Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
使用模板将包含数亿个文件的数PB数据从 Amazon S3 迁移到 Azure Data Lake Storage Gen2。
注意
如果要将小型数据卷从 AWS S3 复制到 Azure(例如小于 10 TB),则使用 Azure Data Factory 复制数据工具更加高效且易于使用。 本文章中描述的模板超出了您的实际需求。
关于解决方案模板
建议使用数据分区,尤其是在迁移 10 TB 以上的数据时。 若要将数据分区,请使用“前缀”设置按名称筛选 Amazon S3 中的文件夹和文件。然后,每个 ADF 复制作业一次可复制一个分区。 可以并行运行多个 ADF 复制作业,以获得更好的吞吐量。
数据迁移通常需要一次性的历史数据迁移,并定期将更改从 AWS S3 同步到Azure。 下面有两个模板,其中一个模板涵盖一次性历史数据迁移,另一个模板涵盖将更改从 AWS S3 同步到Azure。
用于将历史数据从 Amazon S3 迁移到 Azure Data Lake Storage Gen2 的模板
此模板(模板名称:将历史数据从 AWS S3 迁移到 Azure Data Lake Storage Gen2) 假定已在 Azure SQL Database 的外部控制表中编写分区列表。 因此,它将使用 Lookup 活动从外部控制表检索分区列表,循环访问每个分区,并使每个 ADF 复制作业一次复制一个分区。 完成任何复制作业后,它使用 存储过程 活动更新复制控制表中每个分区的状态。
该模板包含五个活动:
- Lookup检索尚未从外部控制表复制到Azure Data Lake Storage Gen2的分区。 表名称s3_partition_control_table,从表中加载数据的查询为“SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0”。
- ForEach 从 Lookup 活动获取分区列表,并遍历每个分区到 TriggerCopy 活动。 可以将 batchCount 设置为并发运行多个 ADF 复制作业。 我们在此模板中设置了参数 2。
- ExecutePipeline 执行 CopyFolderPartitionFromS3 管道。 我们之所以创建另一个管道来使每个复制作业复制一个分区,是因为这样可以轻松地重新运行失败的复制作业,以便再次从 AWS S3 中重新加载该特定分区。 加载其他分区的所有其他复制作业不受影响。
- Copy将每个分区从 AWS S3 复制到Azure Data Lake Storage Gen2。
- SqlServerStoredProcedure 更新复制控制表中每个分区的状态。
该模板包含两个参数:
- AWS_S3_bucketName 是您希望将数据迁移到的 AWS S3 上的存储桶名称。 若要从 AWS S3 上的多个桶迁移数据,可以在外部控制表中额外添加一个列用于存储每个分区的桶名称,并更新管道以相应地从该列检索数据。
- Azure_Storage_fileSystem 是 Azure Data Lake Storage Gen2 上的一个文件系统名称,您希望将数据迁移到此处。
模板仅将更改的文件从 Amazon S3 复制到 Azure Data Lake Storage Gen2
此模板(模板名称:将增量数据从 AWS S3 复制到 Azure Data Lake Storage Gen2)使用每个文件的 LastModifiedTime,仅从 AWS S3 复制新的或更新的文件到 Azure。 请注意,如果文件或文件夹已使用时间切片信息进行时间分区,作为 AWS S3 上的文件或文件夹名称的一部分(例如 /yyyy/mm/dd/file.csv),可以转到 本教程 以获取用于增量加载新文件的更高性能的方法。 此模板假定已在Azure SQL Database的外部控制表中编写分区列表。 因此,它将使用 Lookup 活动从外部控制表检索分区列表,循环访问每个分区,并使每个 ADF 复制作业一次复制一个分区。 当每个复制作业开始从 AWS S3 复制文件时,它依赖于使用 LastModifiedTime 属性来识别并仅复制新的或已更新的文件。 完成任何复制作业后,它使用 存储过程 活动更新复制控制表中每个分区的状态。
该模板包含七个活动:
- Lookup 从外部控制表检索分区。 表名称s3_partition_delta_control_table,从表加载数据的查询是“从 s3_partition_delta_control_table 中选择不同的 PartitionPrefix”。
- ForEach 从 Lookup 活动获取分区列表,并迭代每个分区到 TriggerDeltaCopy 活动。 可以将 batchCount 设置为并发运行多个 ADF 复制作业。 我们在此模板中设置了参数 2。
- ExecutePipeline 执行 DeltaCopyFolderPartitionFromS3 管道。 我们之所以创建另一个管道来使每个复制作业复制一个分区,是因为这样可以轻松地重新运行失败的复制作业,以便再次从 AWS S3 中重新加载该特定分区。 加载其他分区的所有其他复制作业不受影响。
- 查找 从外部控制表检索上次复制作业运行时,以便可以通过 LastModifiedTime 识别新的或更新的文件。 表名称为 s3_partition_delta_control_table,用于从表中加载数据的查询为“select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}' and SuccessOrFailure = 1”。
- Copy 仅针对每个分区,将新文件或更改的文件从 AWS S3 复制到 Azure Data Lake Storage Gen2。 modifiedDatetimeStart 的属性设置为上次复制作业运行时。 modifiedDatetimeEnd 的属性设置为当前复制作业运行时。 请注意,该时间采用 UTC 时区。
- SqlServerStoredProcedure 更新复制每个分区的状态,并在控制表中复制运行时(如果成功)。 SuccessOrFailure 的列设置为 1。
- SqlServerStoredProcedure 在复制过程失败时,更新控制表中每个分区的状态和复制运行时间。 SuccessOrFailure 的列设置为 0。
该模板包含两个参数:
- AWS_S3_bucketName 是您希望将数据迁移到的 AWS S3 上的存储桶名称。 若要从 AWS S3 上的多个桶迁移数据,可以在外部控制表中额外添加一个列用于存储每个分区的桶名称,并更新管道以相应地从该列检索数据。
- Azure_Storage_fileSystem 是 Azure Data Lake Storage Gen2 上的一个文件系统名称,您希望将数据迁移到此处。
如何使用这两个解决方案模板
用于将历史数据从 Amazon S3 迁移到 Azure Data Lake Storage Gen2 的模板
在 Azure SQL Database 中创建控制表以存储 AWS S3 的分区列表。
注意
表名称为 s3_partition_control_table。 控制表的架构是 PartitionPrefix 和 SuccessOrFailure,其中 PartitionPrefix 是 S3 中按名称筛选文件夹和文件的前缀设置,SuccessOrFailure 是复制每个分区的状态:0 表示此分区尚未复制到Azure,1 表示此分区已成功复制到Azure。 控制表中定义了 5 个分区,复制每个分区的默认操作状态为 0。
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);在同一Azure SQL Database上为控制表创建存储过程。
注意
该存储过程的名称为 sp_update_partition_success。 该存储过程将由 ADF 管道中的 SqlServerStoredProcedure 活动调用。
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GO转到 从 AWS S3 迁移历史数据到 Azure Data Lake Storage Gen2 模板。 输入与外部控制表的连接,AWS S3 作为数据源存储,Azure Data Lake Storage Gen2作为目标存储。 请注意,外部控制表和存储过程引用同一连接。
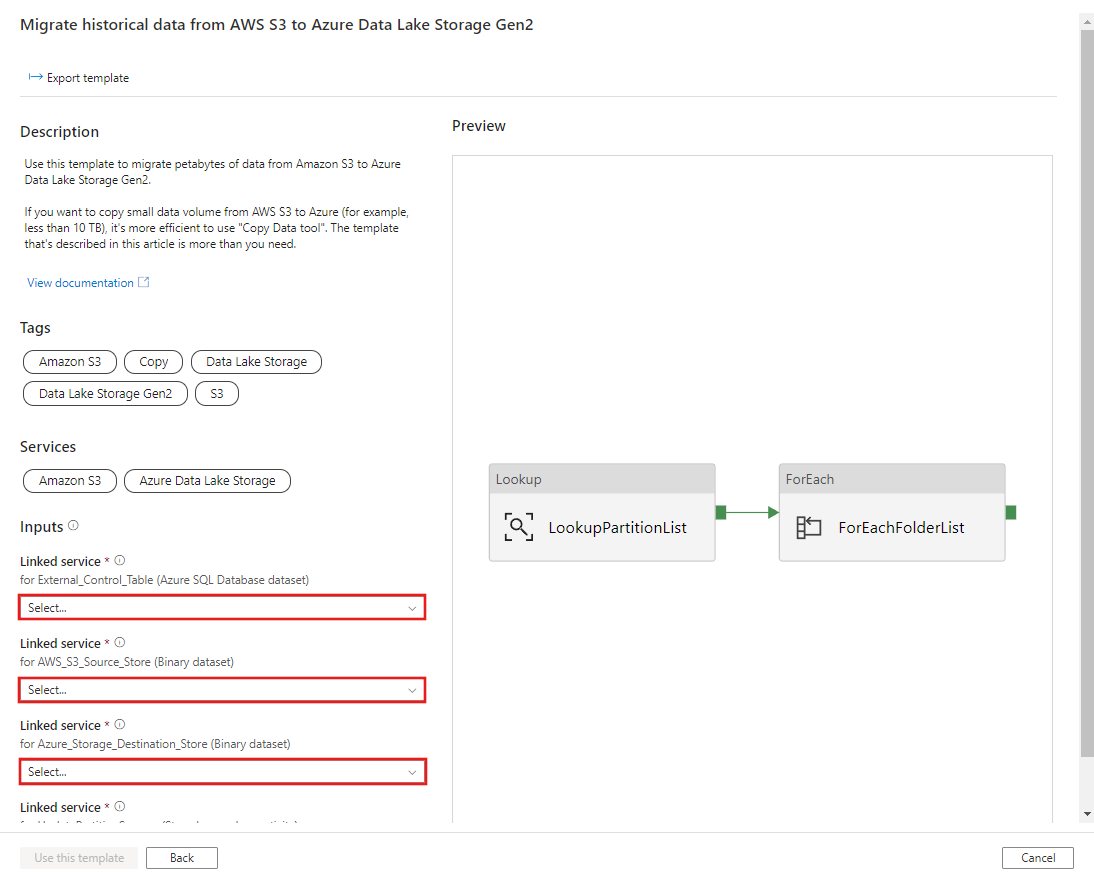
选择“使用此模板” 。
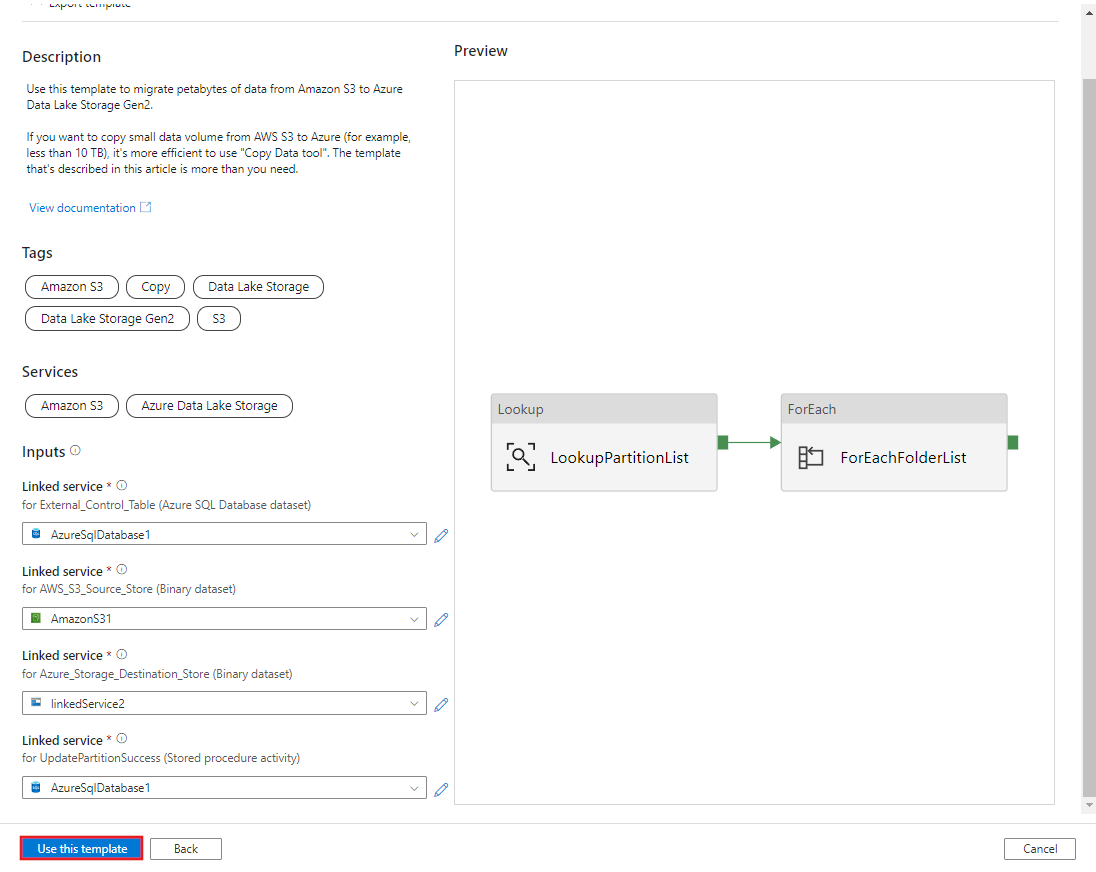
将会看到已创建 2 个管道和 3 个数据集,如以下示例中所示:
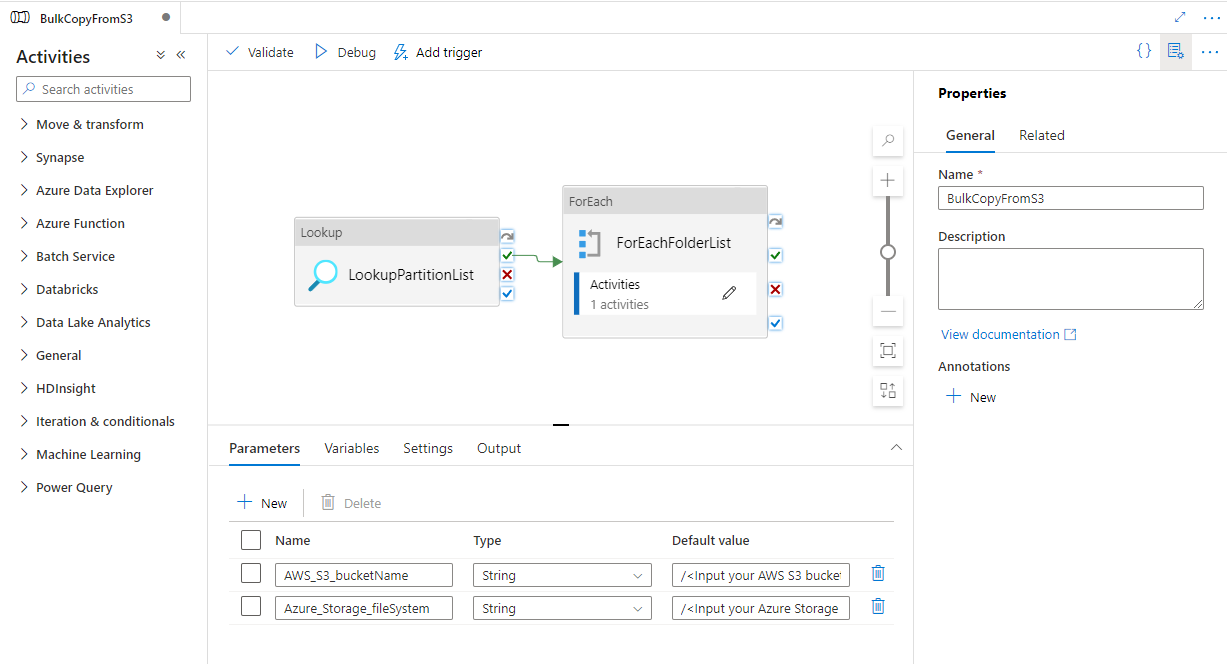
转到“BulkCopyFromS3”管道,选择“调试”,然后输入“参数” 。 然后选择“完成”。
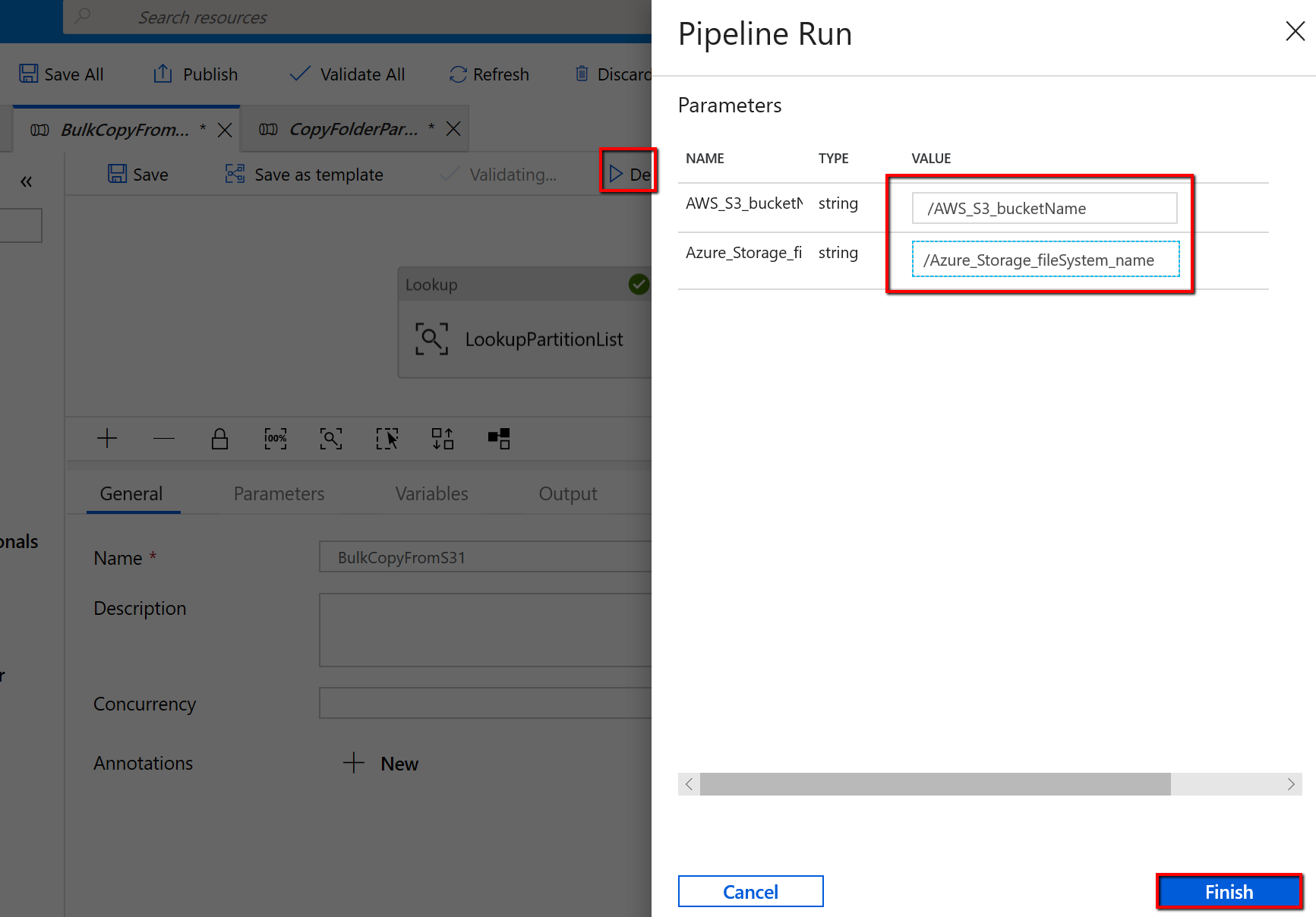
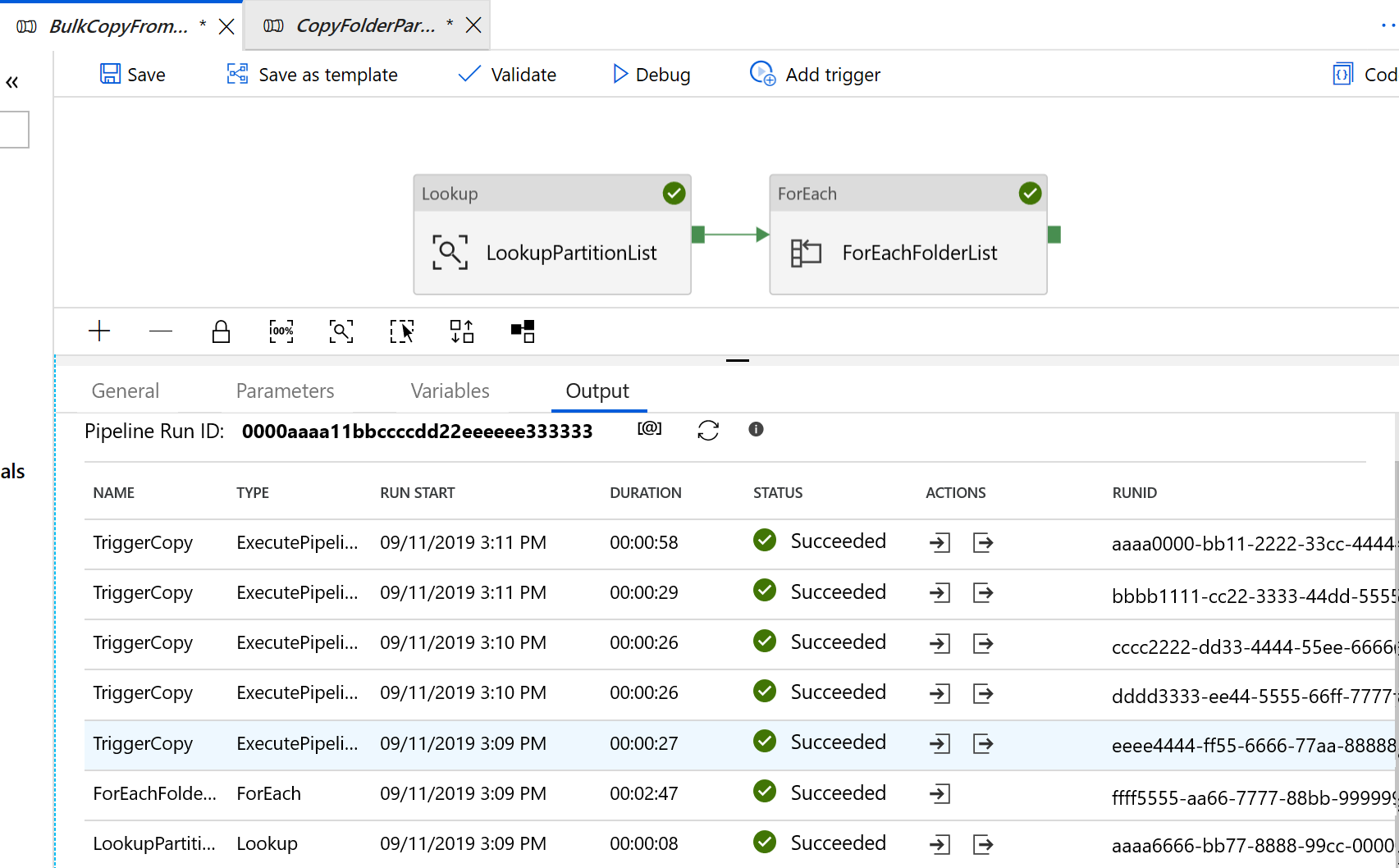
看到的结果类似于以下示例:
模板仅将更改的文件从 Amazon S3 复制到 Azure Data Lake Storage Gen2
在 Azure SQL Database 中创建控制表以存储 AWS S3 的分区列表。
注意
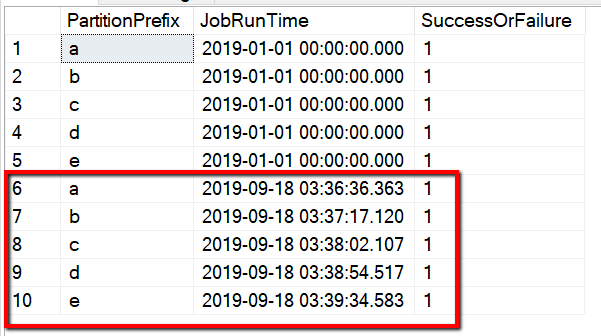
表名称为 s3_partition_delta_control_table。 控制表的架构是 PartitionPrefix、JobRunTime 和 SuccessOrFailure,其中 PartitionPrefix 是 S3 中按名称筛选文件夹和文件的前缀设置,JobRunTime 是复制作业运行时的日期/时间值,SuccessOrFailure 是复制每个分区的状态:0 表示此分区尚未复制到Azure,1 表示此分区已成功复制到Azure。 控制表中定义了 5 个分区。 JobRunTime 的默认值可以是启动一次性历史数据迁移时的时间。 ADF 复制活动将复制 AWS S3 上的、在该时间后已修改过的文件。 复制每个分区的默认操作状态为 1。
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);在同一Azure SQL Database上为控制表创建存储过程。
注意
该存储过程的名称为 sp_insert_partition_JobRunTime_success。 该存储过程将由 ADF 管道中的 SqlServerStoredProcedure 活动调用。
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GO转到将增量数据从 AWS S3 复制到 Azure Data Lake Storage Gen2 模板。 输入与外部控制表的连接,AWS S3 作为数据源存储,Azure Data Lake Storage Gen2作为目标存储。 请注意,外部控制表和存储过程引用同一连接。
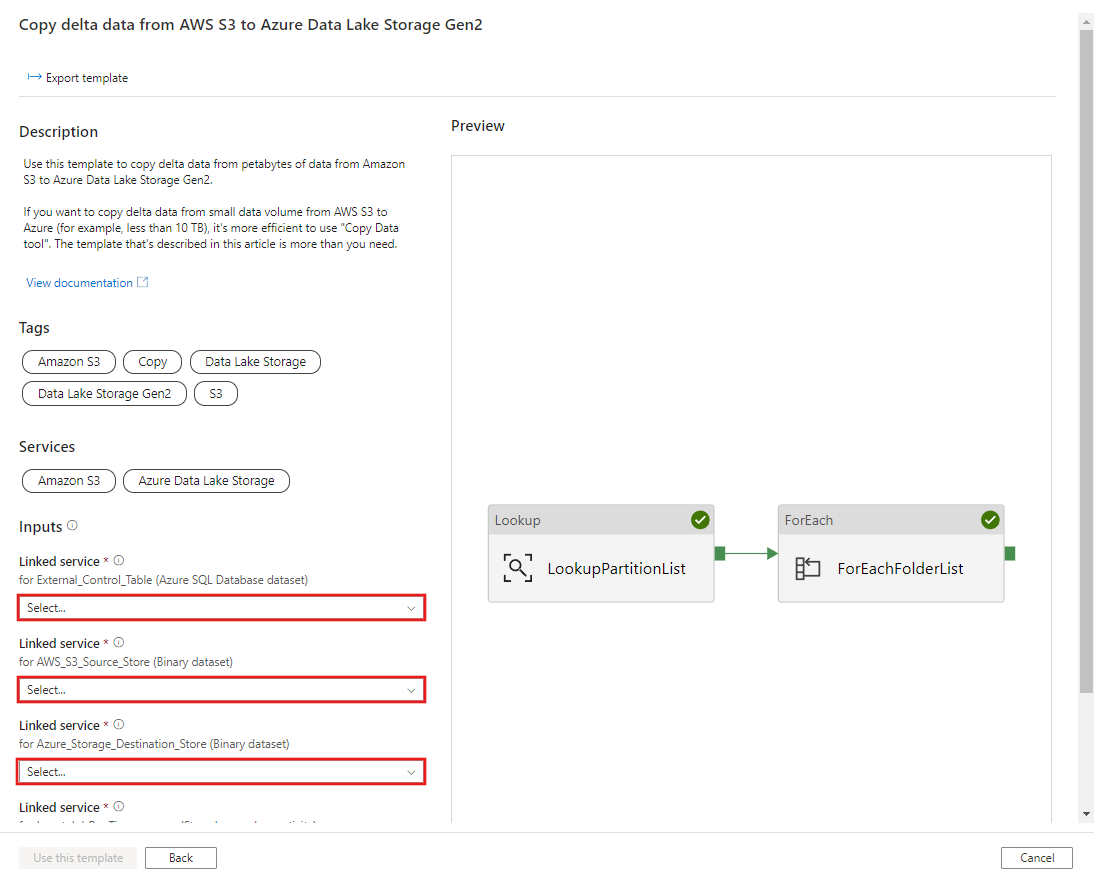
选择“使用此模板” 。
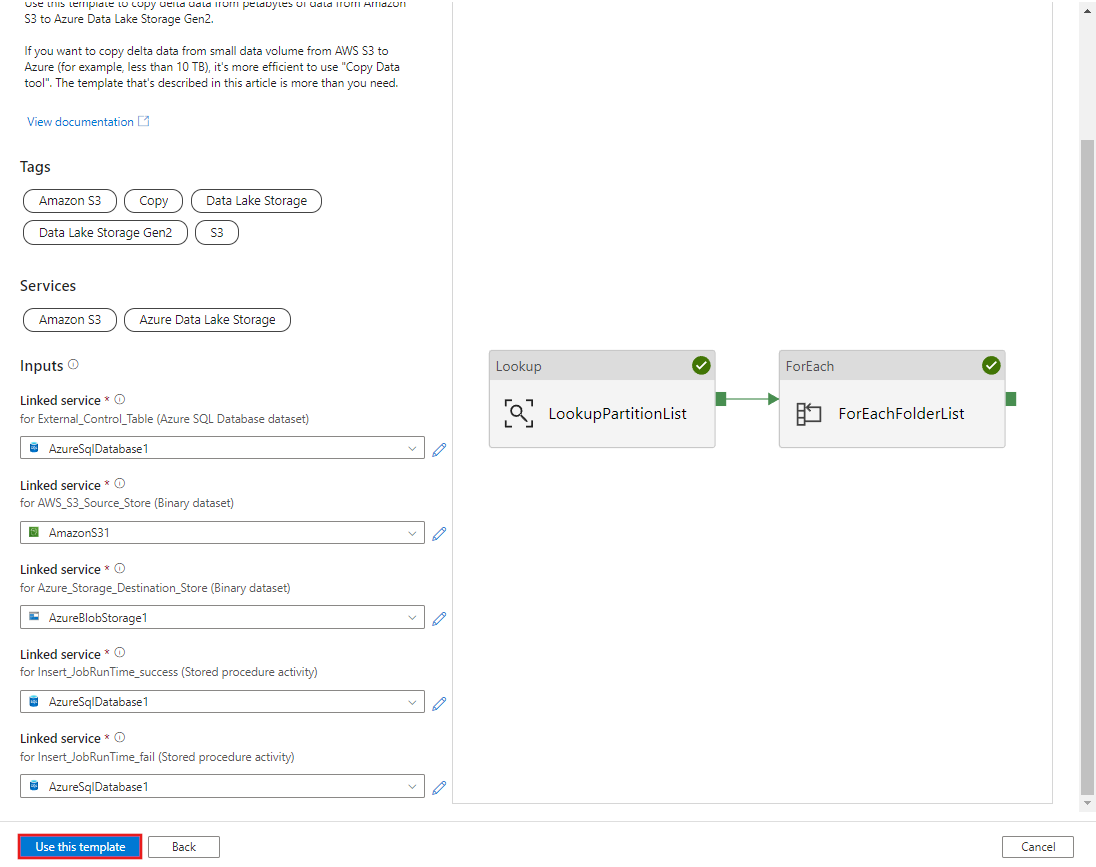
将会看到已创建 2 个管道和 3 个数据集,如以下示例中所示:
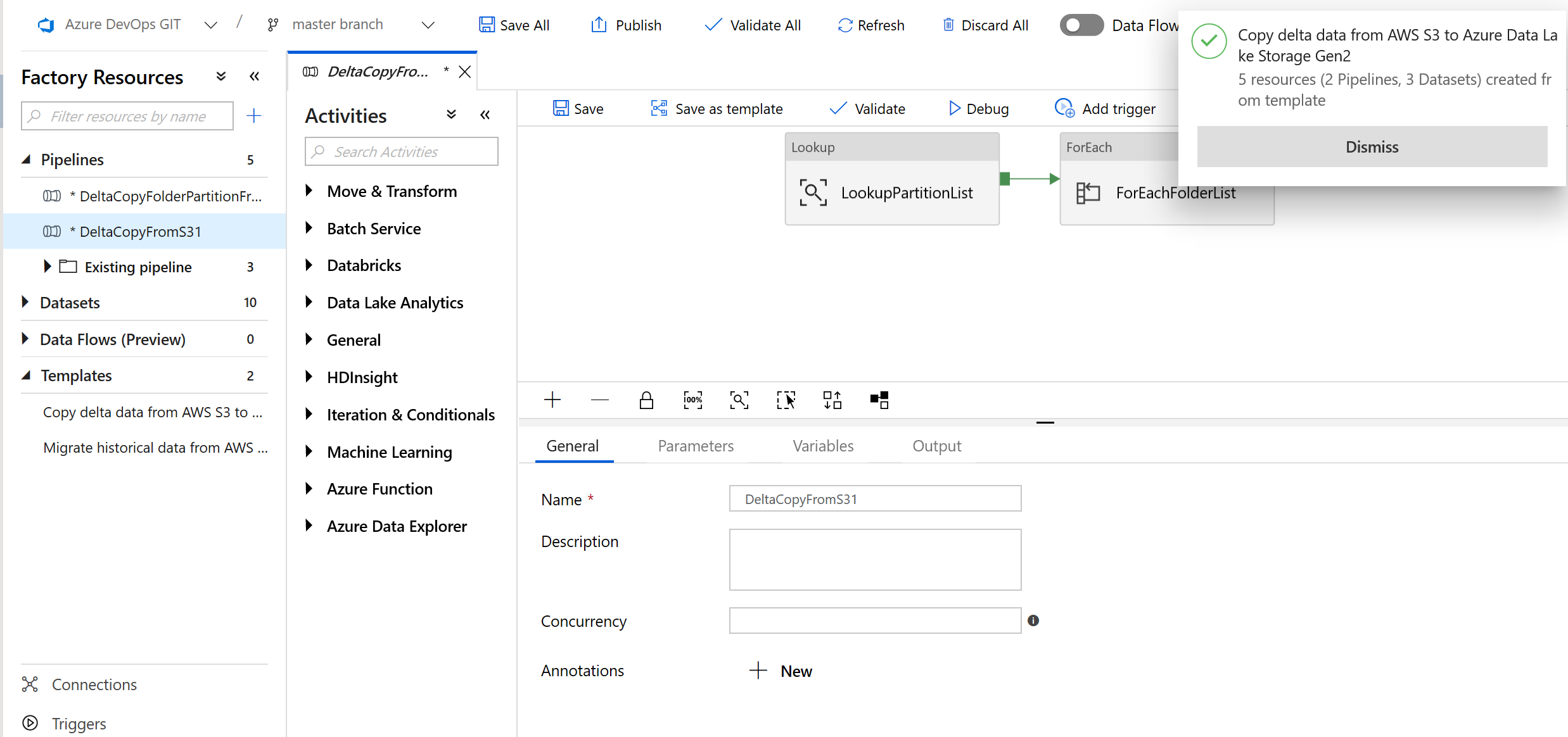
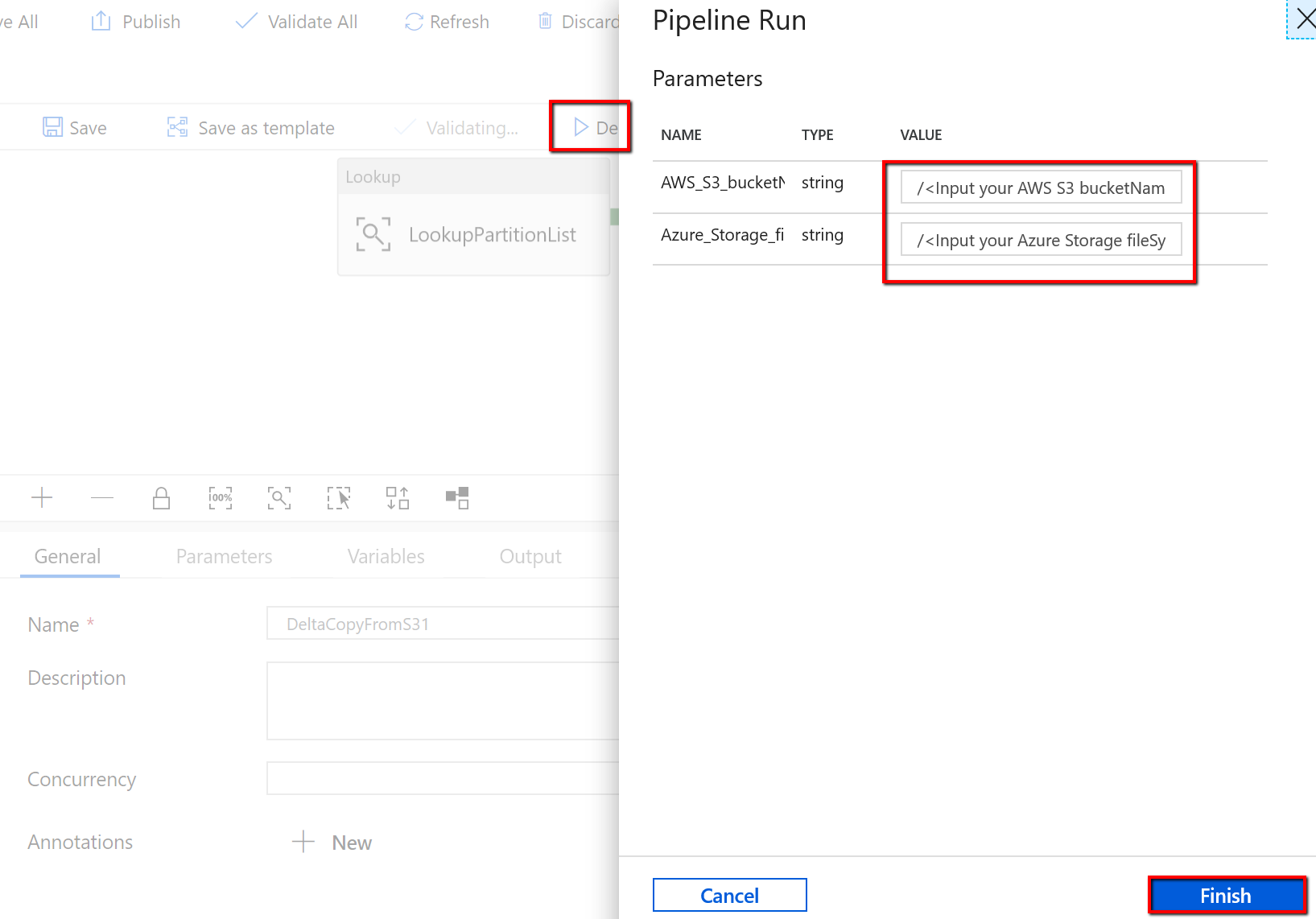
转到“DeltaCopyFromS3”管道,选择“调试”,然后输入“参数” 。 然后选择“完成”。
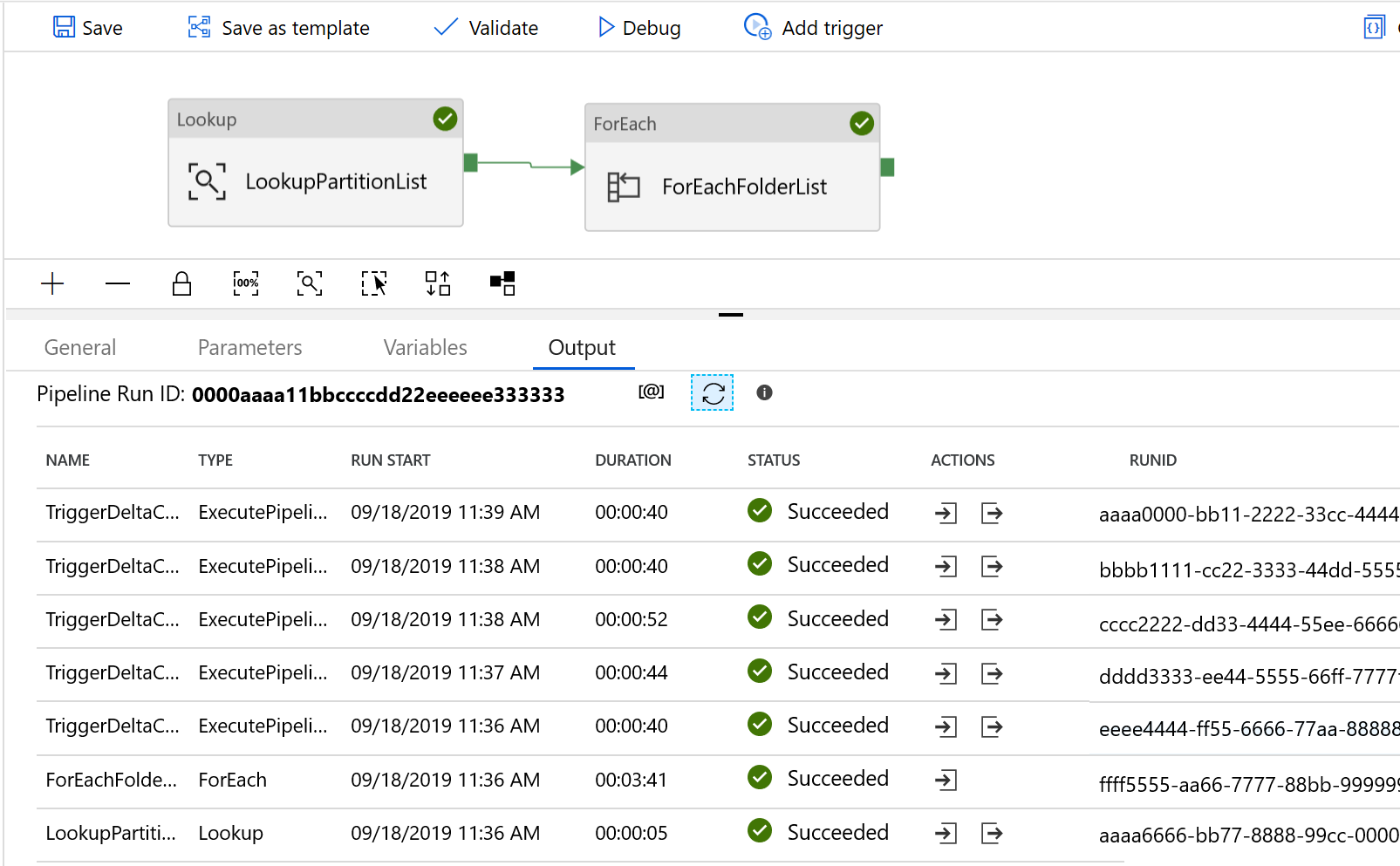
看到的结果类似于以下示例:
还可以通过查询 “select * from s3_partition_delta_control_table”来检查控件表中的结果,将看到类似于以下示例的输出: