改,请选择“允许架构偏差”复选框。 此设置允许所有传入的源字段经过转换后流向汇集器。
选择“推断偏移列类型”会指示服务检测并定义发现的每个新列的数据类型。 关闭此功能后,所有偏移列都将为字符串类型。
验证架构:如果选择“验证架构”,那么如果传入的源数据与数据集定义的架构不匹配,数据流将无法运行。
跳过行计数:“跳过行计数”字段指定在数据集的开头要忽略多少行。
采样:启用“采样”来限制源中的行数。 当你测试源中的数据或对其进行采样以进行调试时,请使用此设置。 以调试模式从管道执行数据流时,这非常有用。
若要验证源的配置是否正确,请打开调试模式并提取数据预览。 有关详细信息,请参阅调试模式。
注意
当调试模式处于打开状态时,调试设置中的行限制配置将覆盖数据预览期间源中的采样设置。
源选项
“源选项”选项卡包含特定于所选连接器和格式的设置。 有关详细信息和示例,请参阅相关的连接器文档。 这包括支持它的数据源的隔离级别(例如本地 SQL Server、Azure SQL 数据库和Azure SQL托管实例),以及其他数据源特定的设置。
投影
与数据集中的架构一样,源中的投影定义源数据中的数据列、类型和格式。 对于大多数数据集类型(例如 SQL 和 Parquet),源中的投影是固定的,用于反映数据集中定义的架构(它将根据源而变化)。 如果你的源文件不是强类型(例如,平面 .csv 文件而不是 Parquet 文件),则可在源转换过程中为每个字段定义数据类型。 下图显示了一个示例投影:
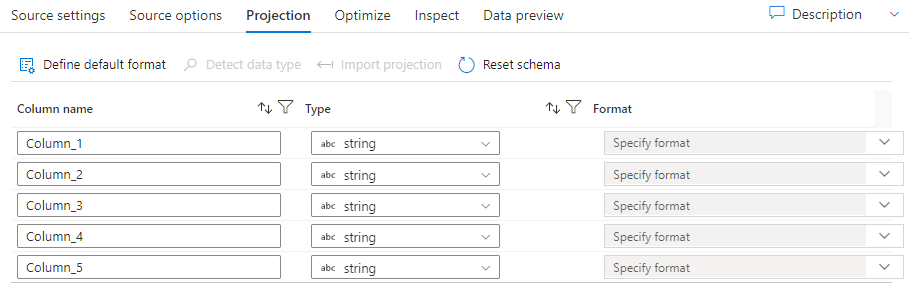
如果文本文件没有定义的架构,请选择“检测数据类型”,以便服务采样并推断数据类型。 选择“定义默认格式”以自动检测默认数据格式。
“重置架构”将投影重置为在引用的数据集中定义的投影。
覆盖架构功能允许您在此处修改源中的投影数据类型,并覆盖原有的架构定义的数据类型。 或者可以在下游派生列转换中修改列数据类型。 使用选择转换来修改列名称。
导入架构
选择“投影”选项卡上的“导入架构”按钮,以使用活动调试群集来创建架构投影 。 它在每个源类型中都可用。 在此处导入架构将替代数据集中定义的投影。 数据集对象不会更改。
导入架构在 Avro 和Azure Cosmos DB等数据集中非常有用,这些数据集支持不需要在数据集中存在架构定义的复杂数据结构。 对于内联数据集,导入架构是唯一一种引用列元数据而不会发生架构偏差的方法。
优化源转换
“优化”选项卡允许在每个转换步骤编辑分区信息。 在大多数情况下,“使用当前分区”会针对源的理想分区结构进行优化。
如果要从Azure SQL Database源读取数据,自定义Source分区可能会以最快的速度读取数据。 服务会通过建立与数据库的并行连接来读取大型查询。 此源分区可在列上完成,也可使用查询来完成。
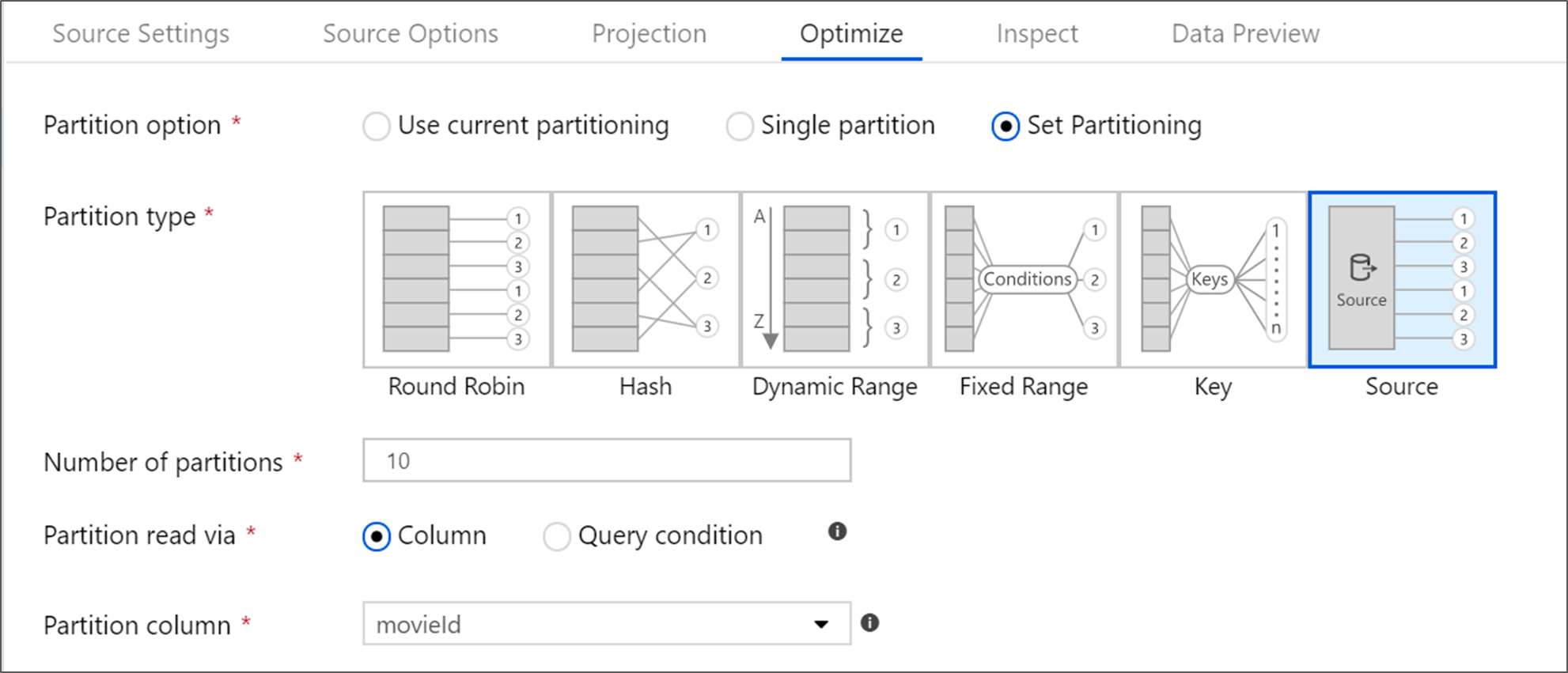
有关映射数据流中的优化的详细信息,请参阅“优化”选项卡。