Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
在本教程中,您将使用 Azure 门户创建一个 Azure Data Factory 管道,用于在 Databricks 作业群集上运行 Databricks Notebook。 它还在执行期间将Azure Data Factory参数传递给 Databricks 笔记本。
在本教程中执行以下步骤:
创建数据工厂。
创建使用 Databricks Notebook 活动的管道。
触发管道运行。
监视管道运行。
如果没有Azure订阅,请在开始前创建一个 trial 帐户。
注释
有关如何使用 Databricks Notebook 活动(包括使用库和传递输入和输出参数)的完整详细信息,请参阅 Databricks Notebook 活动文档。
先决条件
- Azure Databricks workspace。 创建 Databricks 工作区或使用现有的 Databricks 工作区。 在Azure Databricks工作区中创建Python笔记本。 然后,使用Azure Data Factory执行笔记本并向其传递参数。
创建数据工厂
启动 Microsoft Edge 或 Google Chrome Web 浏览器。 目前,数据工厂 UI 仅在 Microsoft Edge 和 Google Chrome Web 浏览器中受支持。
在Azure门户菜单中选择创建资源,然后选择Analytics>Data Factory:
在创建数据工厂页的基本信息选项卡上,选择要在其中创建数据工厂的 Azure 订阅。
对于“资源组”,请执行以下步骤之一:
从下拉列表中选择现有资源组。
选择“新建”,并输入新资源组的名称。
若要了解资源组,请参阅 使用资源组来管理Azure资源。
对于“区域”,选择数据工厂所在的位置。
该列表仅显示数据工厂支持的位置,以及存储Azure Data Factory元数据的位置。 数据工厂使用的关联数据存储(如Azure Storage和Azure SQL Database)和计算(如Azure HDInsight)可以在其他区域中运行。
对于“名称”,输入“ADFTutorialDataFactory”。
Azure数据工厂的名称必须全球唯一。 如果出现以下错误,请更改数据工厂的名称(例如,使用 <yourname>ADFTutorialDataFactory)。 有关数据工厂项目的命名规则,请参阅数据工厂 - 命名规则一文。
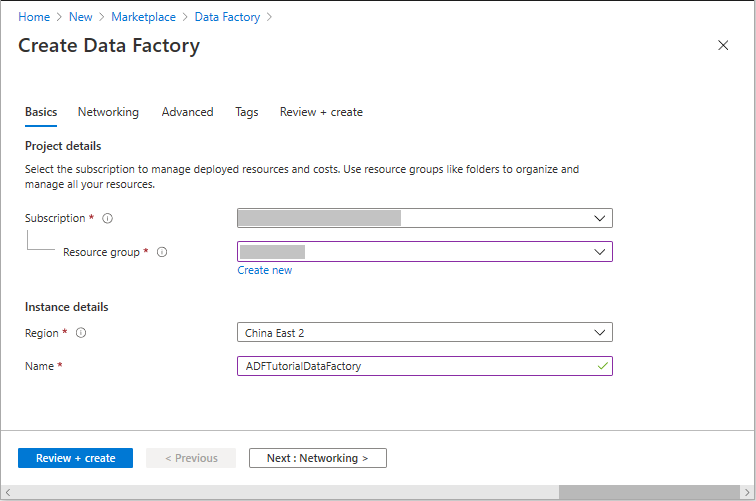
选择“查看 + 创建”,然后在通过验证后选择“创建” 。
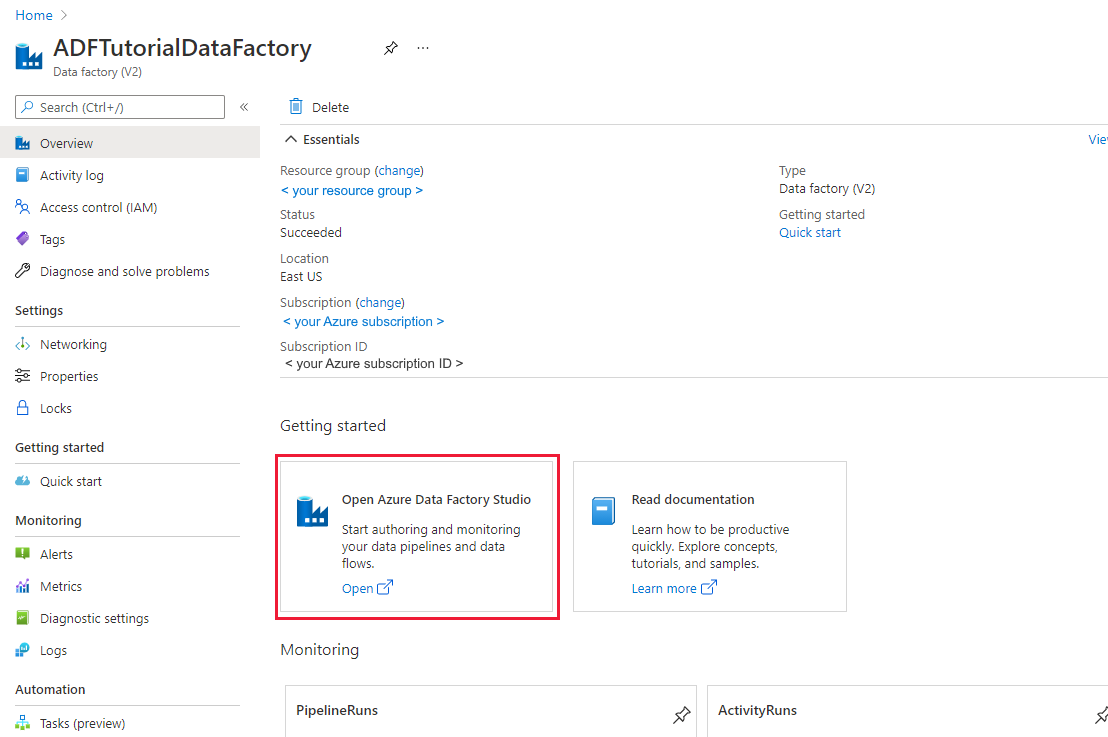
创建完成后,选择“转到资源”,以导航到“数据工厂”页面。 选择 Open Azure Data Factory Studio 磁贴,在单独的浏览器选项卡上启动Azure Data Factory用户界面(UI)应用程序。
创建链接服务
在本部分,请创建 Databricks 链接服务。 此链接服务包含 Databricks 群集的连接信息:
创建Azure Databricks链接服务
在主页上,切换到左侧面板中的“管理”选项卡。
在“连接”下选择“链接服务”,然后选择“+ 新建” 。

在新链接服务窗口中,选择Compute>Azure Databricks,然后选择Continue。

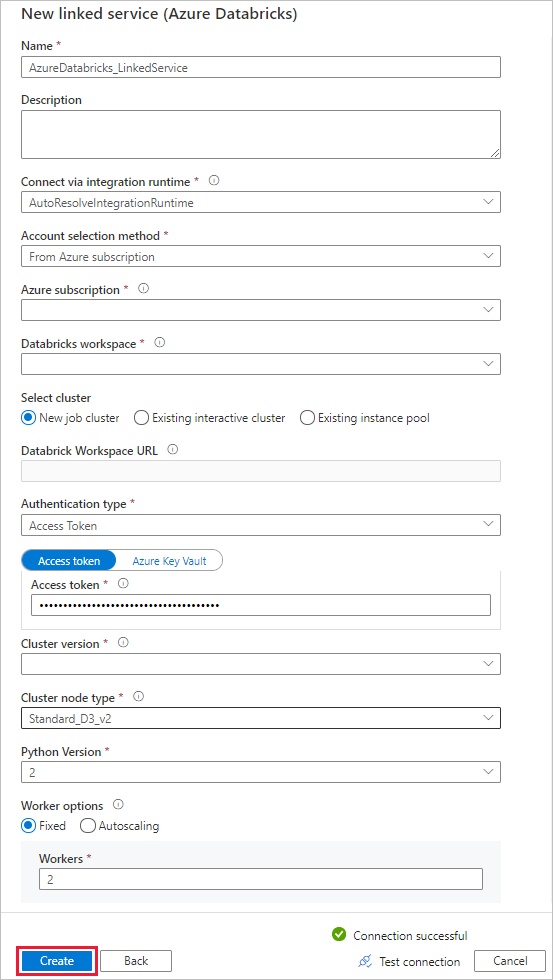
在“新建链接服务”窗口中完成以下步骤:
对于名称,请输入AzureDatabricks_LinkedService。
选择相应的Databricks 工作区以运行你的笔记本。
对于选择群集,请选择新建作业群集。
对于“Databricks 工作区 URL”,应自动填充信息。
对于 身份验证类型,如果选择 访问令牌,请在 Azure Databricks 工作区生成该令牌。 可以在此处找到步骤。 对于托管服务标识和用户分配的托管标识,在 Azure Databricks 资源的访问控制菜单中,将贡献者角色授予这两个标识。
对于“群集版本”,选择要使用的版本。
对于“群集节点类型” ,请在本教程的“常规用途(HDD)” 类别下选择“StandardD3v2” 。
对于“辅助角色”,输入 2。
选择“创建”。
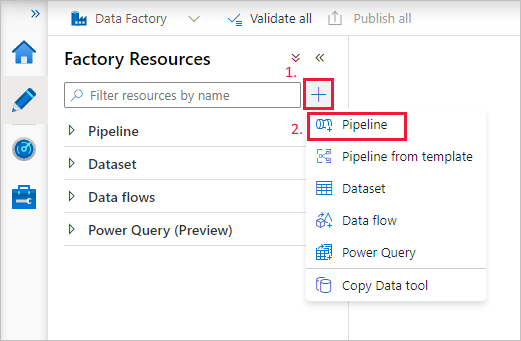
创建管道
选择“ (加号)”按钮,然后在菜单上选择“管道”+。
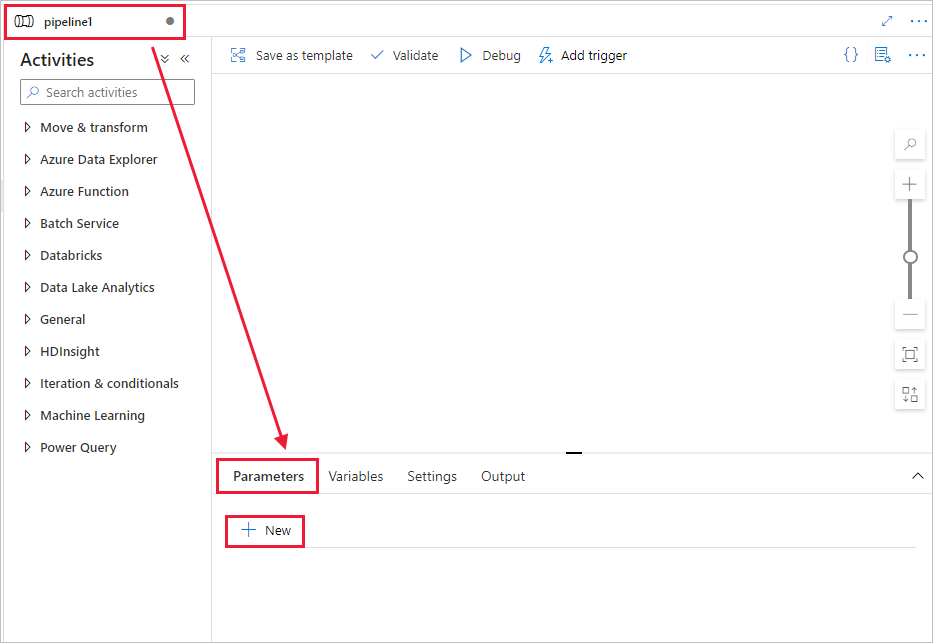
创建在管道中使用的参数。 稍后请将此参数传递给 Databricks Notebook 活动。 在空管道中选择“参数”选项卡,然后选择“+ 新建”并将其命名为“name”。
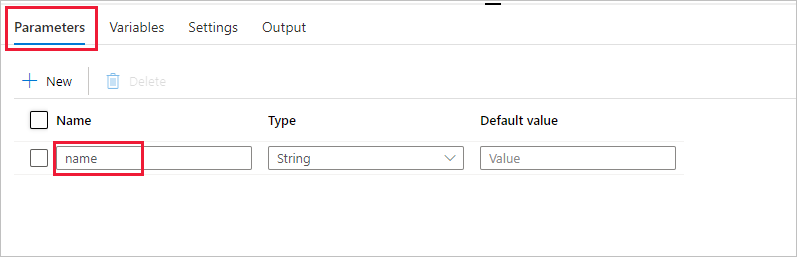
在“活动”工具箱中,展开“Databricks”。 将“Notebook”活动从“活动”工具箱拖到管道设计器图面。
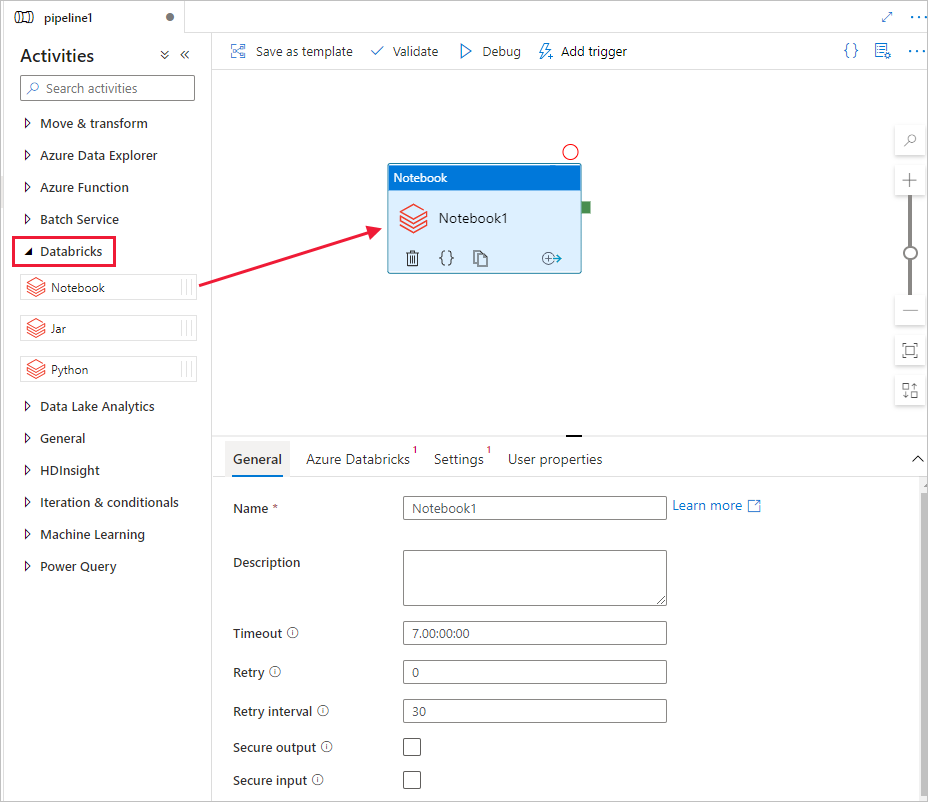
在底部 DatabricksNotebook 活动窗口的属性中完成以下步骤:
切换到 Azure Databricks 选项卡。
选择 AzureDatabricks_LinkedService(您在之前的步骤中创建的服务)。
切换到“设置”选项卡。
浏览以选择 Databricks Notebook 路径。 让我们创建一个笔记本并在此处指定路径。 你可以通过以下步骤获取到 Notebook 路径。
启动Azure Databricks工作区。
在工作区中创建新文件夹,将其称之为 adftutorial。
创建新的笔记本,让我们将其称为 mynotebook。 右键单击“adftutorial”文件夹,然后选择“创建”。
在新创建的 Notebook“mynotebook”中添加以下代码:
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)在此示例中,“Notebook 路径”为 /adftutorial/mynotebook 。
切换回“数据工厂 UI 创作工具”。 导航到“Notebook1”活动下的“设置”选项卡 。
a。 向 Notebook 活动添加参数。 使用的参数与此前添加到“管道”的参数相同。
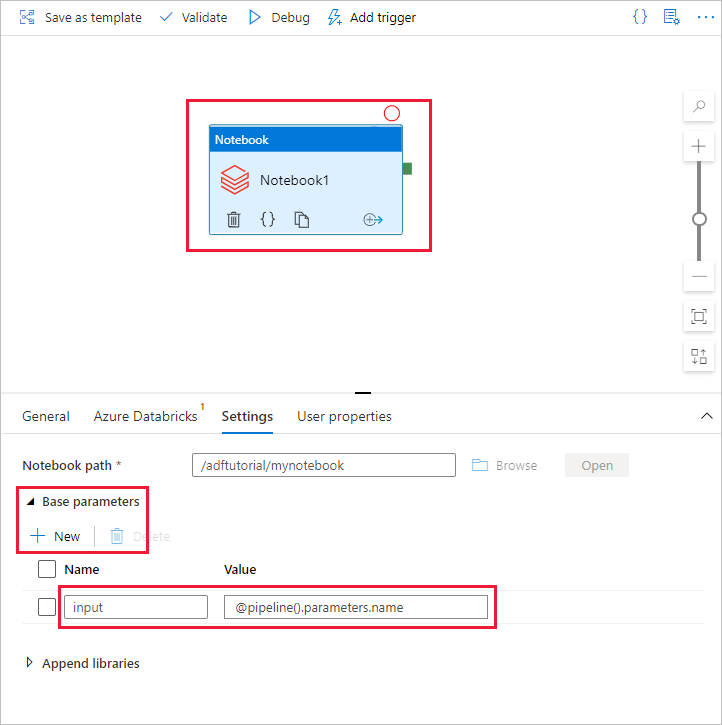
b. 将参数命名为 input,并以 @pipeline().parameters.name 表达式的形式提供值。
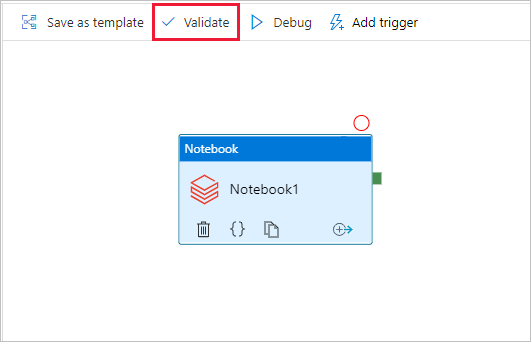
若要验证管道,请选择工具栏中的“验证”按钮。 若要关闭验证窗口,请选择“关闭”按钮。
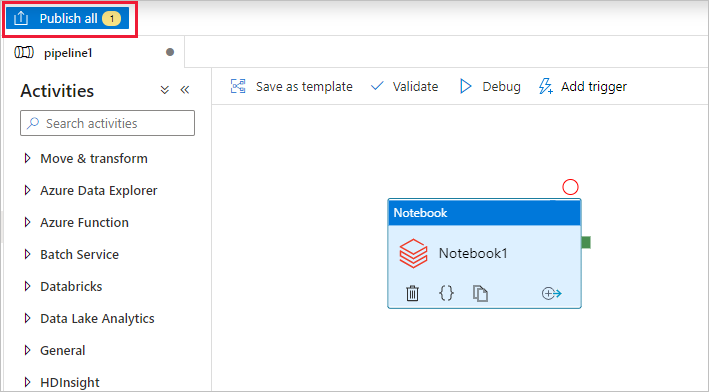
选择“全部发布”。 数据工厂 UI 将实体(链接服务和管道)发布到Azure Data Factory服务。
触发管道运行
选择工具栏中的“添加触发器”,然后选择“立即触发” 。
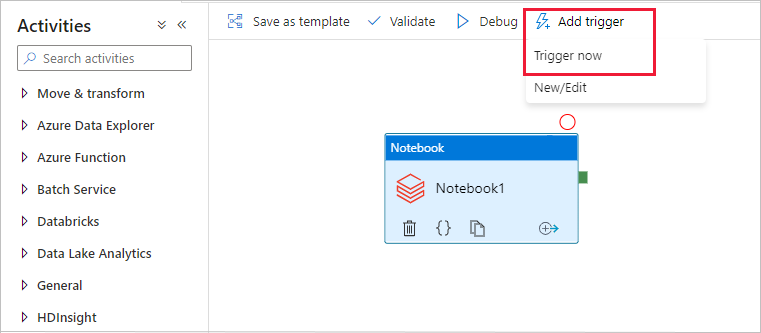
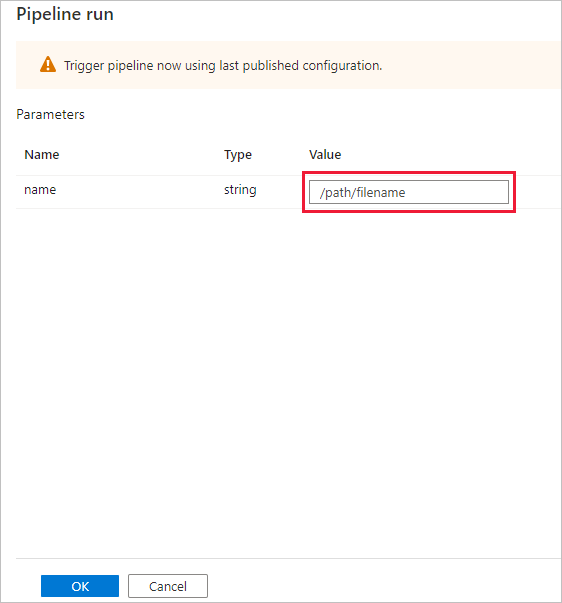
“管道运行”对话框要求提供 name 参数。 使用 /path/filename 作为此处的参数。 选择“确定”。
监视管道运行
切换到“监视”选项卡。确认可以看到一个管道运行。 创建执行 Notebook 所在的 Databricks 作业群集需要大约 5-8 分钟。
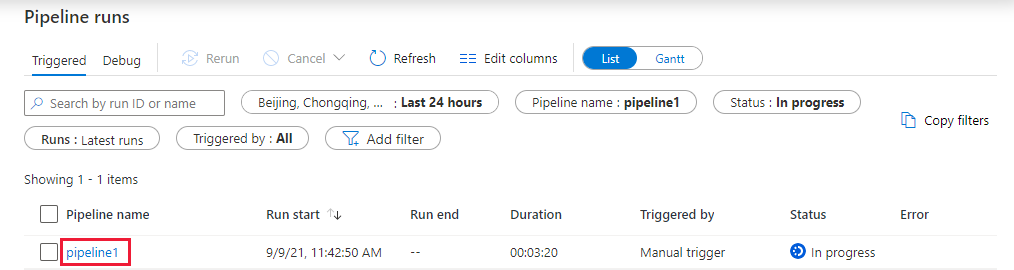
定期选择“刷新”以检查管道运行的状态。
若要查看与管道运行关联的活动运行,请选择“管道名称”列中的“pipeline1”链接。
在“活动运行”页面中,选择“活动名称”列中的“输出”以查看每个活动的输出,可以在“输出”窗格中找到“Databricks 日志”的链接,获取更详细的 Spark 日志 。
可以通过选择顶部痕迹导航菜单中的“所有管道运行”链接,切换回管道运行视图。
验证输出
可以登录到 Azure Databricks 工作区, 转到 Job Runs,可以看到 Job 状态为 pend execution、running 或 terminated。
可以选择“作业名称”,然后通过导航来查看更多详细信息。 成功运行时,可以验证传递的参数和Python笔记本的输出。
摘要
本示例中的管道先触发 Databricks Notebook 活动,然后向其传递参数。 你已了解如何执行以下操作:
创建数据工厂。
创建可使用 Databricks Notebook 活动的管道。
触发管道运行。
监视管道运行。